 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLyrically Speaking: Exploring the Link Between Lyrical Emotions, Themes and Depression Risk
Aug 28, 2024



Lyrics play a crucial role in affecting and reinforcing emotional states by providing meaning and emotional connotations that interact with the acoustic properties of the music. Specific lyrical themes and emotions may intensify existing negative states in listeners and may lead to undesirable outcomes, especially in listeners with mood disorders such as depression. Hence, it is important for such individuals to be mindful of their listening strategies. In this study, we examine online music consumption of individuals at risk of depression in light of lyrical themes and emotions. Lyrics obtained from the listening histories of 541 Last.fm users, divided into At-Risk and No-Risk based on their mental well-being scores, were analyzed using natural language processing techniques. Statistical analyses of the results revealed that individuals at risk for depression prefer songs with lyrics associated with low valence and low arousal. Additionally, lyrics associated with themes of denial, self-reference, and ambivalence were preferred. In contrast, themes such as liberation, familiarity, and activity are not as favored. This study opens up the possibility of an approach to assessing depression risk from the digital footprint of individuals and potentially developing personalized recommendation systems.
Tollywood Emotions: Annotation of Valence-Arousal in Telugu Song Lyrics
Mar 16, 2023



Emotion recognition from a given music track has heavily relied on acoustic features, social tags, and metadata but is seldom focused on lyrics. There are no datasets of Indian language songs that contain both valence and arousal manual ratings of lyrics. We present a new manually annotated dataset of Telugu songs' lyrics collected from Spotify with valence and arousal annotated on a discrete scale. A fairly high inter-annotator agreement was observed for both valence and arousal. Subsequently, we create two music emotion recognition models by using two classification techniques to identify valence, arousal and respective emotion quadrant from lyrics. Support vector machine (SVM) with term frequency-inverse document frequency (TF-IDF) features and fine-tuning the pre-trained XLMRoBERTa (XLM-R) model were used for valence, arousal and quadrant classification tasks. Fine-tuned XLMRoBERTa performs better than the SVM by improving macro-averaged F1-scores of 54.69%, 67.61%, 34.13% to 77.90%, 80.71% and 58.33% for valence, arousal and quadrant classifications, respectively, on 10-fold cross-validation. In addition, we compare our lyrics annotations with Spotify's annotations of valence and energy (same as arousal), which are based on entire music tracks. The implications of our findings are discussed. Finally, we make the dataset publicly available with lyrics, annotations and Spotify IDs.
Sonus Texere! Automated Dense Soundtrack Construction for Books using Movie Adaptations
Dec 02, 2022Reading, much like music listening, is an immersive experience that transports readers while taking them on an emotional journey. Listening to complementary music has the potential to amplify the reading experience, especially when the music is stylistically cohesive and emotionally relevant. In this paper, we propose the first fully automatic method to build a dense soundtrack for books, which can play high-quality instrumental music for the entirety of the reading duration. Our work employs a unique text processing and music weaving pipeline that determines the context and emotional composition of scenes in a chapter. This allows our method to identify and play relevant excerpts from the soundtrack of the book's movie adaptation. By relying on the movie composer's craftsmanship, our book soundtracks include expert-made motifs and other scene-specific musical characteristics. We validate the design decisions of our approach through a perceptual study. Our readers note that the book soundtrack greatly enhanced their reading experience, due to high immersiveness granted via uninterrupted and style-consistent music, and a heightened emotional state attained via high precision emotion and scene context recognition.
Multimodal Fusion Based Attentive Networks for Sequential Music Recommendation
Oct 03, 2021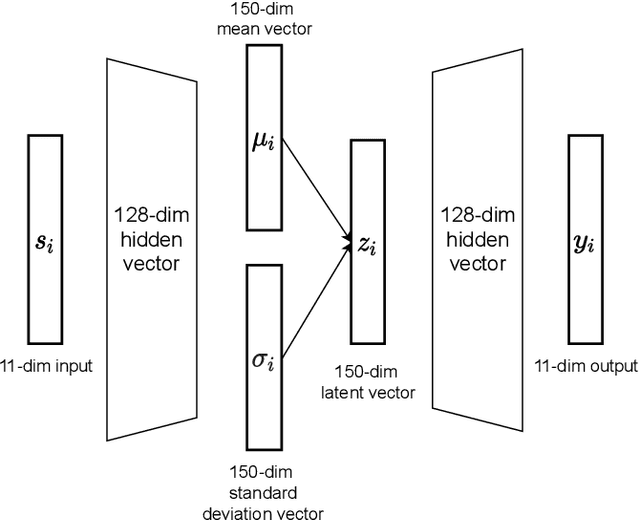
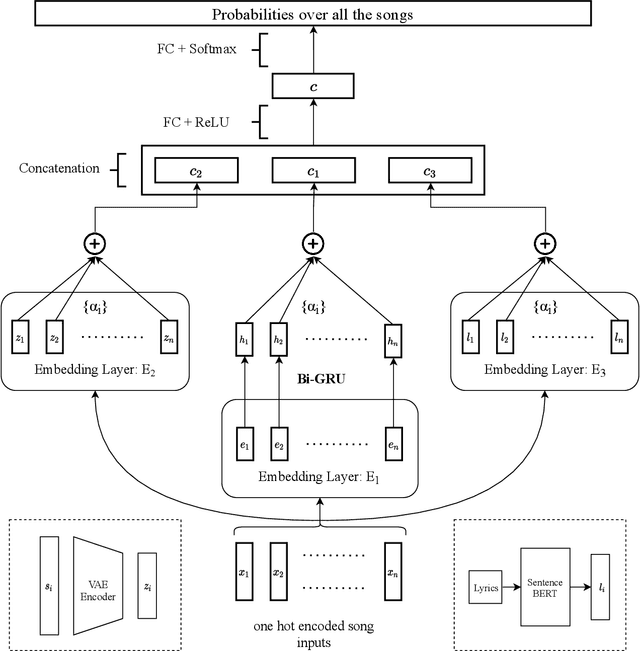

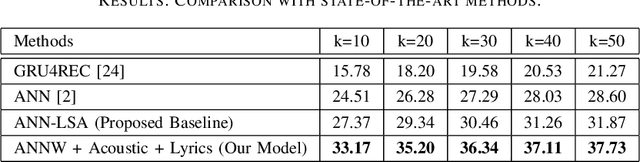
Music has the power to evoke intense emotional experiences and regulate the mood of an individual. With the advent of online streaming services, research in music recommendation services has seen tremendous progress. Modern methods leveraging the listening histories of users for session-based song recommendations have overlooked the significance of features extracted from lyrics and acoustic content. We address the task of song prediction through multiple modalities, including tags, lyrics, and acoustic content. In this paper, we propose a novel deep learning approach by refining Attentive Neural Networks using representations derived via a Transformer model for lyrics and Variational Autoencoder for acoustic features. Our model achieves significant improvement in performance over existing state-of-the-art models using lyrical and acoustic features alone. Furthermore, we conduct a study to investigate the impact of users' psychological health on our model's performance.
How Much do Lyrics Matter? Analysing Lyrical Simplicity Preferences for Individuals At Risk of Depression
Sep 15, 2021

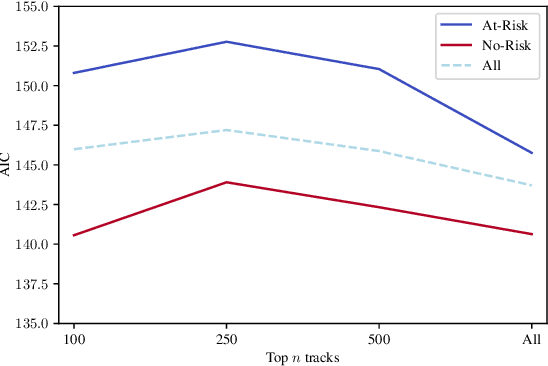
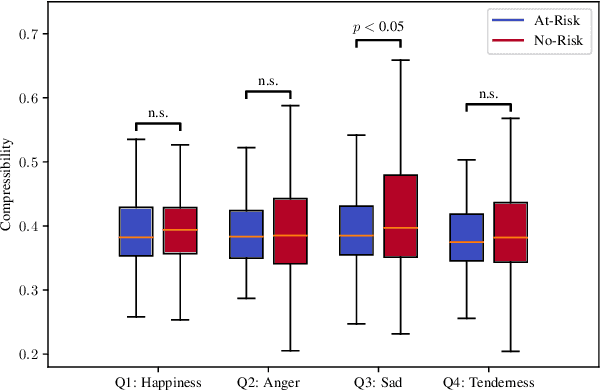
Music affects and in some cases reflects one's emotional state. Key to this influence is lyrics and their meaning in conjunction with the acoustic properties of the track. Recent work has focused on analysing these acoustic properties and showing that individuals prone to depression primarily consume low valence and low energy music. However, no studies yet have explored lyrical content preferences in relation to online music consumption of such individuals. In the current study, we examine lyrical simplicity, measured as the Compressibility and Absolute Information Content of the text, associated with preferences of individuals at risk for depression. Using the six-month listening history of 541 Last.fm users, we compare lyrical simplicity trends for users grouped as being at risk (At-Risk) of depression from those that are not (No-Risk). Our findings reveal that At-Risk individuals prefer songs with greater information content (lower Compressibility) on average, especially for songs characterised as Sad. Furthermore, we found that At-Risk individuals also have greater variability of Absolute Information Content across their listening history. We discuss the results in light of existing socio-psychological lab-based research on music habits associated with depression and their relevance to naturally occurring online music listening behaviour.
Transformer-based approach towards music emotion recognition from lyrics
Jan 06, 2021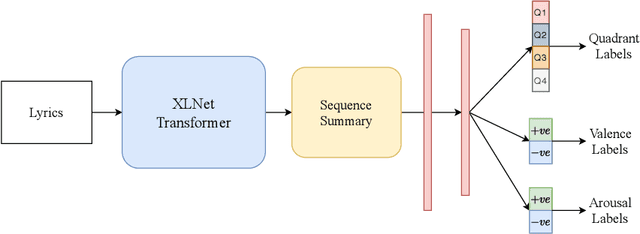

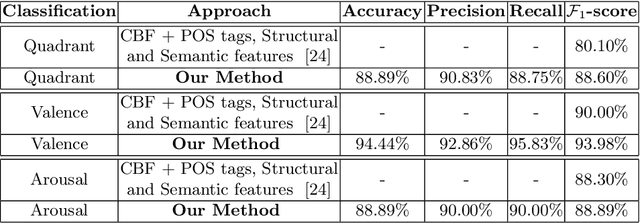
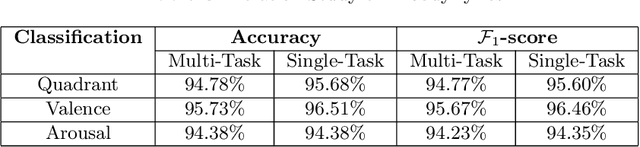
The task of identifying emotions from a given music track has been an active pursuit in the Music Information Retrieval (MIR) community for years. Music emotion recognition has typically relied on acoustic features, social tags, and other metadata to identify and classify music emotions. The role of lyrics in music emotion recognition remains under-appreciated in spite of several studies reporting superior performance of music emotion classifiers based on features extracted from lyrics. In this study, we use the transformer-based approach model using XLNet as the base architecture which, till date, has not been used to identify emotional connotations of music based on lyrics. Our proposed approach outperforms existing methods for multiple datasets. We used a robust methodology to enhance web-crawlers' accuracy for extracting lyrics. This study has important implications in improving applications involved in playlist generation of music based on emotions in addition to improving music recommendation systems.
Towards Multimodal MIR: Predicting individual differences from music-induced movement
Jul 21, 2020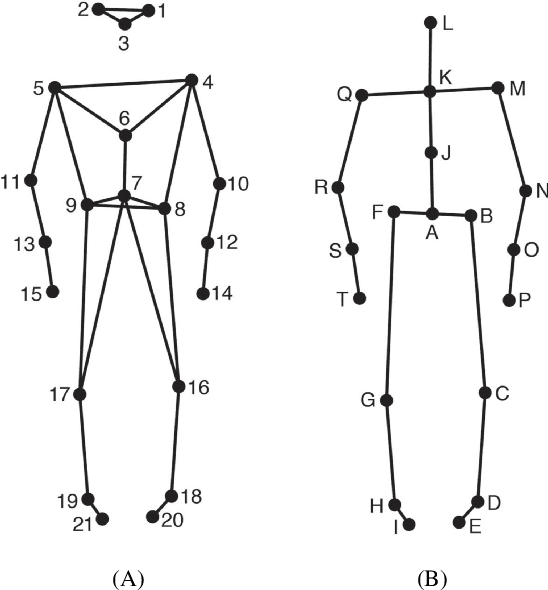
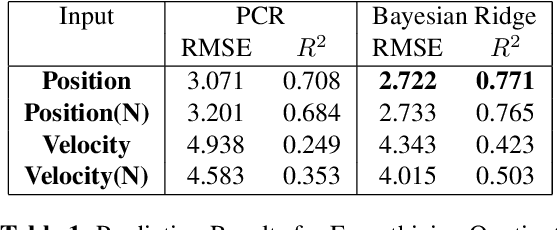
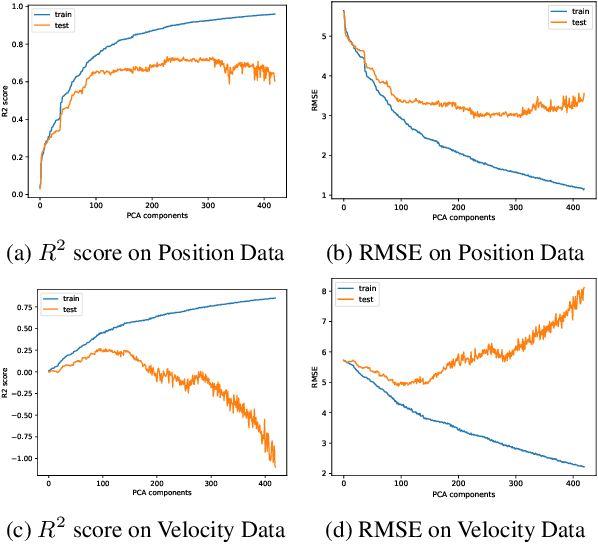
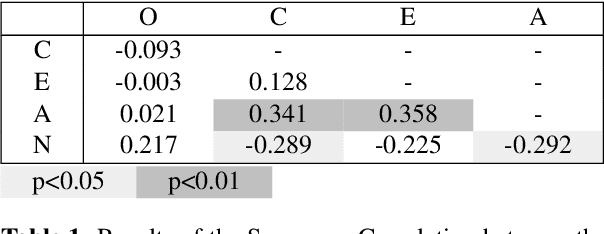
As the field of Music Information Retrieval grows, it is important to take into consideration the multi-modality of music and how aspects of musical engagement such as movement and gesture might be taken into account. Bodily movement is universally associated with music and reflective of important individual features related to music preference such as personality, mood, and empathy. Future multimodal MIR systems may benefit from taking these aspects into account. The current study addresses this by identifying individual differences, specifically Big Five personality traits, and scores on the Empathy and Systemizing Quotients (EQ/SQ) from participants' free dance movements. Our model successfully explored the unseen space for personality as well as EQ, SQ, which has not previously been accomplished for the latter. R2 scores for personality, EQ, and SQ were 76.3%, 77.1%, and 86.7% respectively. As a follow-up, we investigated which bodily joints were most important in defining these traits. We discuss how further research may explore how the mapping of these traits to movement patterns can be used to build a more personalized, multi-modal recommendation system, as well as potential therapeutic applications.
Diffusion map for clustering fMRI spatial maps extracted by independent component analysis
Sep 27, 2013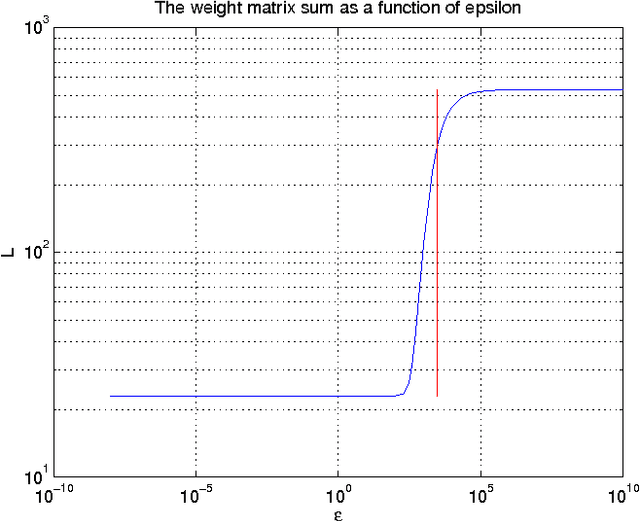

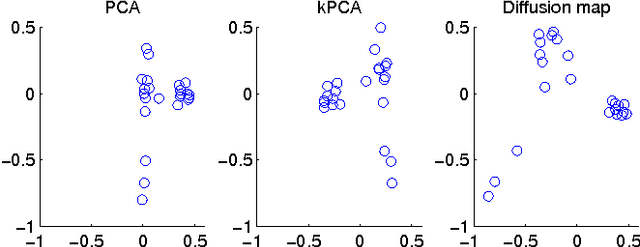

Functional magnetic resonance imaging (fMRI) produces data about activity inside the brain, from which spatial maps can be extracted by independent component analysis (ICA). In datasets, there are n spatial maps that contain p voxels. The number of voxels is very high compared to the number of analyzed spatial maps. Clustering of the spatial maps is usually based on correlation matrices. This usually works well, although such a similarity matrix inherently can explain only a certain amount of the total variance contained in the high-dimensional data where n is relatively small but p is large. For high-dimensional space, it is reasonable to perform dimensionality reduction before clustering. In this research, we used the recently developed diffusion map for dimensionality reduction in conjunction with spectral clustering. This research revealed that the diffusion map based clustering worked as well as the more traditional methods, and produced more compact clusters when needed.