 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLyrically Speaking: Exploring the Link Between Lyrical Emotions, Themes and Depression Risk
Aug 28, 2024



Lyrics play a crucial role in affecting and reinforcing emotional states by providing meaning and emotional connotations that interact with the acoustic properties of the music. Specific lyrical themes and emotions may intensify existing negative states in listeners and may lead to undesirable outcomes, especially in listeners with mood disorders such as depression. Hence, it is important for such individuals to be mindful of their listening strategies. In this study, we examine online music consumption of individuals at risk of depression in light of lyrical themes and emotions. Lyrics obtained from the listening histories of 541 Last.fm users, divided into At-Risk and No-Risk based on their mental well-being scores, were analyzed using natural language processing techniques. Statistical analyses of the results revealed that individuals at risk for depression prefer songs with lyrics associated with low valence and low arousal. Additionally, lyrics associated with themes of denial, self-reference, and ambivalence were preferred. In contrast, themes such as liberation, familiarity, and activity are not as favored. This study opens up the possibility of an approach to assessing depression risk from the digital footprint of individuals and potentially developing personalized recommendation systems.
Acrostic Poem Generation
Oct 05, 2020
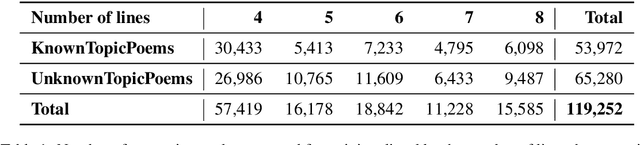
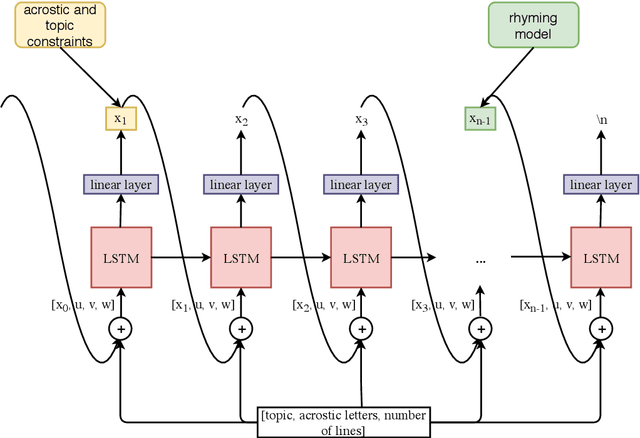
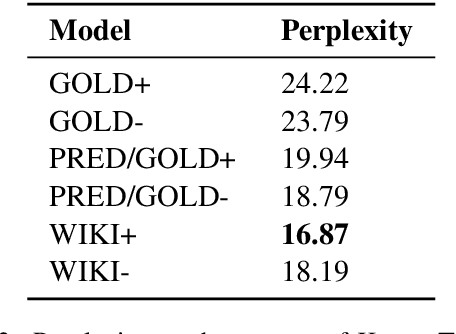
We propose a new task in the area of computational creativity: acrostic poem generation in English. Acrostic poems are poems that contain a hidden message; typically, the first letter of each line spells out a word or short phrase. We define the task as a generation task with multiple constraints: given an input word, 1) the initial letters of each line should spell out the provided word, 2) the poem's semantics should also relate to it, and 3) the poem should conform to a rhyming scheme. We further provide a baseline model for the task, which consists of a conditional neural language model in combination with a neural rhyming model. Since no dedicated datasets for acrostic poem generation exist, we create training data for our task by first training a separate topic prediction model on a small set of topic-annotated poems and then predicting topics for additional poems. Our experiments show that the acrostic poems generated by our baseline are received well by humans and do not lose much quality due to the additional constraints. Last, we confirm that poems generated by our model are indeed closely related to the provided prompts, and that pretraining on Wikipedia can boost performance.
Dynamics-aware Embeddings
Sep 01, 2019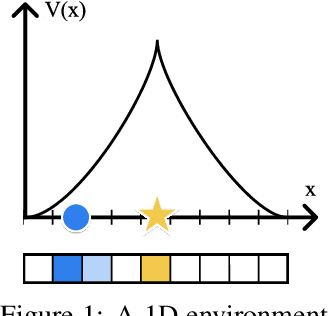
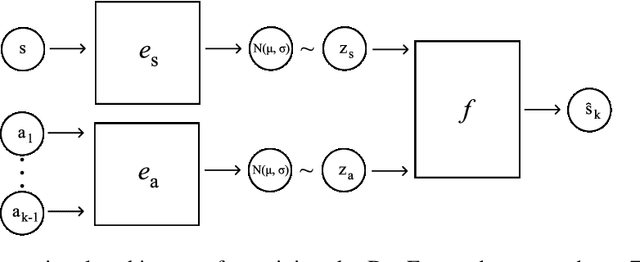
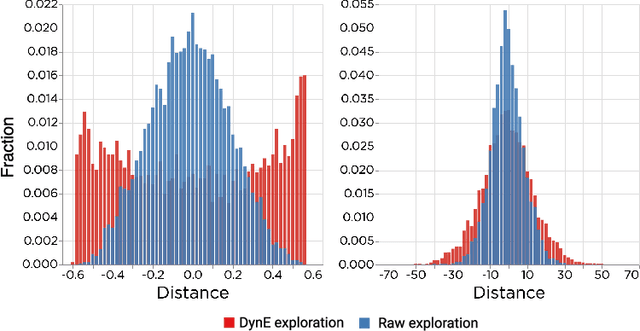
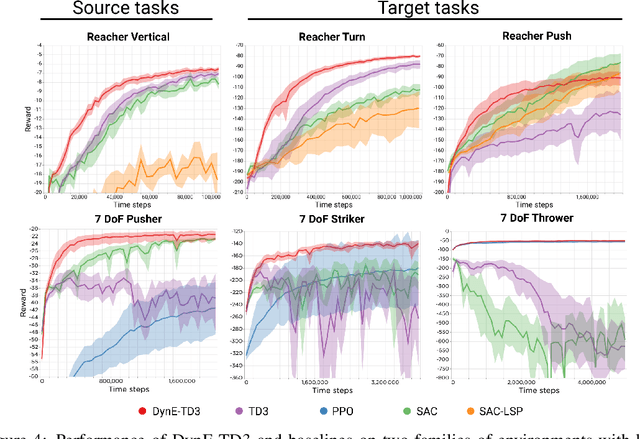
In this paper we consider self-supervised representation learning to improve sample efficiency in reinforcement learning (RL). We propose a forward prediction objective for simultaneously learning embeddings of states and actions. These embeddings capture the structure of the environment's dynamics, enabling efficient policy learning. We demonstrate that our action embeddings alone improve the sample efficiency and peak performance of model-free RL on control from low-dimensional states. By combining state and action embeddings, we achieve efficient learning of high-quality policies on goal-conditioned continuous control from pixel observations in only 1-2 million environment steps.