 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXWikiGen: Cross-lingual Summarization for Encyclopedic Text Generation in Low Resource Languages
Mar 22, 2023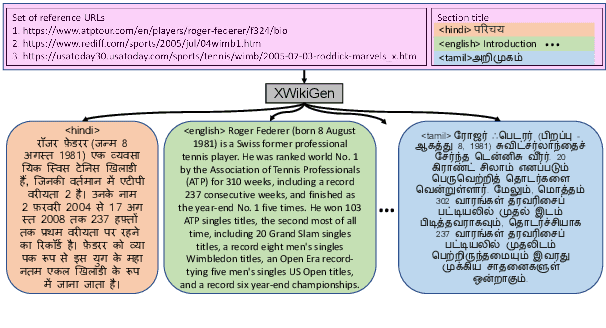

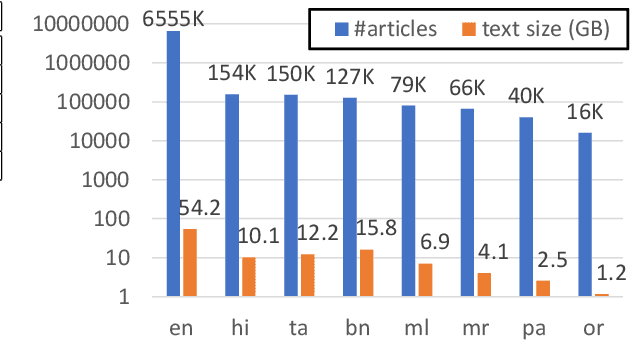

Lack of encyclopedic text contributors, especially on Wikipedia, makes automated text generation for \emph{low resource (LR) languages} a critical problem. Existing work on Wikipedia text generation has focused on \emph{English only} where English reference articles are summarized to generate English Wikipedia pages. But, for low-resource languages, the scarcity of reference articles makes monolingual summarization ineffective in solving this problem. Hence, in this work, we propose \task{}, which is the task of cross-lingual multi-document summarization of text from multiple reference articles, written in various languages, to generate Wikipedia-style text. Accordingly, we contribute a benchmark dataset, \data{}, spanning $\sim$69K Wikipedia articles covering five domains and eight languages. We harness this dataset to train a two-stage system where the input is a set of citations and a section title and the output is a section-specific LR summary. The proposed system is based on a novel idea of neural unsupervised extractive summarization to coarsely identify salient information followed by a neural abstractive model to generate the section-specific text. Extensive experiments show that multi-domain training is better than the multi-lingual setup on average.