Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarizing Indian Languages using Multilingual Transformers based Models
Paper and Code


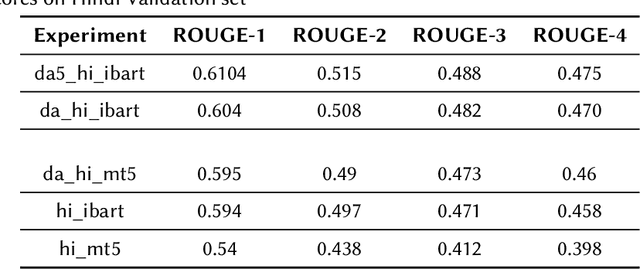

With the advent of multilingual models like mBART, mT5, IndicBART etc., summarization in low resource Indian languages is getting a lot of attention now a days. But still the number of datasets is low in number. In this work, we (Team HakunaMatata) study how these multilingual models perform on the datasets which have Indian languages as source and target text while performing summarization. We experimented with IndicBART and mT5 models to perform the experiments and report the ROUGE-1, ROUGE-2, ROUGE-3 and ROUGE-4 scores as a performance metric.
* Forum for Information Retrieval Evaluation, December 9-13, 2022,
India
View paper on