 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Group Love, Out-Group Hate: A Framework to Measure Affective Polarization via Contentious Online Discussions
Dec 18, 2024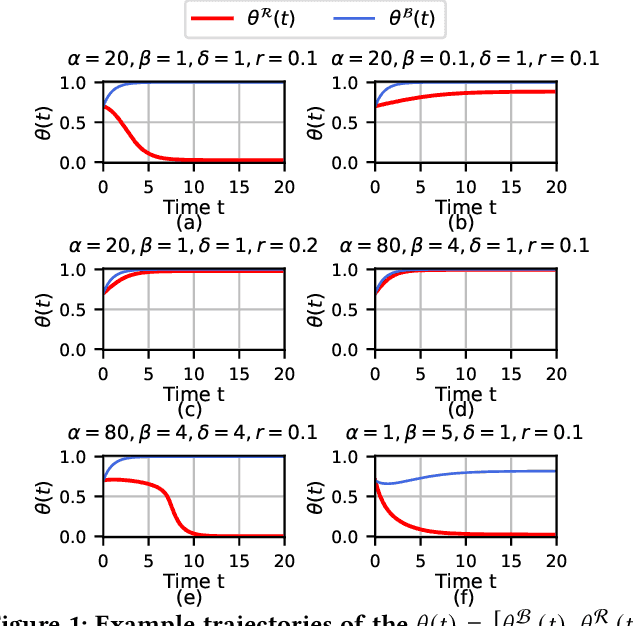
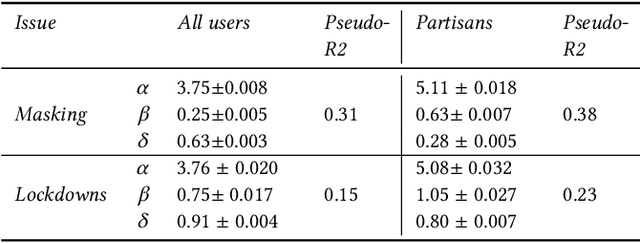
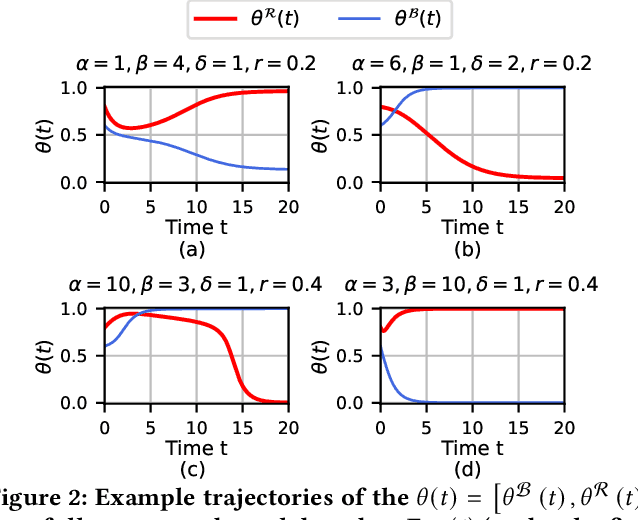
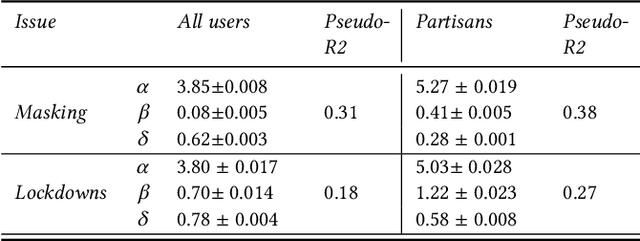
Affective polarization, the emotional divide between ideological groups marked by in-group love and out-group hate, has intensified in the United States, driving contentious issues like masking and lockdowns during the COVID-19 pandemic. Despite its societal impact, existing models of opinion change fail to account for emotional dynamics nor offer methods to quantify affective polarization robustly and in real-time. In this paper, we introduce a discrete choice model that captures decision-making within affectively polarized social networks and propose a statistical inference method estimate key parameters -- in-group love and out-group hate -- from social media data. Through empirical validation from online discussions about the COVID-19 pandemic, we demonstrate that our approach accurately captures real-world polarization dynamics and explains the rapid emergence of a partisan gap in attitudes towards masking and lockdowns. This framework allows for tracking affective polarization across contentious issues has broad implications for fostering constructive online dialogues in digital spaces.
Assessing the Impact of Conspiracy Theories Using Large Language Models
Dec 09, 2024Measuring the relative impact of CTs is important for prioritizing responses and allocating resources effectively, especially during crises. However, assessing the actual impact of CTs on the public poses unique challenges. It requires not only the collection of CT-specific knowledge but also diverse information from social, psychological, and cultural dimensions. Recent advancements in large language models (LLMs) suggest their potential utility in this context, not only due to their extensive knowledge from large training corpora but also because they can be harnessed for complex reasoning. In this work, we develop datasets of popular CTs with human-annotated impacts. Borrowing insights from human impact assessment processes, we then design tailored strategies to leverage LLMs for performing human-like CT impact assessments. Through rigorous experiments, we textit{discover that an impact assessment mode using multi-step reasoning to analyze more CT-related evidence critically produces accurate results; and most LLMs demonstrate strong bias, such as assigning higher impacts to CTs presented earlier in the prompt, while generating less accurate impact assessments for emotionally charged and verbose CTs.
#EpiTwitter: Public Health Messaging During the COVID-19 Pandemic
Jun 04, 2024



Effective communication during health crises is critical, with social media serving as a key platform for public health experts (PHEs) to engage with the public. However, it also amplifies pseudo-experts promoting contrarian views. Despite its importance, the role of emotional and moral language in PHEs' communication during COVID-19 remains under explored. This study examines how PHEs and pseudo-experts communicated on Twitter during the pandemic, focusing on emotional and moral language and their engagement with political elites. Analyzing tweets from 489 PHEs and 356 pseudo-experts from January 2020 to January 2021, alongside public responses, we identified key priorities and differences in messaging strategy. PHEs prioritize masking, healthcare, education, and vaccines, using positive emotional language like optimism. In contrast, pseudo-experts discuss therapeutics and lockdowns more frequently, employing negative emotions like pessimism and disgust. Negative emotional and moral language tends to drive engagement, but positive language from PHEs fosters positivity in public responses. PHEs exhibit liberal partisanship, expressing more positivity towards liberals and negativity towards conservative elites, while pseudo-experts show conservative partisanship. These findings shed light on the polarization of COVID-19 discourse and underscore the importance of strategic use of emotional and moral language by experts to mitigate polarization and enhance public trust.
Don't Blame the Data, Blame the Model: Understanding Noise and Bias When Learning from Subjective Annotations
Mar 06, 2024Researchers have raised awareness about the harms of aggregating labels especially in subjective tasks that naturally contain disagreements among human annotators. In this work we show that models that are only provided aggregated labels show low confidence on high-disagreement data instances. While previous studies consider such instances as mislabeled, we argue that the reason the high-disagreement text instances have been hard-to-learn is that the conventional aggregated models underperform in extracting useful signals from subjective tasks. Inspired by recent studies demonstrating the effectiveness of learning from raw annotations, we investigate classifying using Multiple Ground Truth (Multi-GT) approaches. Our experiments show an improvement of confidence for the high-disagreement instances.
Whose Emotions and Moral Sentiments Do Language Models Reflect?
Feb 16, 2024Language models (LMs) are known to represent the perspectives of some social groups better than others, which may impact their performance, especially on subjective tasks such as content moderation and hate speech detection. To explore how LMs represent different perspectives, existing research focused on positional alignment, i.e., how closely the models mimic the opinions and stances of different groups, e.g., liberals or conservatives. However, human communication also encompasses emotional and moral dimensions. We define the problem of affective alignment, which measures how LMs' emotional and moral tone represents those of different groups. By comparing the affect of responses generated by 36 LMs to the affect of Twitter messages, we observe significant misalignment of LMs with both ideological groups. This misalignment is larger than the partisan divide in the U.S. Even after steering the LMs towards specific ideological perspectives, the misalignment and liberal tendencies of the model persist, suggesting a systemic bias within LMs.
Reading Between the Tweets: Deciphering Ideological Stances of Interconnected Mixed-Ideology Communities
Feb 02, 2024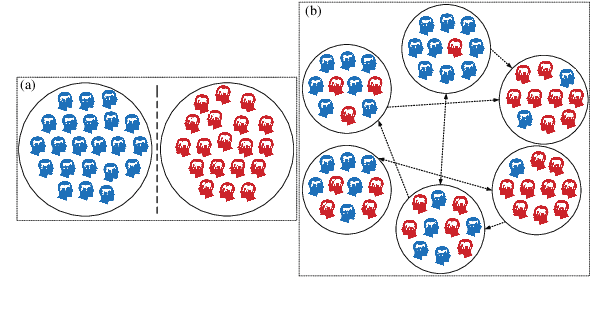
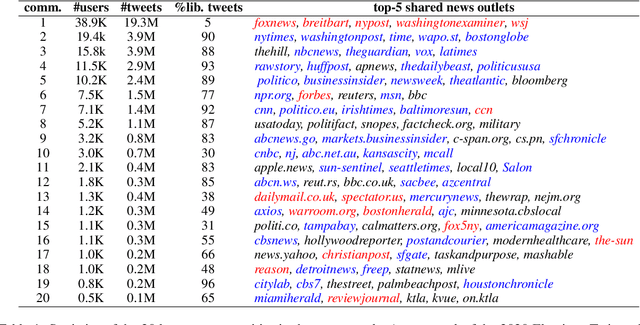
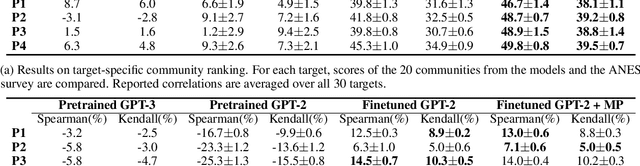
Recent advances in NLP have improved our ability to understand the nuanced worldviews of online communities. Existing research focused on probing ideological stances treats liberals and conservatives as separate groups. However, this fails to account for the nuanced views of the organically formed online communities and the connections between them. In this paper, we study discussions of the 2020 U.S. election on Twitter to identify complex interacting communities. Capitalizing on this interconnectedness, we introduce a novel approach that harnesses message passing when finetuning language models (LMs) to probe the nuanced ideologies of these communities. By comparing the responses generated by LMs and real-world survey results, our method shows higher alignment than existing baselines, highlighting the potential of using LMs in revealing complex ideologies within and across interconnected mixed-ideology communities.
Inducing Political Bias Allows Language Models Anticipate Partisan Reactions to Controversies
Nov 16, 2023



Social media platforms are rife with politically charged discussions. Therefore, accurately deciphering and predicting partisan biases using Large Language Models (LLMs) is increasingly critical. In this study, we address the challenge of understanding political bias in digitized discourse using LLMs. While traditional approaches often rely on finetuning separate models for each political faction, our work innovates by employing a singular, instruction-tuned LLM to reflect a spectrum of political ideologies. We present a comprehensive analytical framework, consisting of Partisan Bias Divergence Assessment and Partisan Class Tendency Prediction, to evaluate the model's alignment with real-world political ideologies in terms of stances, emotions, and moral foundations. Our findings reveal the model's effectiveness in capturing emotional and moral nuances, albeit with some challenges in stance detection, highlighting the intricacies and potential for refinement in NLP tools for politically sensitive contexts. This research contributes significantly to the field by demonstrating the feasibility and importance of nuanced political understanding in LLMs, particularly for applications requiring acute awareness of political bias.
Transcribing Educational Videos Using Whisper: A preliminary study on using AI for transcribing educational videos
Jul 04, 2023


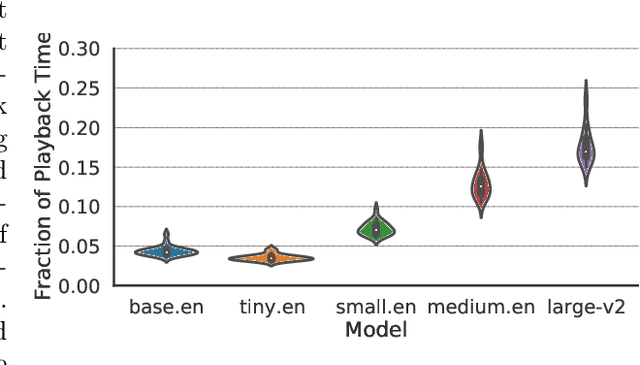
Videos are increasingly being used for e-learning, and transcripts are vital to enhance the learning experience. The costs and delays of generating transcripts can be alleviated by automatic speech recognition (ASR) systems. In this article, we quantify the transcripts generated by whisper for 25 educational videos and identify some open avenues of research when leveraging ASR for transcribing educational videos.
Nostradamus: Weathering Worth
Dec 08, 2022Nostradamus, inspired by the French astrologer and reputed seer, is a detailed study exploring relations between environmental factors and changes in the stock market. In this paper, we analyze associative correlation and causation between environmental elements and stock prices based on the US financial market, global climate trends, and daily weather records to demonstrate significant relationships between climate and stock price fluctuation. Our analysis covers short and long-term rises and dips in company stock performances. Lastly, we take four natural disasters as a case study to observe their effect on the emotional state of people and their influence on the stock market.
MVRackLay: Monocular Multi-View Layout Estimation for Warehouse Racks and Shelves
Nov 30, 2022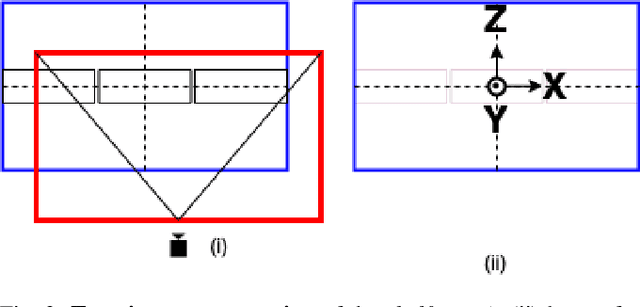
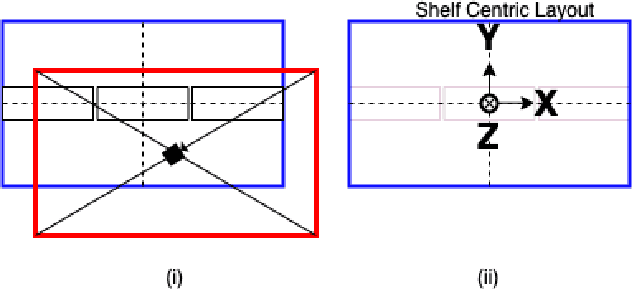
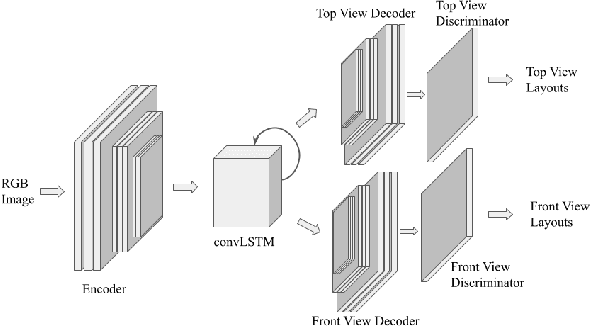
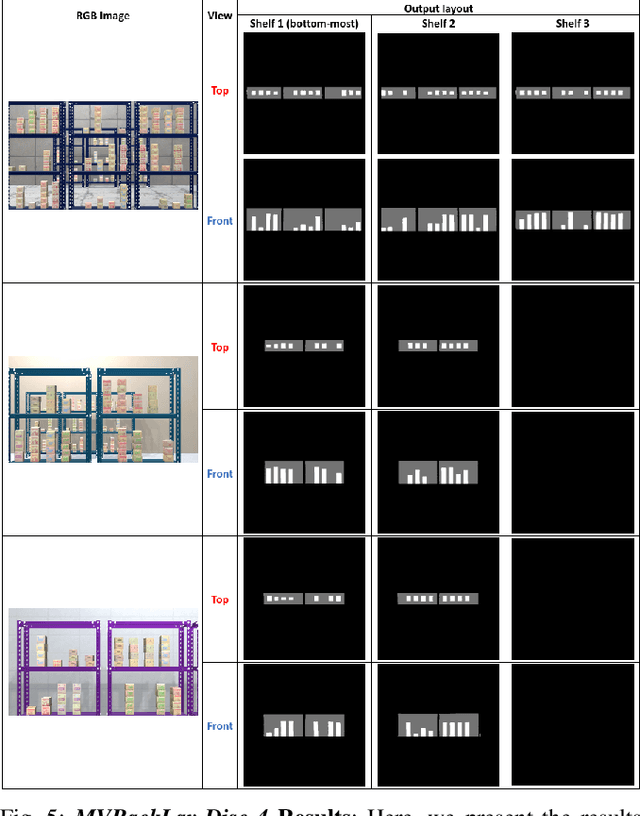
In this paper, we propose and showcase, for the first time, monocular multi-view layout estimation for warehouse racks and shelves. Unlike typical layout estimation methods, MVRackLay estimates multi-layered layouts, wherein each layer corresponds to the layout of a shelf within a rack. Given a sequence of images of a warehouse scene, a dual-headed Convolutional-LSTM architecture outputs segmented racks, the front and the top view layout of each shelf within a rack. With minimal effort, such an output is transformed into a 3D rendering of all racks, shelves and objects on the shelves, giving an accurate 3D depiction of the entire warehouse scene in terms of racks, shelves and the number of objects on each shelf. MVRackLay generalizes to a diverse set of warehouse scenes with varying number of objects on each shelf, number of shelves and in the presence of other such racks in the background. Further, MVRackLay shows superior performance vis-a-vis its single view counterpart, RackLay, in layout accuracy, quantized in terms of the mean IoU and mAP metrics. We also showcase a multi-view stitching of the 3D layouts resulting in a representation of the warehouse scene with respect to a global reference frame akin to a rendering of the scene from a SLAM pipeline. To the best of our knowledge, this is the first such work to portray a 3D rendering of a warehouse scene in terms of its semantic components - Racks, Shelves and Objects - all from a single monocular camera.