 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileEgo Anywhere: Open Infrastructure for long horizon egocentric data on commodity hardware
May 07, 2026The recent advancement of Vision Language Action (VLA) models has driven a critical demand for large scale egocentric datasets. However, existing datasets are often limited by short episode durations, typically spanning only a few minutes, which fails to capture the long horizon temporal dependencies necessary for complex robotic task execution. To bridge this gap, we present MobileEgo Anywhere, a framework designed to facilitate the collection of robust, hour plus egocentric trajectories using commodity mobile hardware. We leverage the ubiquitous sensor suites of modern smartphones to provide high fidelity, long term camera pose tracking, effectively removing the high hardware barriers associated with traditional robotics data collection. Our contributions are three fold: (1) we release a novel dataset comprising 200 hours of diverse, long form egocentric data with persistent state tracking; (2) we open source a mobile application that enables any user to record egocentric data, and (3) we provide a comprehensive processing pipeline to convert raw mobile captures into standardized, training ready formats for Vision Language Action model and foundation model research. By democratizing the data collection process, this work enables the massive scale acquisition of long horizon data across varied global environments, accelerating the development of generalizable robotic policies.
Covert Quantum Learning: Privately and Verifiably Learning from Quantum Data
Oct 08, 2025Quantum learning from remotely accessed quantum compute and data must address two key challenges: verifying the correctness of data and ensuring the privacy of the learner's data-collection strategies and resulting conclusions. The covert (verifiable) learning model of Canetti and Karchmer (TCC 2021) provides a framework for endowing classical learning algorithms with such guarantees. In this work, we propose models of covert verifiable learning in quantum learning theory and realize them without computational hardness assumptions for remote data access scenarios motivated by established quantum data advantages. We consider two privacy notions: (i) strategy-covertness, where the eavesdropper does not gain information about the learner's strategy; and (ii) target-covertness, where the eavesdropper does not gain information about the unknown object being learned. We show: Strategy-covert algorithms for making quantum statistical queries via classical shadows; Target-covert algorithms for learning quadratic functions from public quantum examples and private quantum statistical queries, for Pauli shadow tomography and stabilizer state learning from public multi-copy and private single-copy quantum measurements, and for solving Forrelation and Simon's problem from public quantum queries and private classical queries, where the adversary is a unidirectional or i.i.d. ancilla-free eavesdropper. The lattermost results in particular establish that the exponential separation between classical and quantum queries for Forrelation and Simon's problem survives under covertness constraints. Along the way, we design covert verifiable protocols for quantum data acquisition from public quantum queries which may be of independent interest. Overall, our models and corresponding algorithms demonstrate that quantum advantages are privately and verifiably achievable even with untrusted, remote data.
InterIntent: Investigating Social Intelligence of LLMs via Intention Understanding in an Interactive Game Context
Jun 18, 2024

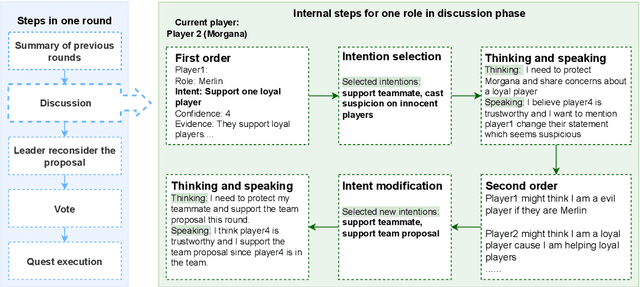

Large language models (LLMs) have demonstrated the potential to mimic human social intelligence. However, most studies focus on simplistic and static self-report or performance-based tests, which limits the depth and validity of the analysis. In this paper, we developed a novel framework, InterIntent, to assess LLMs' social intelligence by mapping their ability to understand and manage intentions in a game setting. We focus on four dimensions of social intelligence: situational awareness, self-regulation, self-awareness, and theory of mind. Each dimension is linked to a specific game task: intention selection, intention following, intention summarization, and intention guessing. Our findings indicate that while LLMs exhibit high proficiency in selecting intentions, achieving an accuracy of 88\%, their ability to infer the intentions of others is significantly weaker, trailing human performance by 20\%. Additionally, game performance correlates with intention understanding, highlighting the importance of the four components towards success in this game. These findings underline the crucial role of intention understanding in evaluating LLMs' social intelligence and highlight the potential of using social deduction games as a complex testbed to enhance LLM evaluation. InterIntent contributes a structured approach to bridging the evaluation gap in social intelligence within multiplayer games.
Don't Blame the Data, Blame the Model: Understanding Noise and Bias When Learning from Subjective Annotations
Mar 06, 2024Researchers have raised awareness about the harms of aggregating labels especially in subjective tasks that naturally contain disagreements among human annotators. In this work we show that models that are only provided aggregated labels show low confidence on high-disagreement data instances. While previous studies consider such instances as mislabeled, we argue that the reason the high-disagreement text instances have been hard-to-learn is that the conventional aggregated models underperform in extracting useful signals from subjective tasks. Inspired by recent studies demonstrating the effectiveness of learning from raw annotations, we investigate classifying using Multiple Ground Truth (Multi-GT) approaches. Our experiments show an improvement of confidence for the high-disagreement instances.
C3S Micro-architectural Enhancement: Spike Encoder Block and Relaxing Gamma Clock (Asynchronous)
Jun 26, 2023
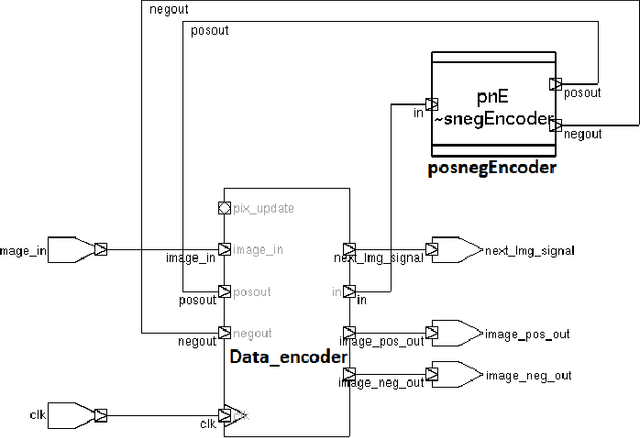
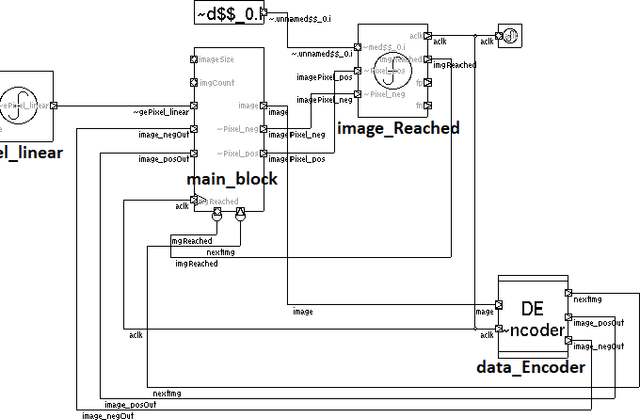
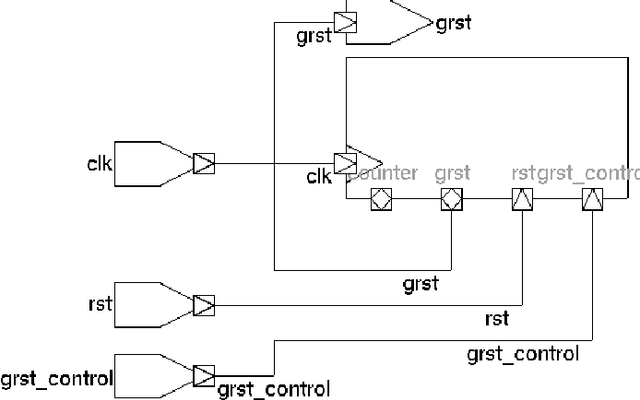
The field of neuromorphic computing is rapidly evolving. As both biological accuracy and practical implementations are explored, existing architectures are modified and improved for both purposes. The Temporal Neural Network(TNN) style of architecture is a good basis for approximating biological neurons due to its use of timed pulses to encode data and a voltage-threshold-like system. Using the Temporal Neural Network cortical column C3S architecture design as a basis, this project seeks to augment the network's design. This project takes note of two ideas and presents their designs with the goal of improving existing cortical column architecture. One need in this field is for an encoder that could convert between common digital formats and timed neuronal spikes, as biologically accurate networks are temporal in nature. To this end, this project presents an encoder to translate between binary encoded values and timed spikes to be processed by the neural network. Another need is for the reduction of wasted processing time to idleness, caused by lengthy Gamma cycle processing bursts. To this end, this project presents a relaxation of Gamma cycles to allow for them to end arbitrarily early once the network has determined an output response. With the goal of contributing to the betterment of the field of neuromorphic computer architecture, designs for both a binary-to-spike encoder, as well as a Gamma cycle controller, are presented and evaluated for optimal design parameters, with overall system gain and performance.
Charged particle tracking with quantum annealing-inspired optimization
Aug 13, 2019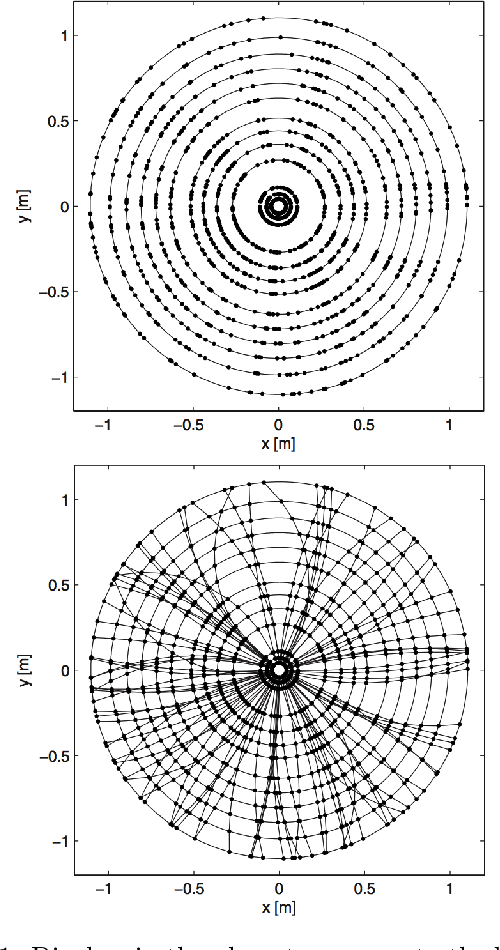
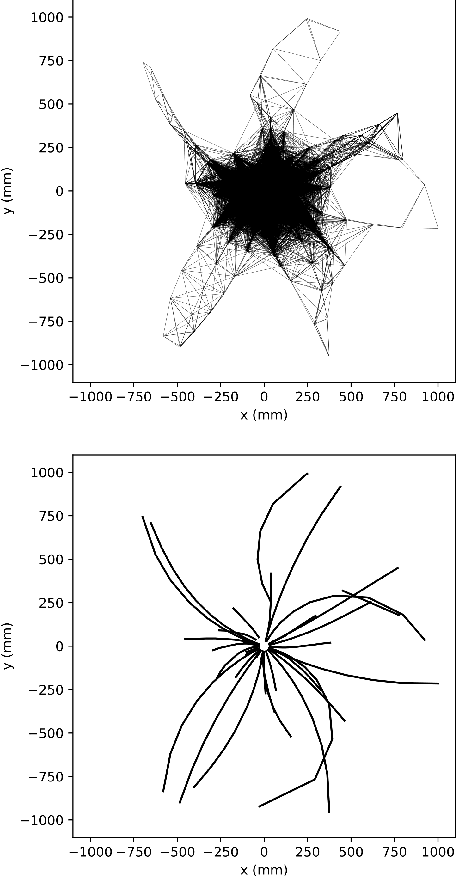
At the High Luminosity Large Hadron Collider (HL-LHC), traditional track reconstruction techniques that are critical for analysis are expected to face challenges due to scaling with track density. Quantum annealing has shown promise in its ability to solve combinatorial optimization problems amidst an ongoing effort to establish evidence of a quantum speedup. As a step towards exploiting such potential speedup, we investigate a track reconstruction approach by adapting the existing geometric Denby-Peterson (Hopfield) network method to the quantum annealing framework and to HL-LHC conditions. Furthermore, we develop additional techniques to embed the problem onto existing and near-term quantum annealing hardware. Results using simulated annealing and quantum annealing with the D-Wave 2X system on the TrackML dataset are presented, demonstrating the successful application of a quantum annealing-inspired algorithm to the track reconstruction challenge. We find that combinatorial optimization problems can effectively reconstruct tracks, suggesting possible applications for fast hardware-specific implementations at the LHC while leaving open the possibility of a quantum speedup for tracking.
3D Scene Grammar for Parsing RGB-D Pointclouds
Nov 08, 2012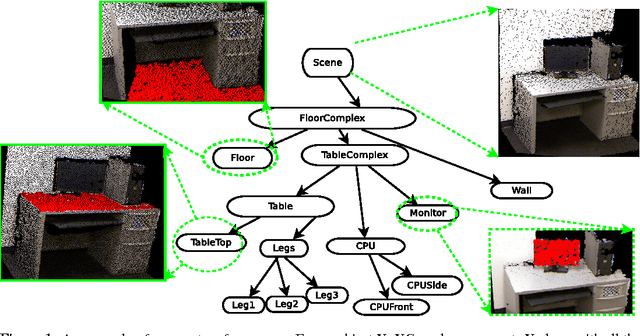


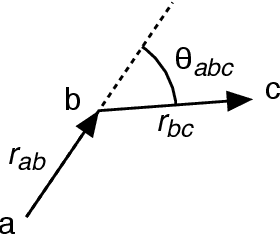
We pose 3D scene-understanding as a problem of parsing in a grammar. A grammar helps us capture the compositional structure of real-word objects, e.g., a chair is composed of a seat, a back-rest and some legs. Having multiple rules for an object helps us capture structural variations in objects, e.g., a chair can optionally also have arm-rests. Finally, having rules to capture composition at different levels helps us formulate the entire scene-processing pipeline as a single problem of finding most likely parse-tree---small segments combine to form parts of objects, parts to objects and objects to a scene. We attach a generative probability model to our grammar by having a feature-dependent probability function for every rule. We evaluated it by extracting labels for every segment and comparing the results with the state-of-the-art segment-labeling algorithm. Our algorithm was outperformed by the state-or-the-art method. But, Our model can be trained very efficiently (within seconds), and it scales only linearly in with the number of rules in the grammar. Also, we think that this is an important problem for the 3D vision community. So, we are releasing our dataset and related code.
Contextually Guided Semantic Labeling and Search for 3D Point Clouds
Sep 05, 2012
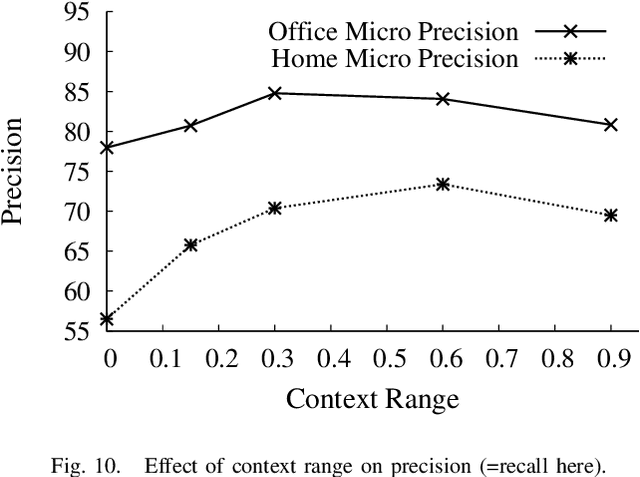


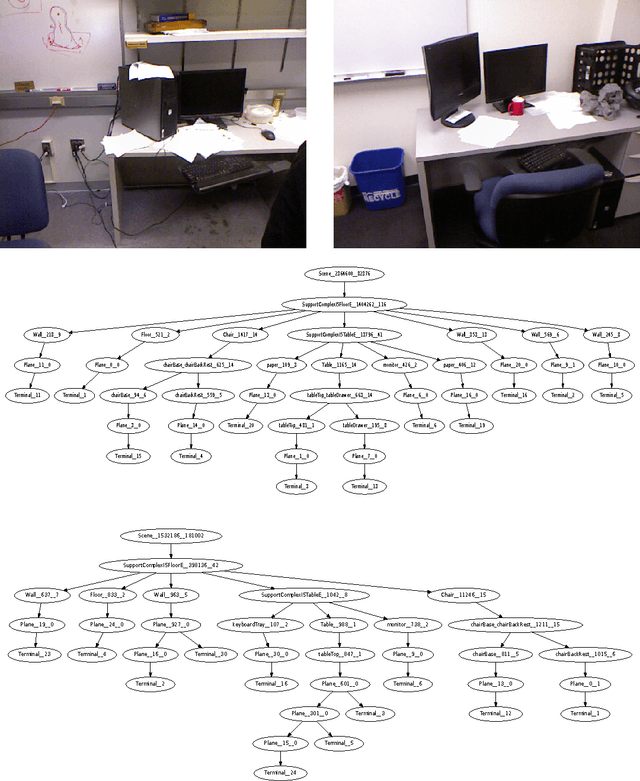
RGB-D cameras, which give an RGB image to- gether with depths, are becoming increasingly popular for robotic perception. In this paper, we address the task of detecting commonly found objects in the 3D point cloud of indoor scenes obtained from such cameras. Our method uses a graphical model that captures various features and contextual relations, including the local visual appearance and shape cues, object co-occurence relationships and geometric relationships. With a large number of object classes and relations, the model's parsimony becomes important and we address that by using multiple types of edge potentials. We train the model using a maximum-margin learning approach. In our experiments over a total of 52 3D scenes of homes and offices (composed from about 550 views), we get a performance of 84.06% and 73.38% in labeling office and home scenes respectively for 17 object classes each. We also present a method for a robot to search for an object using the learned model and the contextual information available from the current labelings of the scene. We applied this algorithm successfully on a mobile robot for the task of finding 12 object classes in 10 different offices and achieved a precision of 97.56% with 78.43% recall.
Labeling 3D scenes for Personal Assistant Robots
Jun 28, 2011



Inexpensive RGB-D cameras that give an RGB image together with depth data have become widely available. We use this data to build 3D point clouds of a full scene. In this paper, we address the task of labeling objects in this 3D point cloud of a complete indoor scene such as an office. We propose a graphical model that captures various features and contextual relations, including the local visual appearance and shape cues, object co-occurrence relationships and geometric relationships. With a large number of object classes and relations, the model's parsimony becomes important and we address that by using multiple types of edge potentials. The model admits efficient approximate inference, and we train it using a maximum-margin learning approach. In our experiments over a total of 52 3D scenes of homes and offices (composed from about 550 views, having 2495 segments labeled with 27 object classes), we get a performance of 84.06% in labeling 17 object classes for offices, and 73.38% in labeling 17 object classes for home scenes. Finally, we applied these algorithms successfully on a mobile robot for the task of finding an object in a large cluttered room.