 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Evaluation of Sentiment Analysis on Text and Emoji Data Using End-to-End, Transfer Learning, Distributed and Explainable AI Models
Feb 18, 2025



Emojis are being frequently used in todays digital world to express from simple to complex thoughts more than ever before. Hence, they are also being used in sentiment analysis and targeted marketing campaigns. In this work, we performed sentiment analysis of Tweets as well as on emoji dataset from the Kaggle. Since tweets are sentences we have used Universal Sentence Encoder (USE) and Sentence Bidirectional Encoder Representations from Transformers (SBERT) end-to-end sentence embedding models to generate the embeddings which are used to train the Standard fully connected Neural Networks (NN), and LSTM NN models. We observe the text classification accuracy was almost the same for both the models around 98 percent. On the contrary, when the validation set was built using emojis that were not present in the training set then the accuracy of both the models reduced drastically to 70 percent. In addition, the models were also trained using the distributed training approach instead of a traditional singlethreaded model for better scalability. Using the distributed training approach, we were able to reduce the run-time by roughly 15% without compromising on accuracy. Finally, as part of explainable AI the Shap algorithm was used to explain the model behaviour and check for model biases for the given feature set.
MDPs with Unawareness in Robotics
May 20, 2020We formalize decision-making problems in robotics and automated control using continuous MDPs and actions that take place over continuous time intervals. We then approximate the continuous MDP using finer and finer discretizations. Doing this results in a family of systems, each of which has an extremely large action space, although only a few actions are "interesting". We can view the decision maker as being unaware of which actions are "interesting". We can model this using MDPUs, MDPs with unawareness, where the action space is much smaller. As we show, MDPUs can be used as a general framework for learning tasks in robotic problems. We prove results on the difficulty of learning a near-optimal policy in an an MDPU for a continuous task. We apply these ideas to the problem of having a humanoid robot learn on its own how to walk.
Learning to Represent Haptic Feedback for Partially-Observable Tasks
May 17, 2017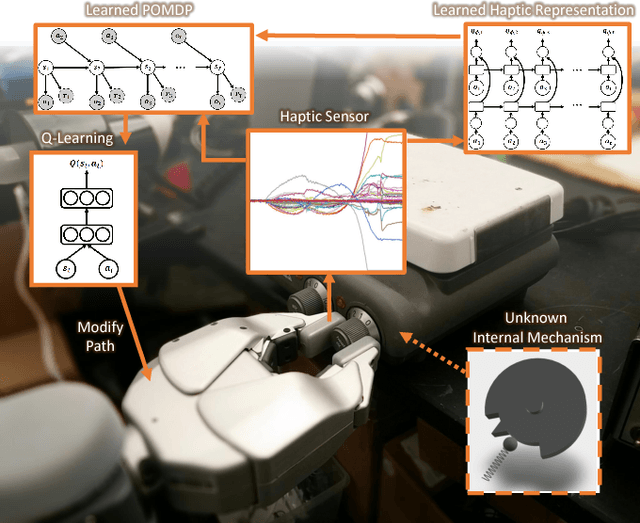
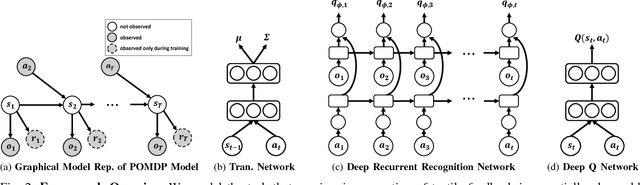
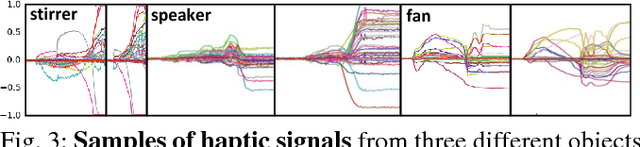
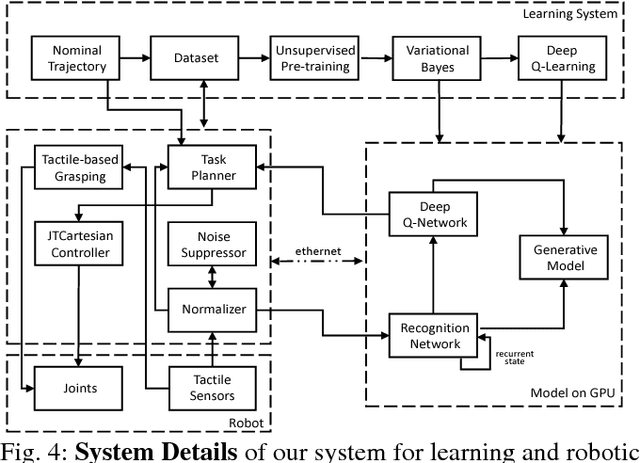
The sense of touch, being the earliest sensory system to develop in a human body [1], plays a critical part of our daily interaction with the environment. In order to successfully complete a task, many manipulation interactions require incorporating haptic feedback. However, manually designing a feedback mechanism can be extremely challenging. In this work, we consider manipulation tasks that need to incorporate tactile sensor feedback in order to modify a provided nominal plan. To incorporate partial observation, we present a new framework that models the task as a partially observable Markov decision process (POMDP) and learns an appropriate representation of haptic feedback which can serve as the state for a POMDP model. The model, that is parametrized by deep recurrent neural networks, utilizes variational Bayes methods to optimize the approximate posterior. Finally, we build on deep Q-learning to be able to select the optimal action in each state without access to a simulator. We test our model on a PR2 robot for multiple tasks of turning a knob until it clicks.
Deep Multimodal Embedding: Manipulating Novel Objects with Point-clouds, Language and Trajectories
May 17, 2017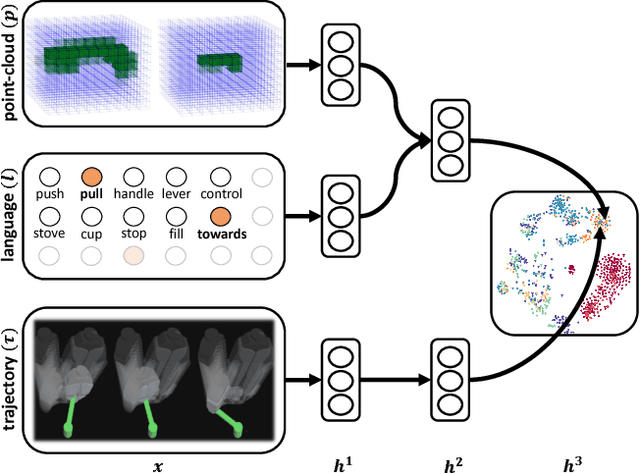
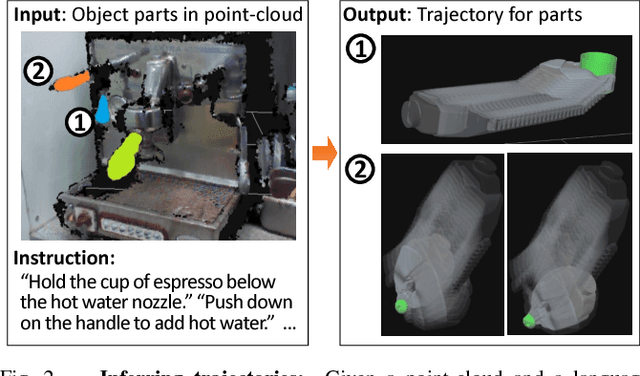
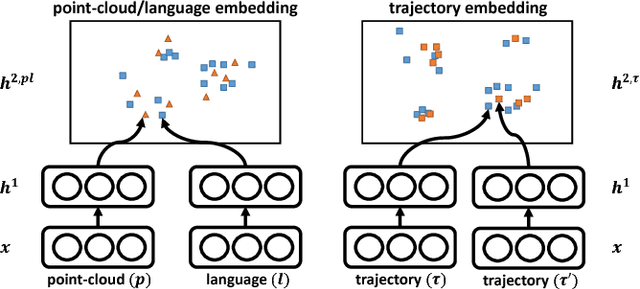
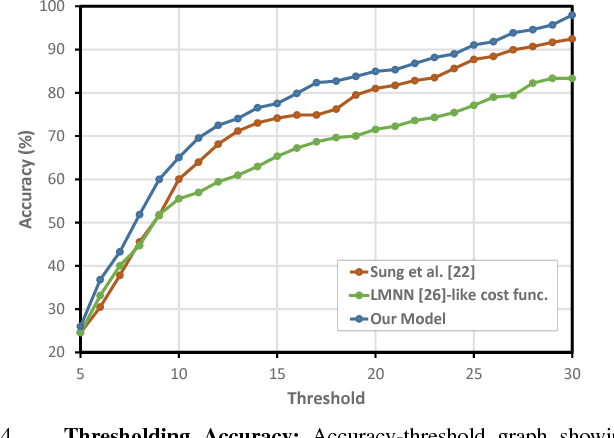
A robot operating in a real-world environment needs to perform reasoning over a variety of sensor modalities such as vision, language and motion trajectories. However, it is extremely challenging to manually design features relating such disparate modalities. In this work, we introduce an algorithm that learns to embed point-cloud, natural language, and manipulation trajectory data into a shared embedding space with a deep neural network. To learn semantically meaningful spaces throughout our network, we use a loss-based margin to bring embeddings of relevant pairs closer together while driving less-relevant cases from different modalities further apart. We use this both to pre-train its lower layers and fine-tune our final embedding space, leading to a more robust representation. We test our algorithm on the task of manipulating novel objects and appliances based on prior experience with other objects. On a large dataset, we achieve significant improvements in both accuracy and inference time over the previous state of the art. We also perform end-to-end experiments on a PR2 robot utilizing our learned embedding space.
Human Centred Object Co-Segmentation
Jun 12, 2016
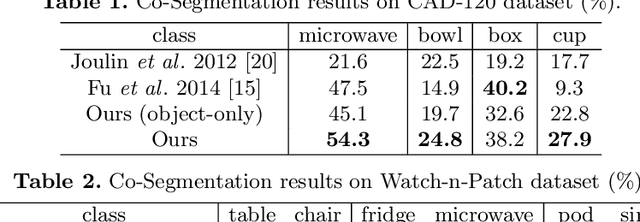
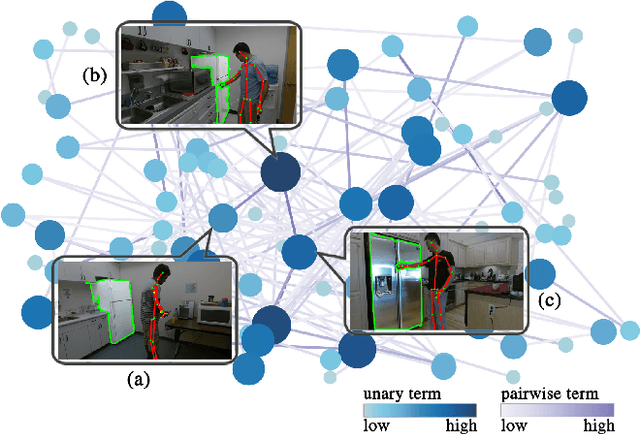
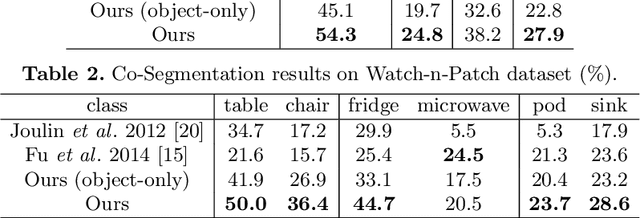
Co-segmentation is the automatic extraction of the common semantic regions given a set of images. Different from previous approaches mainly based on object visuals, in this paper, we propose a human centred object co-segmentation approach, which uses the human as another strong evidence. In order to discover the rich internal structure of the objects reflecting their human-object interactions and visual similarities, we propose an unsupervised fully connected CRF auto-encoder incorporating the rich object features and a novel human-object interaction representation. We propose an efficient learning and inference algorithm to allow the full connectivity of the CRF with the auto-encoder, that establishes pairwise relations on all pairs of the object proposals in the dataset. Moreover, the auto-encoder learns the parameters from the data itself rather than supervised learning or manually assigned parameters in the conventional CRF. In the extensive experiments on four datasets, we show that our approach is able to extract the common objects more accurately than the state-of-the-art co-segmentation algorithms.
Unsupervised Semantic Action Discovery from Video Collections
May 11, 2016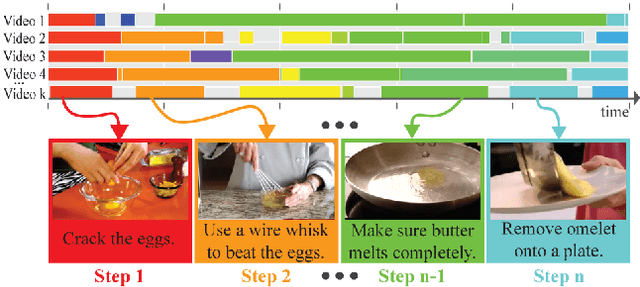


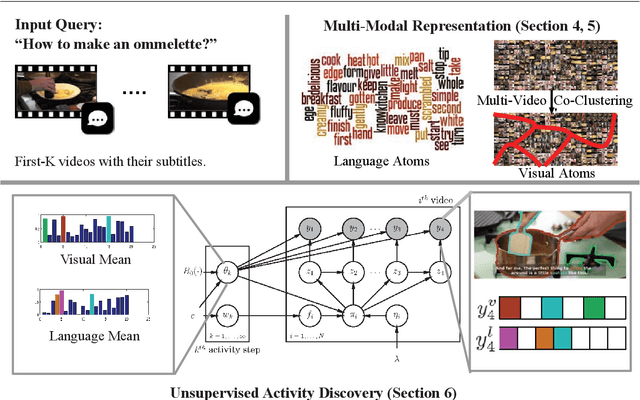
Human communication takes many forms, including speech, text and instructional videos. It typically has an underlying structure, with a starting point, ending, and certain objective steps between them. In this paper, we consider instructional videos where there are tens of millions of them on the Internet. We propose a method for parsing a video into such semantic steps in an unsupervised way. Our method is capable of providing a semantic "storyline" of the video composed of its objective steps. We accomplish this using both visual and language cues in a joint generative model. Our method can also provide a textual description for each of the identified semantic steps and video segments. We evaluate our method on a large number of complex YouTube videos and show that our method discovers semantically correct instructions for a variety of tasks.
Structural-RNN: Deep Learning on Spatio-Temporal Graphs
Apr 11, 2016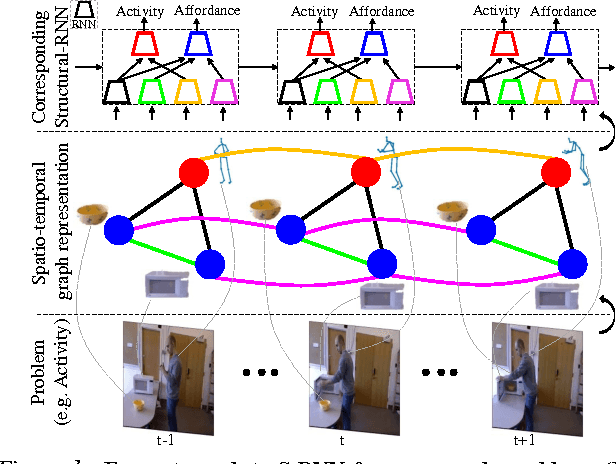
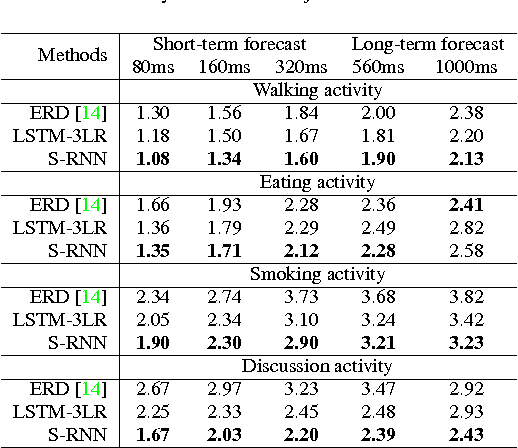
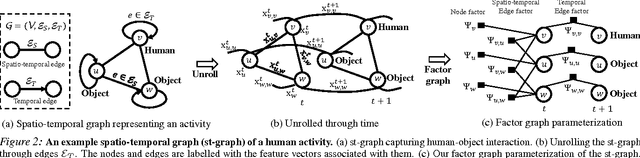
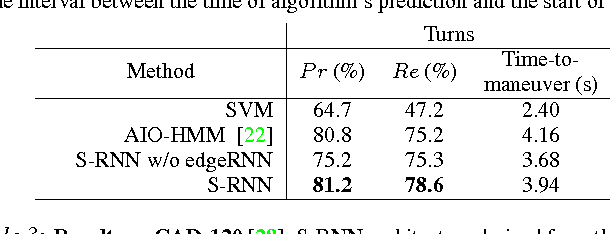
Deep Recurrent Neural Network architectures, though remarkably capable at modeling sequences, lack an intuitive high-level spatio-temporal structure. That is while many problems in computer vision inherently have an underlying high-level structure and can benefit from it. Spatio-temporal graphs are a popular tool for imposing such high-level intuitions in the formulation of real world problems. In this paper, we propose an approach for combining the power of high-level spatio-temporal graphs and sequence learning success of Recurrent Neural Networks~(RNNs). We develop a scalable method for casting an arbitrary spatio-temporal graph as a rich RNN mixture that is feedforward, fully differentiable, and jointly trainable. The proposed method is generic and principled as it can be used for transforming any spatio-temporal graph through employing a certain set of well defined steps. The evaluations of the proposed approach on a diverse set of problems, ranging from modeling human motion to object interactions, shows improvement over the state-of-the-art with a large margin. We expect this method to empower new approaches to problem formulation through high-level spatio-temporal graphs and Recurrent Neural Networks.
Unsupervised Transductive Domain Adaptation
Mar 25, 2016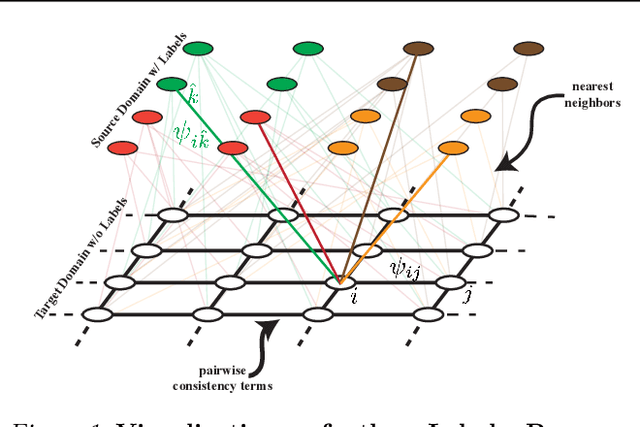
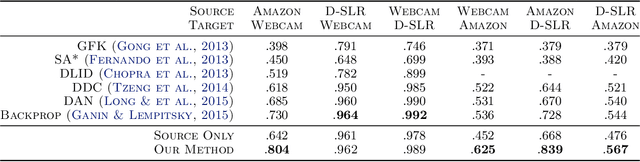

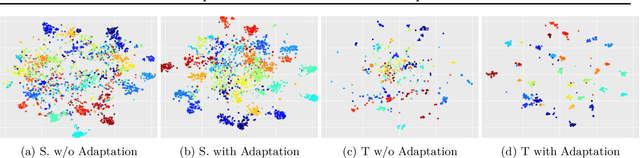
Supervised learning with large scale labeled datasets and deep layered models has made a paradigm shift in diverse areas in learning and recognition. However, this approach still suffers generalization issues under the presence of a domain shift between the training and the test data distribution. In this regard, unsupervised domain adaptation algorithms have been proposed to directly address the domain shift problem. In this paper, we approach the problem from a transductive perspective. We incorporate the domain shift and the transductive target inference into our framework by jointly solving for an asymmetric similarity metric and the optimal transductive target label assignment. We also show that our model can easily be extended for deep feature learning in order to learn features which are discriminative in the target domain. Our experiments show that the proposed method significantly outperforms state-of-the-art algorithms in both object recognition and digit classification experiments by a large margin.
Watch-n-Patch: Unsupervised Learning of Actions and Relations
Mar 11, 2016

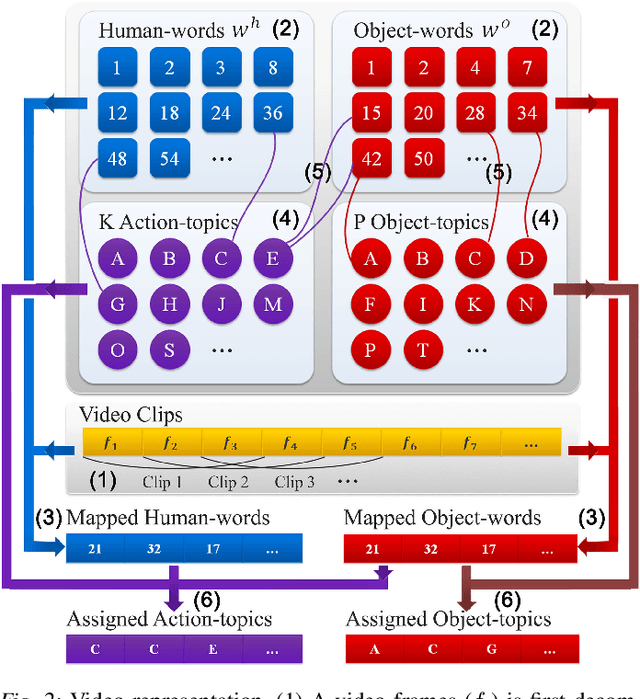
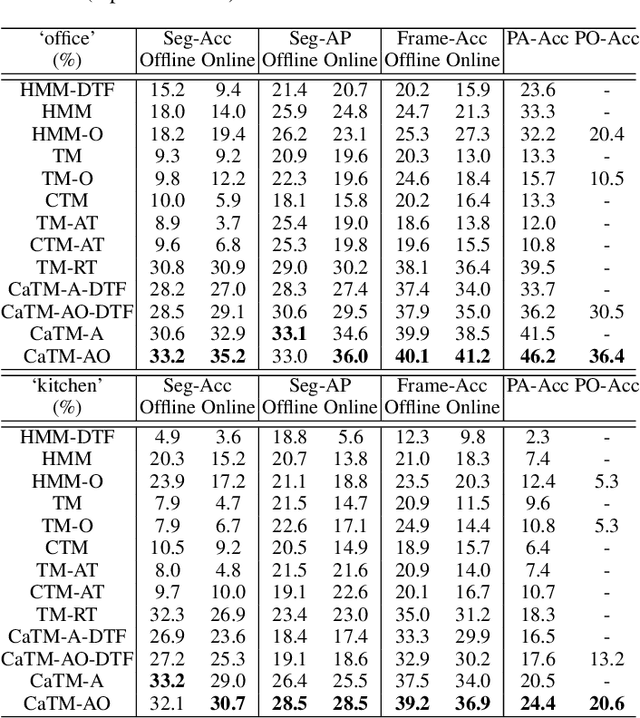
There is a large variation in the activities that humans perform in their everyday lives. We consider modeling these composite human activities which comprises multiple basic level actions in a completely unsupervised setting. Our model learns high-level co-occurrence and temporal relations between the actions. We consider the video as a sequence of short-term action clips, which contains human-words and object-words. An activity is about a set of action-topics and object-topics indicating which actions are present and which objects are interacting with. We then propose a new probabilistic model relating the words and the topics. It allows us to model long-range action relations that commonly exist in the composite activities, which is challenging in previous works. We apply our model to the unsupervised action segmentation and clustering, and to a novel application that detects forgotten actions, which we call action patching. For evaluation, we contribute a new challenging RGB-D activity video dataset recorded by the new Kinect v2, which contains several human daily activities as compositions of multiple actions interacting with different objects. Moreover, we develop a robotic system that watches people and reminds people by applying our action patching algorithm. Our robotic setup can be easily deployed on any assistive robot.
Unsupervised Semantic Parsing of Video Collections
Jan 27, 2016


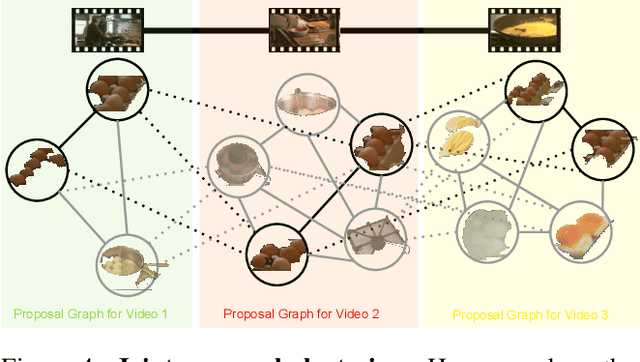
Human communication typically has an underlying structure. This is reflected in the fact that in many user generated videos, a starting point, ending, and certain objective steps between these two can be identified. In this paper, we propose a method for parsing a video into such semantic steps in an unsupervised way. The proposed method is capable of providing a semantic "storyline" of the video composed of its objective steps. We accomplish this using both visual and language cues in a joint generative model. The proposed method can also provide a textual description for each of the identified semantic steps and video segments. We evaluate this method on a large number of complex YouTube videos and show results of unprecedented quality for this intricate and impactful problem.