 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Represent Haptic Feedback for Partially-Observable Tasks
May 17, 2017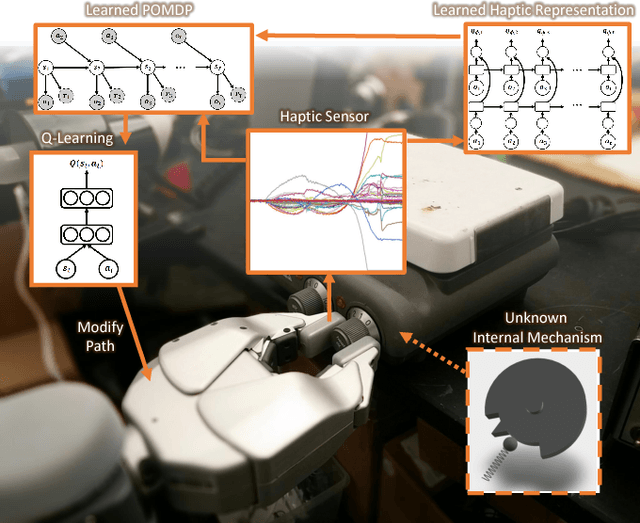
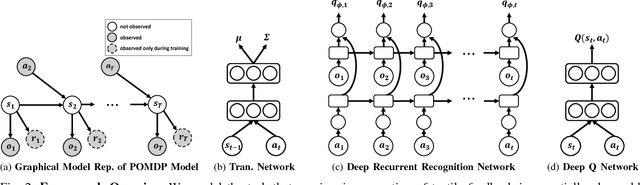
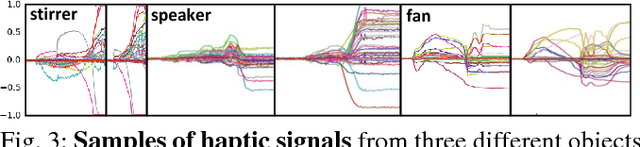
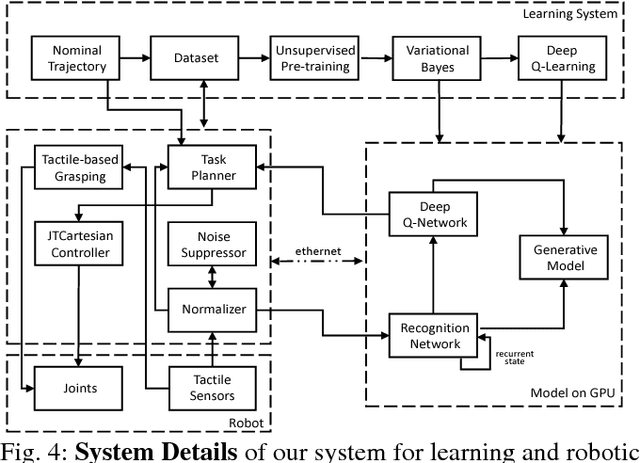
The sense of touch, being the earliest sensory system to develop in a human body [1], plays a critical part of our daily interaction with the environment. In order to successfully complete a task, many manipulation interactions require incorporating haptic feedback. However, manually designing a feedback mechanism can be extremely challenging. In this work, we consider manipulation tasks that need to incorporate tactile sensor feedback in order to modify a provided nominal plan. To incorporate partial observation, we present a new framework that models the task as a partially observable Markov decision process (POMDP) and learns an appropriate representation of haptic feedback which can serve as the state for a POMDP model. The model, that is parametrized by deep recurrent neural networks, utilizes variational Bayes methods to optimize the approximate posterior. Finally, we build on deep Q-learning to be able to select the optimal action in each state without access to a simulator. We test our model on a PR2 robot for multiple tasks of turning a knob until it clicks.
Deep Multimodal Embedding: Manipulating Novel Objects with Point-clouds, Language and Trajectories
May 17, 2017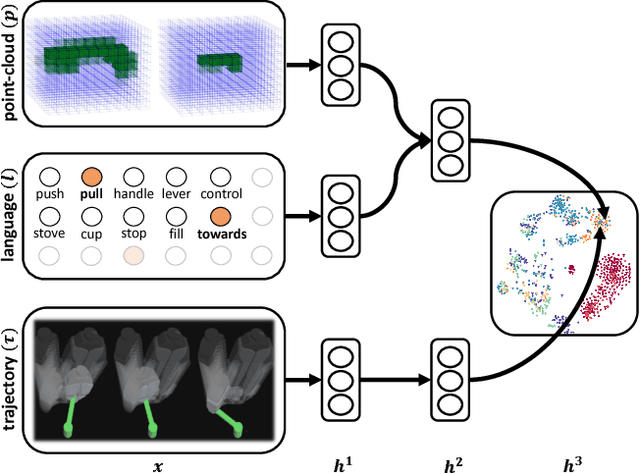
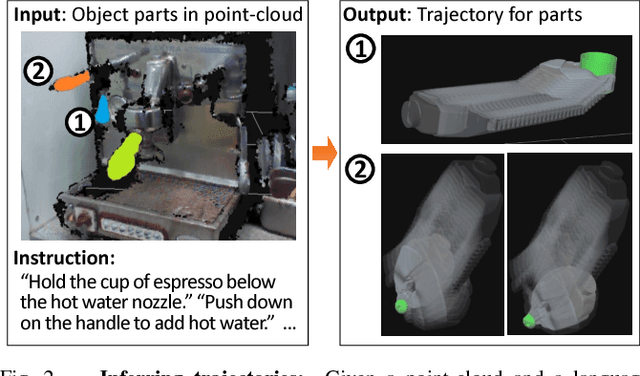
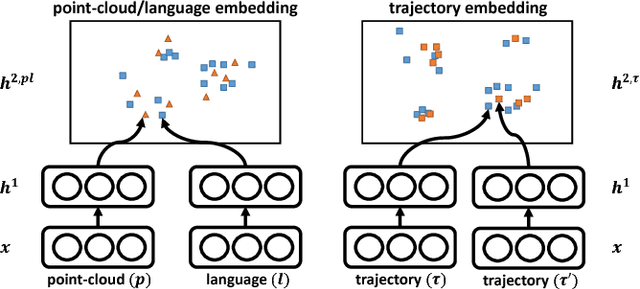
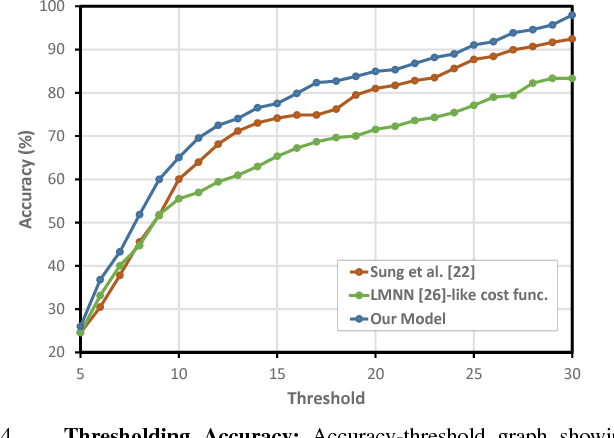
A robot operating in a real-world environment needs to perform reasoning over a variety of sensor modalities such as vision, language and motion trajectories. However, it is extremely challenging to manually design features relating such disparate modalities. In this work, we introduce an algorithm that learns to embed point-cloud, natural language, and manipulation trajectory data into a shared embedding space with a deep neural network. To learn semantically meaningful spaces throughout our network, we use a loss-based margin to bring embeddings of relevant pairs closer together while driving less-relevant cases from different modalities further apart. We use this both to pre-train its lower layers and fine-tune our final embedding space, leading to a more robust representation. We test our algorithm on the task of manipulating novel objects and appliances based on prior experience with other objects. On a large dataset, we achieve significant improvements in both accuracy and inference time over the previous state of the art. We also perform end-to-end experiments on a PR2 robot utilizing our learned embedding space.
Robobarista: Learning to Manipulate Novel Objects via Deep Multimodal Embedding
Jan 12, 2016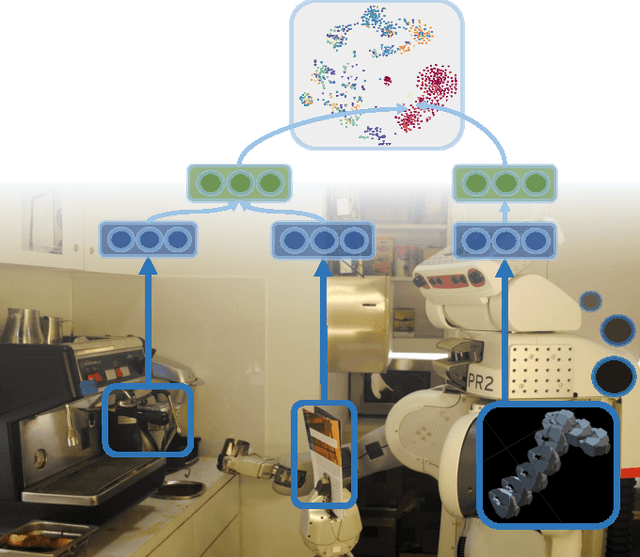

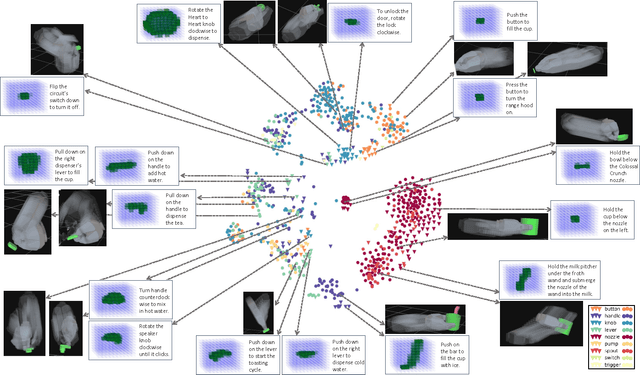
There is a large variety of objects and appliances in human environments, such as stoves, coffee dispensers, juice extractors, and so on. It is challenging for a roboticist to program a robot for each of these object types and for each of their instantiations. In this work, we present a novel approach to manipulation planning based on the idea that many household objects share similarly-operated object parts. We formulate the manipulation planning as a structured prediction problem and learn to transfer manipulation strategy across different objects by embedding point-cloud, natural language, and manipulation trajectory data into a shared embedding space using a deep neural network. In order to learn semantically meaningful spaces throughout our network, we introduce a method for pre-training its lower layers for multimodal feature embedding and a method for fine-tuning this embedding space using a loss-based margin. In order to collect a large number of manipulation demonstrations for different objects, we develop a new crowd-sourcing platform called Robobarista. We test our model on our dataset consisting of 116 objects and appliances with 249 parts along with 250 language instructions, for which there are 1225 crowd-sourced manipulation demonstrations. We further show that our robot with our model can even prepare a cup of a latte with appliances it has never seen before.
Robobarista: Object Part based Transfer of Manipulation Trajectories from Crowd-sourcing in 3D Pointclouds
Sep 18, 2015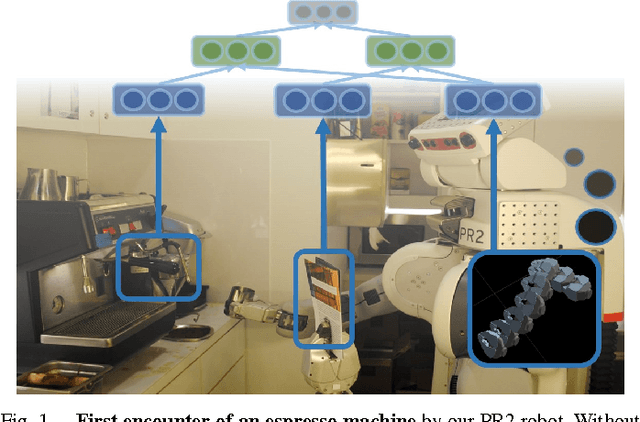

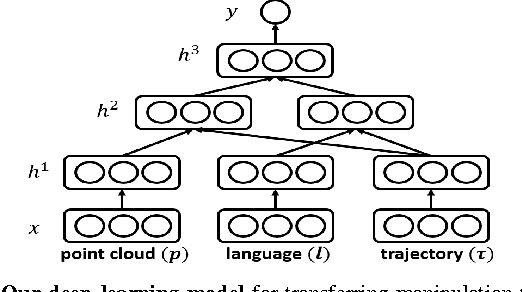
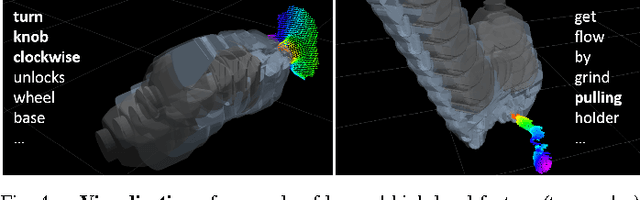
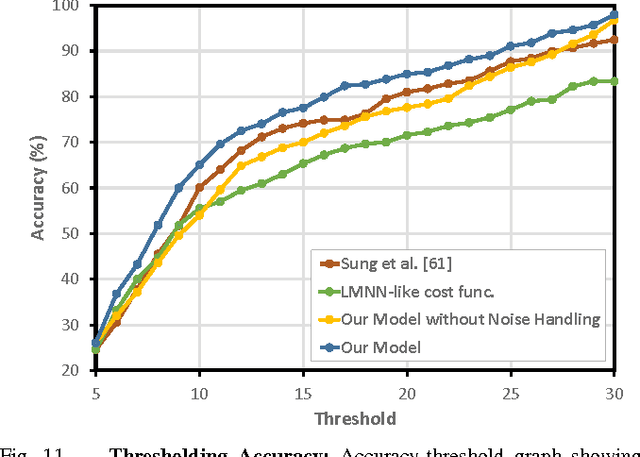
There is a large variety of objects and appliances in human environments, such as stoves, coffee dispensers, juice extractors, and so on. It is challenging for a roboticist to program a robot for each of these object types and for each of their instantiations. In this work, we present a novel approach to manipulation planning based on the idea that many household objects share similarly-operated object parts. We formulate the manipulation planning as a structured prediction problem and design a deep learning model that can handle large noise in the manipulation demonstrations and learns features from three different modalities: point-clouds, language and trajectory. In order to collect a large number of manipulation demonstrations for different objects, we developed a new crowd-sourcing platform called Robobarista. We test our model on our dataset consisting of 116 objects with 249 parts along with 250 language instructions, for which there are 1225 crowd-sourced manipulation demonstrations. We further show that our robot can even manipulate objects it has never seen before.
Synthesizing Manipulation Sequences for Under-Specified Tasks using Unrolled Markov Random Fields
Jun 24, 2014
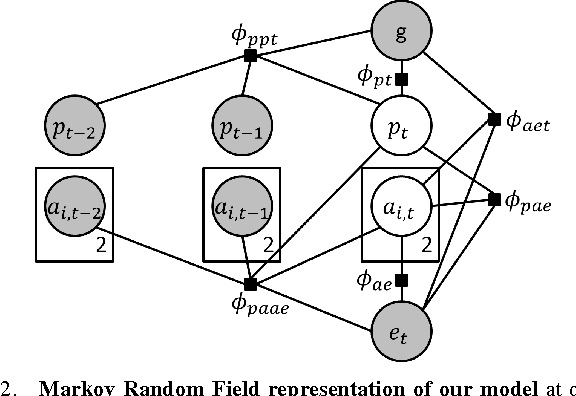

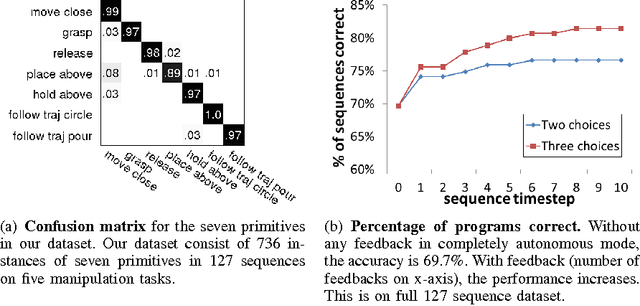
Many tasks in human environments require performing a sequence of navigation and manipulation steps involving objects. In unstructured human environments, the location and configuration of the objects involved often change in unpredictable ways. This requires a high-level planning strategy that is robust and flexible in an uncertain environment. We propose a novel dynamic planning strategy, which can be trained from a set of example sequences. High level tasks are expressed as a sequence of primitive actions or controllers (with appropriate parameters). Our score function, based on Markov Random Field (MRF), captures the relations between environment, controllers, and their arguments. By expressing the environment using sets of attributes, the approach generalizes well to unseen scenarios. We train the parameters of our MRF using a maximum margin learning method. We provide a detailed empirical validation of our overall framework demonstrating successful plan strategies for a variety of tasks.
Unstructured Human Activity Detection from RGBD Images
Feb 14, 2012
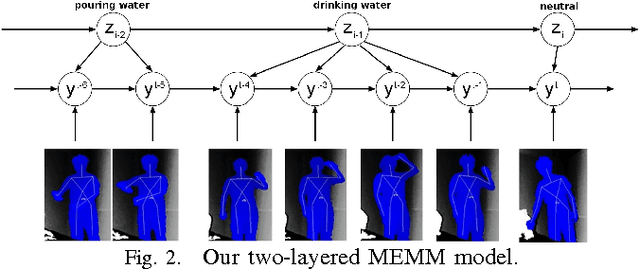


Being able to detect and recognize human activities is essential for several applications, including personal assistive robotics. In this paper, we perform detection and recognition of unstructured human activity in unstructured environments. We use a RGBD sensor (Microsoft Kinect) as the input sensor, and compute a set of features based on human pose and motion, as well as based on image and pointcloud information. Our algorithm is based on a hierarchical maximum entropy Markov model (MEMM), which considers a person's activity as composed of a set of sub-activities. We infer the two-layered graph structure using a dynamic programming approach. We test our algorithm on detecting and recognizing twelve different activities performed by four people in different environments, such as a kitchen, a living room, an office, etc., and achieve good performance even when the person was not seen before in the training set.