 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalEscaper: A Weakly-supervised Framework with Regional Reconstruction for Scalable Neural TSP Solvers
Feb 18, 2025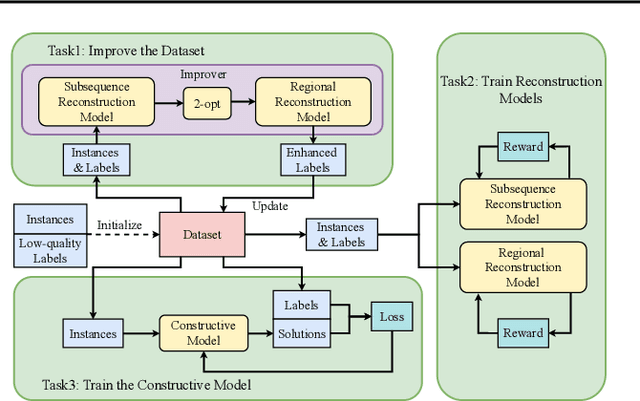
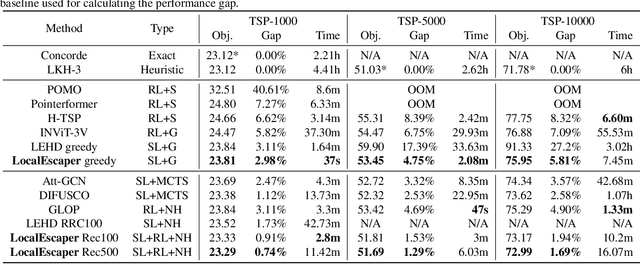
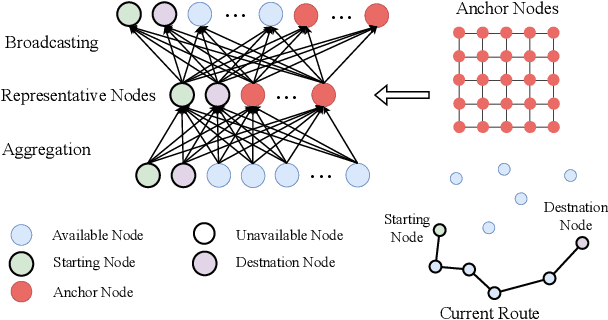
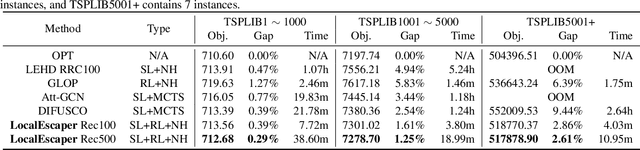
Neural solvers have shown significant potential in solving the Traveling Salesman Problem (TSP), yet current approaches face significant challenges. Supervised learning (SL)-based solvers require large amounts of high-quality labeled data, while reinforcement learning (RL)-based solvers, though less dependent on such data, often suffer from inefficiencies. To address these limitations, we propose LocalEscaper, a novel weakly-supervised learning framework for large-scale TSP. LocalEscaper effectively combines the advantages of both SL and RL, enabling effective training on datasets with low-quality labels. To further enhance solution quality, we introduce a regional reconstruction strategy, which mitigates the problem of local optima, a common issue in existing local reconstruction methods. Additionally, we propose a linear-complexity attention mechanism that reduces computational overhead, enabling the efficient solution of large-scale TSPs without sacrificing performance. Experimental results on both synthetic and real-world datasets demonstrate that LocalEscaper outperforms existing neural solvers, achieving state-of-the-art results. Notably, it sets a new benchmark for scalability and efficiency, solving TSP instances with up to 50,000 cities.
Position: Multimodal Large Language Models Can Significantly Advance Scientific Reasoning
Feb 05, 2025



Scientific reasoning, the process through which humans apply logic, evidence, and critical thinking to explore and interpret scientific phenomena, is essential in advancing knowledge reasoning across diverse fields. However, despite significant progress, current scientific reasoning models still struggle with generalization across domains and often fall short of multimodal perception. Multimodal Large Language Models (MLLMs), which integrate text, images, and other modalities, present an exciting opportunity to overcome these limitations and enhance scientific reasoning. Therefore, this position paper argues that MLLMs can significantly advance scientific reasoning across disciplines such as mathematics, physics, chemistry, and biology. First, we propose a four-stage research roadmap of scientific reasoning capabilities, and highlight the current state of MLLM applications in scientific reasoning, noting their ability to integrate and reason over diverse data types. Second, we summarize the key challenges that remain obstacles to achieving MLLM's full potential. To address these challenges, we propose actionable insights and suggestions for the future. Overall, our work offers a novel perspective on MLLM integration with scientific reasoning, providing the LLM community with a valuable vision for achieving Artificial General Intelligence (AGI).
Policy-Value Alignment and Robustness in Search-based Multi-Agent Learning
Feb 06, 2023Large-scale AI systems that combine search and learning have reached super-human levels of performance in game-playing, but have also been shown to fail in surprising ways. The brittleness of such models limits their efficacy and trustworthiness in real-world deployments. In this work, we systematically study one such algorithm, AlphaZero, and identify two phenomena related to the nature of exploration. First, we find evidence of policy-value misalignment -- for many states, AlphaZero's policy and value predictions contradict each other, revealing a tension between accurate move-selection and value estimation in AlphaZero's objective. Further, we find inconsistency within AlphaZero's value function, which causes it to generalize poorly, despite its policy playing an optimal strategy. From these insights we derive VISA-VIS: a novel method that improves policy-value alignment and value robustness in AlphaZero. Experimentally, we show that our method reduces policy-value misalignment by up to 76%, reduces value generalization error by up to 50%, and reduces average value error by up to 55%.
Graph Value Iteration
Sep 20, 2022

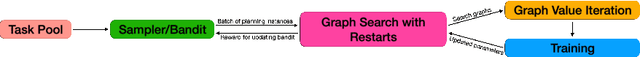

In recent years, deep Reinforcement Learning (RL) has been successful in various combinatorial search domains, such as two-player games and scientific discovery. However, directly applying deep RL in planning domains is still challenging. One major difficulty is that without a human-crafted heuristic function, reward signals remain zero unless the learning framework discovers any solution plan. Search space becomes \emph{exponentially larger} as the minimum length of plans grows, which is a serious limitation for planning instances with a minimum plan length of hundreds to thousands of steps. Previous learning frameworks that augment graph search with deep neural networks and extra generated subgoals have achieved success in various challenging planning domains. However, generating useful subgoals requires extensive domain knowledge. We propose a domain-independent method that augments graph search with graph value iteration to solve hard planning instances that are out of reach for domain-specialized solvers. In particular, instead of receiving learning signals only from discovered plans, our approach also learns from failed search attempts where no goal state has been reached. The graph value iteration component can exploit the graph structure of local search space and provide more informative learning signals. We also show how we use a curriculum strategy to smooth the learning process and perform a full analysis of how graph value iteration scales and enables learning.
Left Heavy Tails and the Effectiveness of the Policy and Value Networks in DNN-based best-first search for Sokoban Planning
Jun 28, 2022


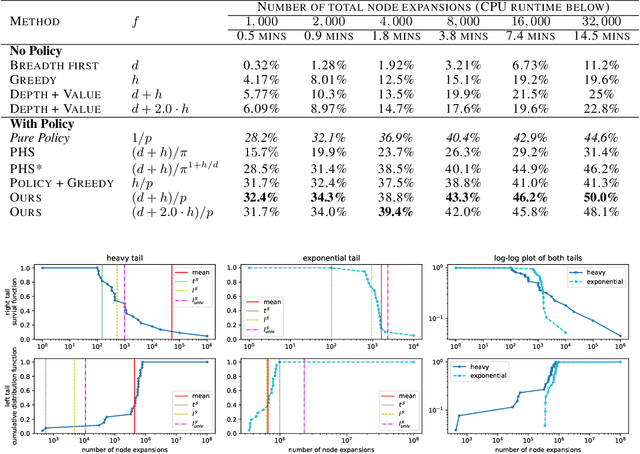
Despite the success of practical solvers in various NP-complete domains such as SAT and CSP as well as using deep reinforcement learning to tackle two-player games such as Go, certain classes of PSPACE-hard planning problems have remained out of reach. Even carefully designed domain-specialized solvers can fail quickly due to the exponential search space on hard instances. Recent works that combine traditional search methods, such as best-first search and Monte Carlo tree search, with Deep Neural Networks' (DNN) heuristics have shown promising progress and can solve a significant number of hard planning instances beyond specialized solvers. To better understand why these approaches work, we studied the interplay of the policy and value networks of DNN-based best-first search on Sokoban and show the surprising effectiveness of the policy network, further enhanced by the value network, as a guiding heuristic for the search. To further understand the phenomena, we studied the cost distribution of the search algorithms and found that Sokoban instances can have heavy-tailed runtime distributions, with tails both on the left and right-hand sides. In particular, for the first time, we show the existence of \textit{left heavy tails} and propose an abstract tree model that can empirically explain the appearance of these tails. The experiments show the critical role of the policy network as a powerful heuristic guiding the search, which can lead to left heavy tails with polynomial scaling by avoiding exploring exponentially sized subtrees. Our results also demonstrate the importance of random restarts, as are widely used in traditional combinatorial solvers, for DNN-based search methods to avoid left and right heavy tails.
A Novel Automated Curriculum Strategy to Solve Hard Sokoban Planning Instances
Oct 03, 2021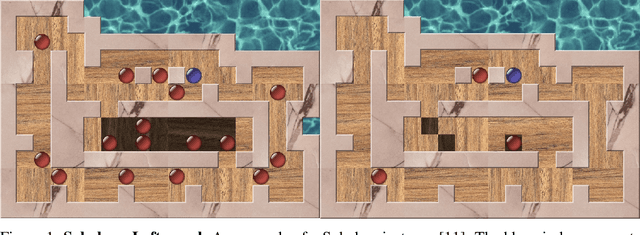


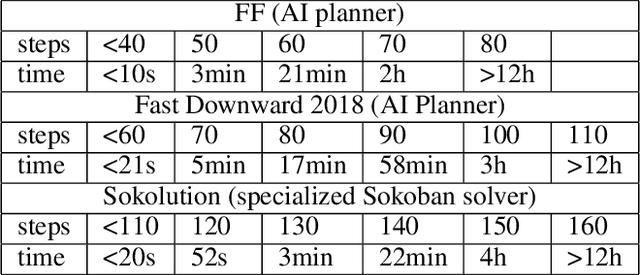
In recent years, we have witnessed tremendous progress in deep reinforcement learning (RL) for tasks such as Go, Chess, video games, and robot control. Nevertheless, other combinatorial domains, such as AI planning, still pose considerable challenges for RL approaches. The key difficulty in those domains is that a positive reward signal becomes {\em exponentially rare} as the minimal solution length increases. So, an RL approach loses its training signal. There has been promising recent progress by using a curriculum-driven learning approach that is designed to solve a single hard instance. We present a novel {\em automated} curriculum approach that dynamically selects from a pool of unlabeled training instances of varying task complexity guided by our {\em difficulty quantum momentum} strategy. We show how the smoothness of the task hardness impacts the final learning results. In particular, as the size of the instance pool increases, the ``hardness gap'' decreases, which facilitates a smoother automated curriculum based learning process. Our automated curriculum approach dramatically improves upon the previous approaches. We show our results on Sokoban, which is a traditional PSPACE-complete planning problem and presents a great challenge even for specialized solvers. Our RL agent can solve hard instances that are far out of reach for any previous state-of-the-art Sokoban solver. In particular, our approach can uncover plans that require hundreds of steps, while the best previous search methods would take many years of computing time to solve such instances. In addition, we show that we can further boost the RL performance with an intricate coupling of our automated curriculum approach with a curiosity-driven search strategy and a graph neural net representation.
Automating Crystal-Structure Phase Mapping: Combining Deep Learning with Constraint Reasoning
Aug 21, 2021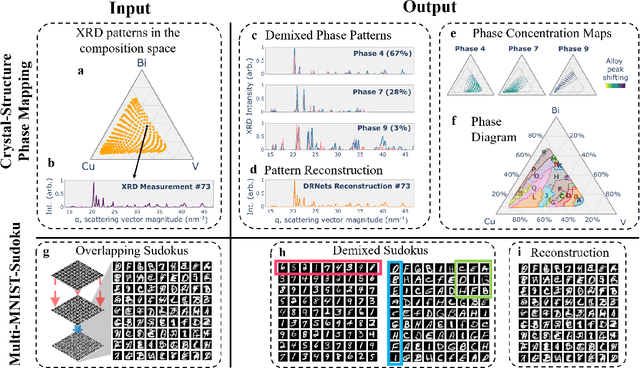
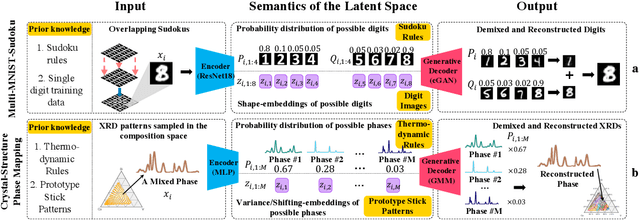

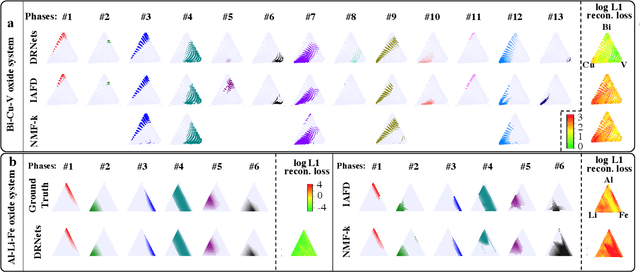
Crystal-structure phase mapping is a core, long-standing challenge in materials science that requires identifying crystal structures, or mixtures thereof, in synthesized materials. Materials science experts excel at solving simple systems but cannot solve complex systems, creating a major bottleneck in high-throughput materials discovery. Herein we show how to automate crystal-structure phase mapping. We formulate phase mapping as an unsupervised pattern demixing problem and describe how to solve it using Deep Reasoning Networks (DRNets). DRNets combine deep learning with constraint reasoning for incorporating scientific prior knowledge and consequently require only a modest amount of (unlabeled) data. DRNets compensate for the limited data by exploiting and magnifying the rich prior knowledge about the thermodynamic rules governing the mixtures of crystals with constraint reasoning seamlessly integrated into neural network optimization. DRNets are designed with an interpretable latent space for encoding prior-knowledge domain constraints and seamlessly integrate constraint reasoning into neural network optimization. DRNets surpass previous approaches on crystal-structure phase mapping, unraveling the Bi-Cu-V oxide phase diagram, and aiding the discovery of solar-fuels materials.
Structure Amplification on Multi-layer Stochastic Block Models
Jul 31, 2021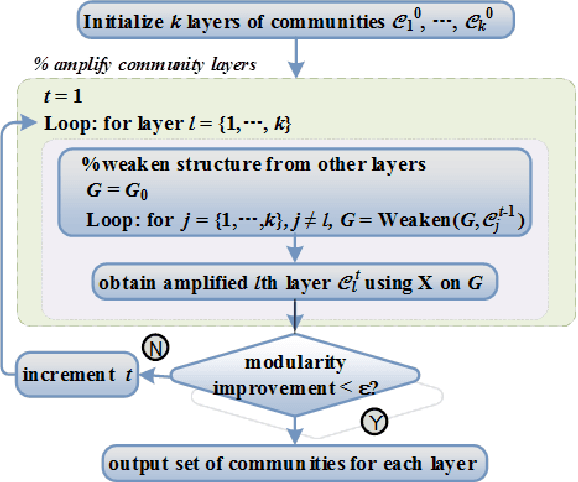
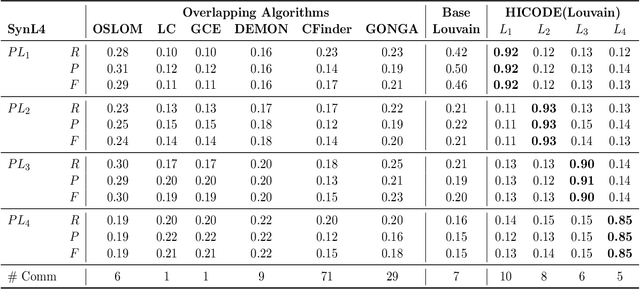

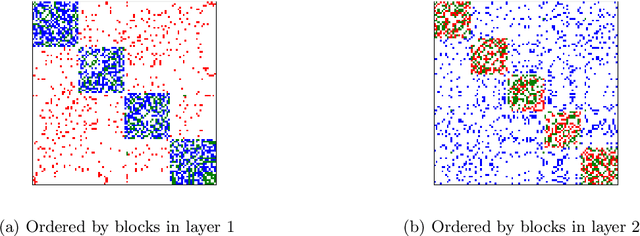
Much of the complexity of social, biological, and engineered systems arises from a network of complex interactions connecting many basic components. Network analysis tools have been successful at uncovering latent structure termed communities in such networks. However, some of the most interesting structure can be difficult to uncover because it is obscured by the more dominant structure. Our previous work proposes a general structure amplification technique called HICODE that uncovers many layers of functional hidden structure in complex networks. HICODE incrementally weakens dominant structure through randomization allowing the hidden functionality to emerge, and uncovers these hidden structure in real-world networks that previous methods rarely uncover. In this work, we conduct a comprehensive and systematic theoretical analysis on the hidden community structure. In what follows, we define multi-layer stochastic block model, and provide theoretical support using the model on why the existence of hidden structure will make the detection of dominant structure harder compared with equivalent random noise. We then provide theoretical proofs that the iterative reducing methods could help promote the uncovering of hidden structure as well as boosting the detection quality of dominant structure.
Curriculum-Driven Multi-Agent Learning and the Role of Implicit Communication in Teamwork
Jun 21, 2021

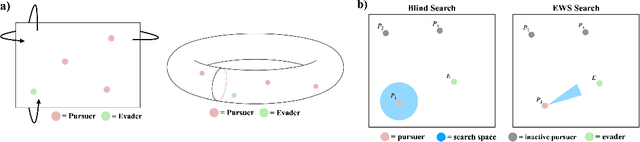
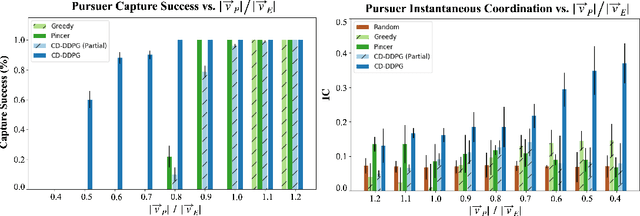
We propose a curriculum-driven learning strategy for solving difficult multi-agent coordination tasks. Our method is inspired by a study of animal communication, which shows that two straightforward design features (mutual reward and decentralization) support a vast spectrum of communication protocols in nature. We highlight the importance of similarly interpreting emergent communication as a spectrum. We introduce a toroidal, continuous-space pursuit-evasion environment and show that naive decentralized learning does not perform well. We then propose a novel curriculum-driven strategy for multi-agent learning. Experiments with pursuit-evasion show that our approach enables decentralized pursuers to learn to coordinate and capture a superior evader, significantly outperforming sophisticated analytical policies. We argue through additional quantitative analysis -- including influence-based measures such as Instantaneous Coordination -- that emergent implicit communication plays a large role in enabling superior levels of coordination.
Fairness for Cooperative Multi-Agent Learning with Equivariant Policies
Jun 10, 2021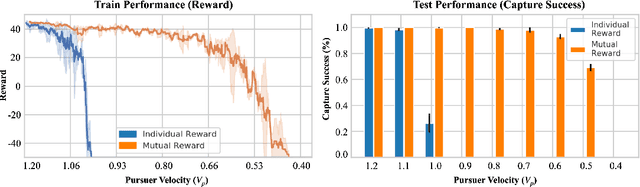
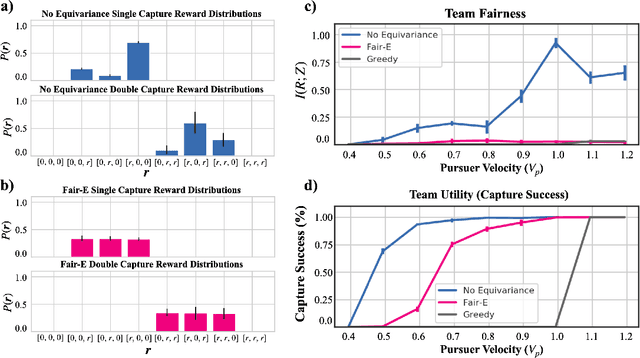
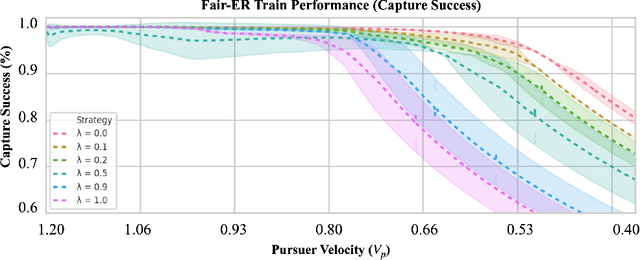
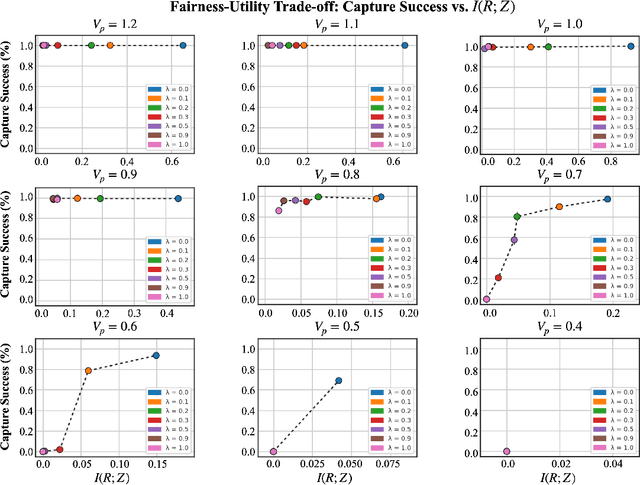
We study fairness through the lens of cooperative multi-agent learning. Our work is motivated by empirical evidence that naive maximization of team reward yields unfair outcomes for individual team members. To address fairness in multi-agent contexts, we introduce team fairness, a group-based fairness measure for multi-agent learning. We then incorporate team fairness into policy optimization -- introducing Fairness through Equivariance (Fair-E), a novel learning strategy that achieves provably fair reward distributions. We then introduce Fairness through Equivariance Regularization (Fair-ER) as a soft-constraint version of Fair-E and show that Fair-ER reaches higher levels of utility than Fair-E and fairer outcomes than policies with no equivariance. Finally, we investigate the fairness-utility trade-off in multi-agent settings.