 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA new perspective on building efficient and expressive 3D equivariant graph neural networks
Apr 07, 2023Geometric deep learning enables the encoding of physical symmetries in modeling 3D objects. Despite rapid progress in encoding 3D symmetries into Graph Neural Networks (GNNs), a comprehensive evaluation of the expressiveness of these networks through a local-to-global analysis lacks today. In this paper, we propose a local hierarchy of 3D isomorphism to evaluate the expressive power of equivariant GNNs and investigate the process of representing global geometric information from local patches. Our work leads to two crucial modules for designing expressive and efficient geometric GNNs; namely local substructure encoding (LSE) and frame transition encoding (FTE). To demonstrate the applicability of our theory, we propose LEFTNet which effectively implements these modules and achieves state-of-the-art performance on both scalar-valued and vector-valued molecular property prediction tasks. We further point out the design space for future developments of equivariant graph neural networks. Our codes are available at \url{https://github.com/yuanqidu/LeftNet}.
Graph Value Iteration
Sep 20, 2022

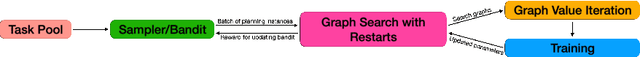

In recent years, deep Reinforcement Learning (RL) has been successful in various combinatorial search domains, such as two-player games and scientific discovery. However, directly applying deep RL in planning domains is still challenging. One major difficulty is that without a human-crafted heuristic function, reward signals remain zero unless the learning framework discovers any solution plan. Search space becomes \emph{exponentially larger} as the minimum length of plans grows, which is a serious limitation for planning instances with a minimum plan length of hundreds to thousands of steps. Previous learning frameworks that augment graph search with deep neural networks and extra generated subgoals have achieved success in various challenging planning domains. However, generating useful subgoals requires extensive domain knowledge. We propose a domain-independent method that augments graph search with graph value iteration to solve hard planning instances that are out of reach for domain-specialized solvers. In particular, instead of receiving learning signals only from discovered plans, our approach also learns from failed search attempts where no goal state has been reached. The graph value iteration component can exploit the graph structure of local search space and provide more informative learning signals. We also show how we use a curriculum strategy to smooth the learning process and perform a full analysis of how graph value iteration scales and enables learning.
Left Heavy Tails and the Effectiveness of the Policy and Value Networks in DNN-based best-first search for Sokoban Planning
Jun 28, 2022


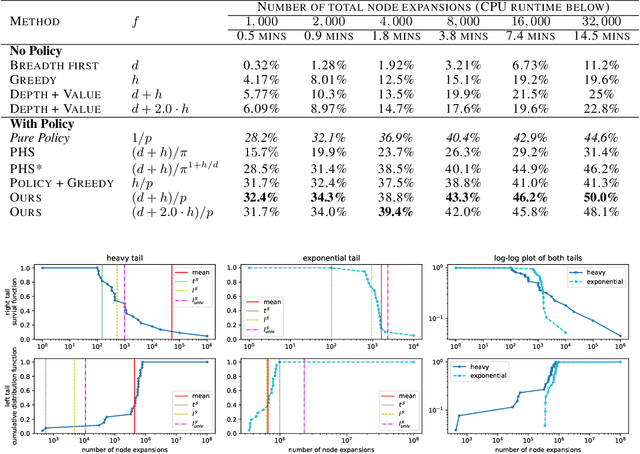
Despite the success of practical solvers in various NP-complete domains such as SAT and CSP as well as using deep reinforcement learning to tackle two-player games such as Go, certain classes of PSPACE-hard planning problems have remained out of reach. Even carefully designed domain-specialized solvers can fail quickly due to the exponential search space on hard instances. Recent works that combine traditional search methods, such as best-first search and Monte Carlo tree search, with Deep Neural Networks' (DNN) heuristics have shown promising progress and can solve a significant number of hard planning instances beyond specialized solvers. To better understand why these approaches work, we studied the interplay of the policy and value networks of DNN-based best-first search on Sokoban and show the surprising effectiveness of the policy network, further enhanced by the value network, as a guiding heuristic for the search. To further understand the phenomena, we studied the cost distribution of the search algorithms and found that Sokoban instances can have heavy-tailed runtime distributions, with tails both on the left and right-hand sides. In particular, for the first time, we show the existence of \textit{left heavy tails} and propose an abstract tree model that can empirically explain the appearance of these tails. The experiments show the critical role of the policy network as a powerful heuristic guiding the search, which can lead to left heavy tails with polynomial scaling by avoiding exploring exponentially sized subtrees. Our results also demonstrate the importance of random restarts, as are widely used in traditional combinatorial solvers, for DNN-based search methods to avoid left and right heavy tails.
A Novel Automated Curriculum Strategy to Solve Hard Sokoban Planning Instances
Oct 03, 2021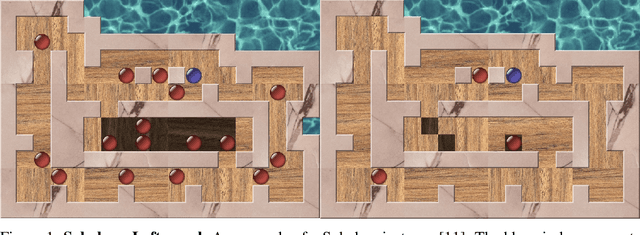


In recent years, we have witnessed tremendous progress in deep reinforcement learning (RL) for tasks such as Go, Chess, video games, and robot control. Nevertheless, other combinatorial domains, such as AI planning, still pose considerable challenges for RL approaches. The key difficulty in those domains is that a positive reward signal becomes {\em exponentially rare} as the minimal solution length increases. So, an RL approach loses its training signal. There has been promising recent progress by using a curriculum-driven learning approach that is designed to solve a single hard instance. We present a novel {\em automated} curriculum approach that dynamically selects from a pool of unlabeled training instances of varying task complexity guided by our {\em difficulty quantum momentum} strategy. We show how the smoothness of the task hardness impacts the final learning results. In particular, as the size of the instance pool increases, the ``hardness gap'' decreases, which facilitates a smoother automated curriculum based learning process. Our automated curriculum approach dramatically improves upon the previous approaches. We show our results on Sokoban, which is a traditional PSPACE-complete planning problem and presents a great challenge even for specialized solvers. Our RL agent can solve hard instances that are far out of reach for any previous state-of-the-art Sokoban solver. In particular, our approach can uncover plans that require hundreds of steps, while the best previous search methods would take many years of computing time to solve such instances. In addition, we show that we can further boost the RL performance with an intricate coupling of our automated curriculum approach with a curiosity-driven search strategy and a graph neural net representation.
Solving Hard AI Planning Instances Using Curriculum-Driven Deep Reinforcement Learning
Jun 04, 2020
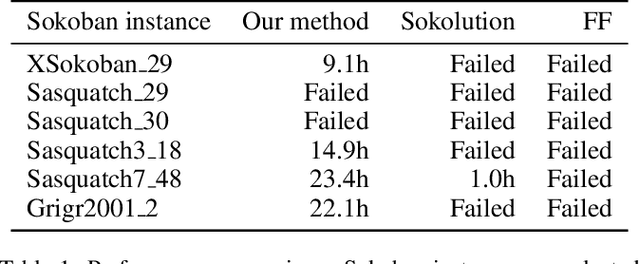

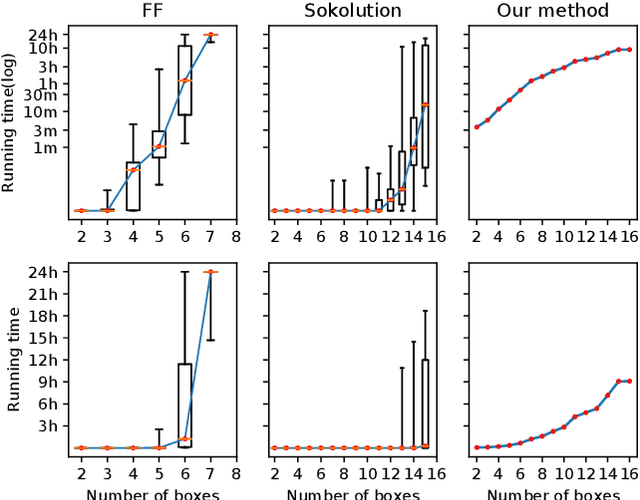
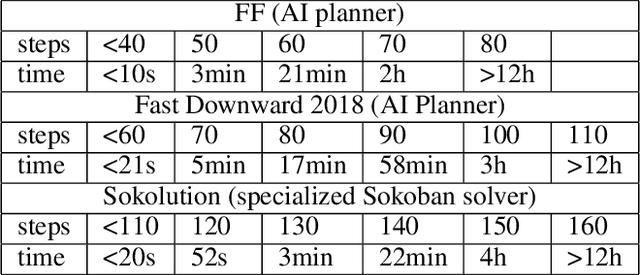
Despite significant progress in general AI planning, certain domains remain out of reach of current AI planning systems. Sokoban is a PSPACE-complete planning task and represents one of the hardest domains for current AI planners. Even domain-specific specialized search methods fail quickly due to the exponential search complexity on hard instances. Our approach based on deep reinforcement learning augmented with a curriculum-driven method is the first one to solve hard instances within one day of training while other modern solvers cannot solve these instances within any reasonable time limit. In contrast to prior efforts, which use carefully handcrafted pruning techniques, our approach automatically uncovers domain structure. Our results reveal that deep RL provides a promising framework for solving previously unsolved AI planning problems, provided a proper training curriculum can be devised.
GeneGAN: Learning Object Transfiguration and Attribute Subspace from Unpaired Data
May 14, 2017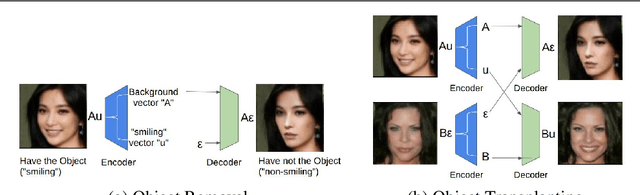
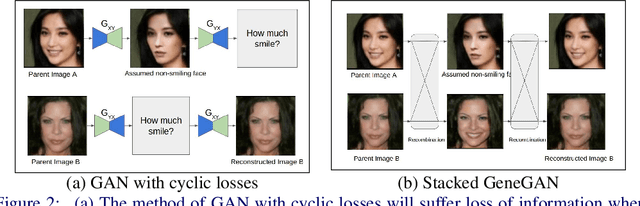
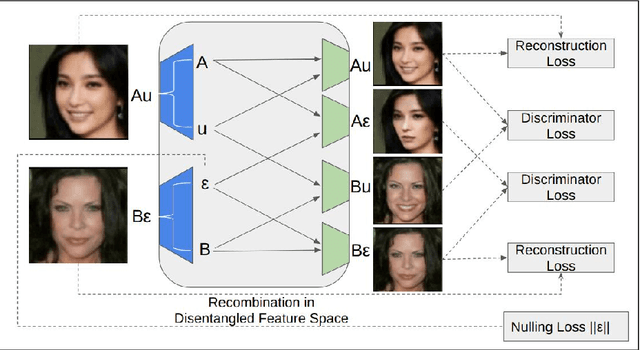

Object Transfiguration replaces an object in an image with another object from a second image. For example it can perform tasks like "putting exactly those eyeglasses from image A on the nose of the person in image B". Usage of exemplar images allows more precise specification of desired modifications and improves the diversity of conditional image generation. However, previous methods that rely on feature space operations, require paired data and/or appearance models for training or disentangling objects from background. In this work, we propose a model that can learn object transfiguration from two unpaired sets of images: one set containing images that "have" that kind of object, and the other set being the opposite, with the mild constraint that the objects be located approximately at the same place. For example, the training data can be one set of reference face images that have eyeglasses, and another set of images that have not, both of which spatially aligned by face landmarks. Despite the weak 0/1 labels, our model can learn an "eyeglasses" subspace that contain multiple representatives of different types of glasses. Consequently, we can perform fine-grained control of generated images, like swapping the glasses in two images by swapping the projected components in the "eyeglasses" subspace, to create novel images of people wearing eyeglasses. Overall, our deterministic generative model learns disentangled attribute subspaces from weakly labeled data by adversarial training. Experiments on CelebA and Multi-PIE datasets validate the effectiveness of the proposed model on real world data, in generating images with specified eyeglasses, smiling, hair styles, and lighting conditions etc. The code is available online.
Training Bit Fully Convolutional Network for Fast Semantic Segmentation
Dec 01, 2016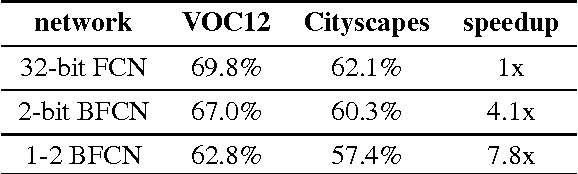
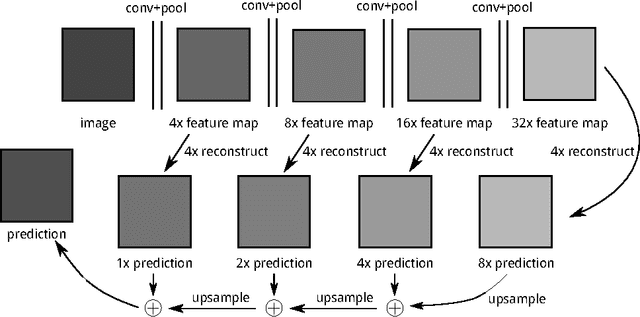
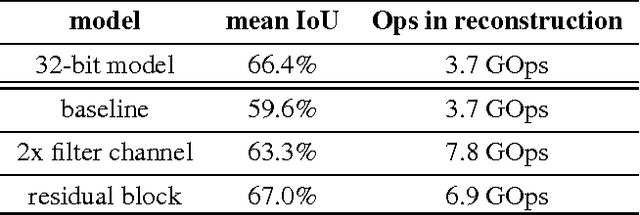
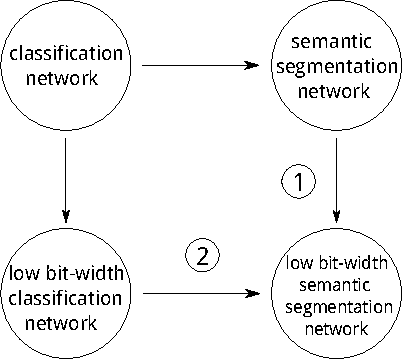
Fully convolutional neural networks give accurate, per-pixel prediction for input images and have applications like semantic segmentation. However, a typical FCN usually requires lots of floating point computation and large run-time memory, which effectively limits its usability. We propose a method to train Bit Fully Convolution Network (BFCN), a fully convolutional neural network that has low bit-width weights and activations. Because most of its computation-intensive convolutions are accomplished between low bit-width numbers, a BFCN can be accelerated by an efficient bit-convolution implementation. On CPU, the dot product operation between two bit vectors can be reduced to bitwise operations and popcounts, which can offer much higher throughput than 32-bit multiplications and additions. To validate the effectiveness of BFCN, we conduct experiments on the PASCAL VOC 2012 semantic segmentation task and Cityscapes. Our BFCN with 1-bit weights and 2-bit activations, which runs 7.8x faster on CPU or requires less than 1\% resources on FPGA, can achieve comparable performance as the 32-bit counterpart.