 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Apr 02, 2026High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
SHOW3D: Capturing Scenes of 3D Hands and Objects in the Wild
Mar 30, 2026Accurate 3D understanding of human hands and objects during manipulation remains a significant challenge for egocentric computer vision. Existing hand-object interaction datasets are predominantly captured in controlled studio settings, which limits both environmental diversity and the ability of models trained on such data to generalize to real-world scenarios. To address this challenge, we introduce a novel marker-less multi-camera system that allows for nearly unconstrained mobility in genuinely in-the-wild conditions, while still having the ability to generate precise 3D annotations of hands and objects. The capture system consists of a lightweight, back-mounted, multi-camera rig that is synchronized and calibrated with a user-worn VR headset. For 3D ground-truth annotation of hands and objects, we develop an ego-exo tracking pipeline and rigorously evaluate its quality. Finally, we present SHOW3D, the first large-scale dataset with 3D annotations that show hands interacting with objects in diverse real-world environments, including outdoor settings. Our approach significantly reduces the fundamental trade-off between environmental realism and accuracy of 3D annotations, which we validate with experiments on several downstream tasks. show3d-dataset.github.io
Lay-Your-Scene: Natural Scene Layout Generation with Diffusion Transformers
May 07, 2025



We present Lay-Your-Scene (shorthand LayouSyn), a novel text-to-layout generation pipeline for natural scenes. Prior scene layout generation methods are either closed-vocabulary or use proprietary large language models for open-vocabulary generation, limiting their modeling capabilities and broader applicability in controllable image generation. In this work, we propose to use lightweight open-source language models to obtain scene elements from text prompts and a novel aspect-aware diffusion Transformer architecture trained in an open-vocabulary manner for conditional layout generation. Extensive experiments demonstrate that LayouSyn outperforms existing methods and achieves state-of-the-art performance on challenging spatial and numerical reasoning benchmarks. Additionally, we present two applications of LayouSyn. First, we show that coarse initialization from large language models can be seamlessly combined with our method to achieve better results. Second, we present a pipeline for adding objects to images, demonstrating the potential of LayouSyn in image editing applications.
Automated Query-Product Relevance Labeling using Large Language Models for E-commerce Search
Feb 21, 2025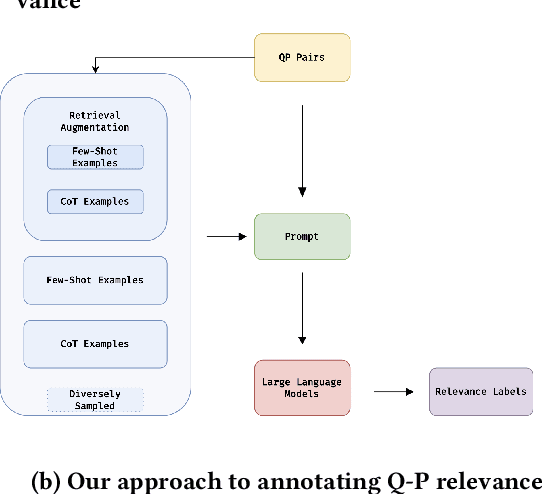
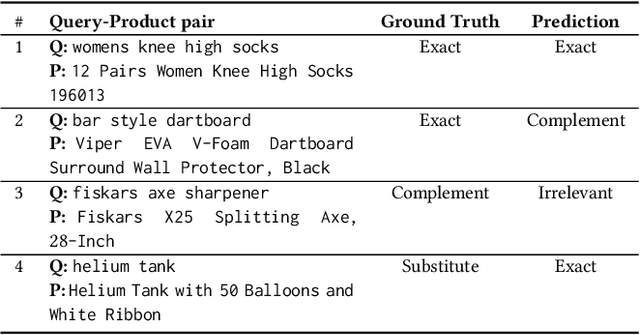
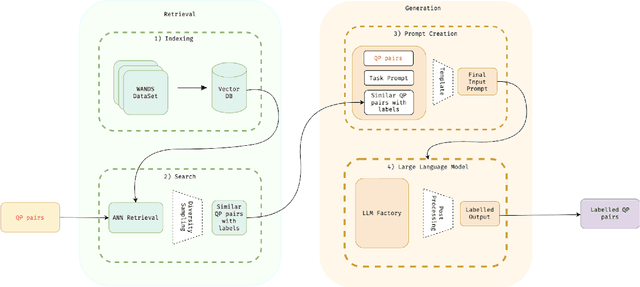

Accurate query-product relevance labeling is indispensable to generate ground truth dataset for search ranking in e-commerce. Traditional approaches for annotating query-product pairs rely on human-based labeling services, which is expensive, time-consuming and prone to errors. In this work, we explore the application of Large Language Models (LLMs) to automate query-product relevance labeling for large-scale e-commerce search. We use several publicly available and proprietary LLMs for this task, and conducted experiments on two open-source datasets and an in-house e-commerce search dataset. Using prompt engineering techniques such as Chain-of-Thought (CoT) prompting, In-context Learning (ICL), and Retrieval Augmented Generation (RAG) with Maximum Marginal Relevance (MMR), we show that LLM's performance has the potential to approach human-level accuracy on this task in a fraction of the time and cost required by human-labelers, thereby suggesting that our approach is more efficient than the conventional methods. We have generated query-product relevance labels using LLMs at scale, and are using them for evaluating improvements to our search algorithms. Our work demonstrates the potential of LLMs to improve query-product relevance thus enhancing e-commerce search user experience. More importantly, this scalable alternative to human-annotation has significant implications for information retrieval domains including search and recommendation systems, where relevance scoring is crucial for optimizing the ranking of products and content to improve customer engagement and other conversion metrics.
Rasterized Edge Gradients: Handling Discontinuities Differentiably
May 03, 2024



Computing the gradients of a rendering process is paramount for diverse applications in computer vision and graphics. However, accurate computation of these gradients is challenging due to discontinuities and rendering approximations, particularly for surface-based representations and rasterization-based rendering. We present a novel method for computing gradients at visibility discontinuities for rasterization-based differentiable renderers. Our method elegantly simplifies the traditionally complex problem through a carefully designed approximation strategy, allowing for a straightforward, effective, and performant solution. We introduce a novel concept of micro-edges, which allows us to treat the rasterized images as outcomes of a differentiable, continuous process aligned with the inherently non-differentiable, discrete-pixel rasterization. This technique eliminates the necessity for rendering approximations or other modifications to the forward pass, preserving the integrity of the rendered image, which makes it applicable to rasterized masks, depth, and normals images where filtering is prohibitive. Utilizing micro-edges simplifies gradient interpretation at discontinuities and enables handling of geometry intersections, offering an advantage over the prior art. We showcase our method in dynamic human head scene reconstruction, demonstrating effective handling of camera images and segmentation masks.
URHand: Universal Relightable Hands
Jan 10, 2024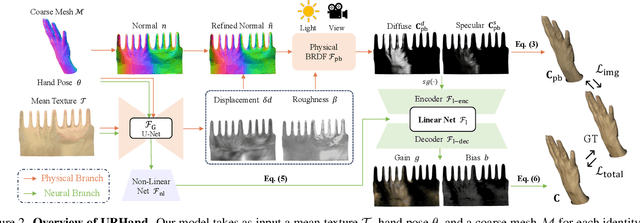
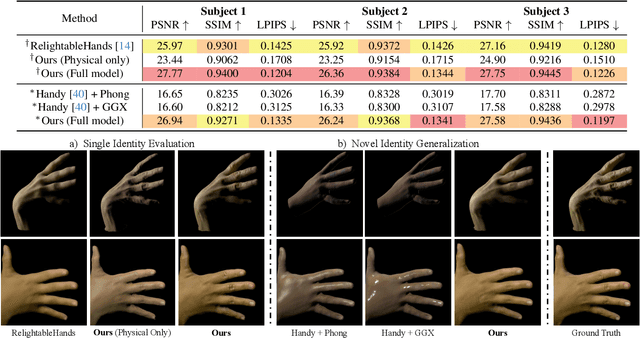
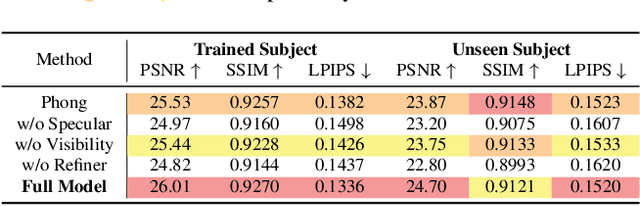
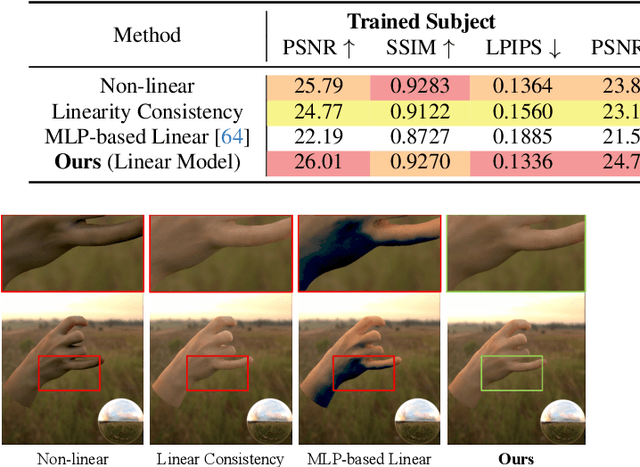
Existing photorealistic relightable hand models require extensive identity-specific observations in different views, poses, and illuminations, and face challenges in generalizing to natural illuminations and novel identities. To bridge this gap, we present URHand, the first universal relightable hand model that generalizes across viewpoints, poses, illuminations, and identities. Our model allows few-shot personalization using images captured with a mobile phone, and is ready to be photorealistically rendered under novel illuminations. To simplify the personalization process while retaining photorealism, we build a powerful universal relightable prior based on neural relighting from multi-view images of hands captured in a light stage with hundreds of identities. The key challenge is scaling the cross-identity training while maintaining personalized fidelity and sharp details without compromising generalization under natural illuminations. To this end, we propose a spatially varying linear lighting model as the neural renderer that takes physics-inspired shading as input feature. By removing non-linear activations and bias, our specifically designed lighting model explicitly keeps the linearity of light transport. This enables single-stage training from light-stage data while generalizing to real-time rendering under arbitrary continuous illuminations across diverse identities. In addition, we introduce the joint learning of a physically based model and our neural relighting model, which further improves fidelity and generalization. Extensive experiments show that our approach achieves superior performance over existing methods in terms of both quality and generalizability. We also demonstrate quick personalization of URHand from a short phone scan of an unseen identity.
RDBench: ML Benchmark for Relational Databases
Oct 30, 2023Benefiting from high-quality datasets and standardized evaluation metrics, machine learning (ML) has achieved sustained progress and widespread applications. However, while applying machine learning to relational databases (RDBs), the absence of a well-established benchmark remains a significant obstacle to the development of ML. To address this issue, we introduce ML Benchmark For Relational Databases (RDBench), a standardized benchmark that aims to promote reproducible ML research on RDBs that include multiple tables. RDBench offers diverse RDB datasets of varying scales, domains, and relational structures, organized into 4 levels. Notably, to simplify the adoption of RDBench for diverse ML domains, for any given database, RDBench exposes three types of interfaces including tabular data, homogeneous graphs, and heterogeneous graphs, sharing the same underlying task definition. For the first time, RDBench enables meaningful comparisons between ML methods from diverse domains, ranging from XGBoost to Graph Neural Networks, under RDB prediction tasks. We design multiple classification and regression tasks for each RDB dataset and report averaged results over the same dataset, further enhancing the robustness of the experimental findings. RDBench is implemented with DBGym, a user-friendly platform for ML research and application on databases, enabling benchmarking new ML methods with RDBench at ease.
Vulnerability Assessment of Industrial Control System with an Improved CVSS
Jun 14, 2023



Cyberattacks on industrial control systems (ICS) have been drawing attention in academia. However, this has not raised adequate concerns among some industrial practitioners. Therefore, it is necessary to identify the vulnerable locations and components in the ICS and investigate the attack scenarios and techniques. This study proposes a method to assess the risk of cyberattacks on ICS with an improved Common Vulnerability Scoring System (CVSS) and applies it to a continuous stirred tank reactor (CSTR) model. The results show the physical system levels of ICS have the highest severity once cyberattacked, and controllers, workstations, and human-machine interface are the crucial components in the cyberattack and defense.
The Digital Divide in Process Safety: Quantitative Risk Analysis of Human-AI Collaboration
May 29, 2023Digital technologies have dramatically accelerated the digital transformation in process industries, boosted new industrial applications, upgraded the production system, and enhanced operational efficiency. In contrast, the challenges and gaps between human and artificial intelligence (AI) have become more and more prominent, whereas the digital divide in process safety is aggregating. The study attempts to address the following questions: (i)What is AI in the process safety context? (ii)What is the difference between AI and humans in process safety? (iii)How do AI and humans collaborate in process safety? (iv)What are the challenges and gaps in human-AI collaboration? (v)How to quantify the risk of human-AI collaboration in process safety? Qualitative risk analysis based on brainstorming and literature review, and quantitative risk analysis based on layer of protection analysis (LOPA) and Bayesian network (BN), were applied to explore and model. The importance of human reliability should be stressed in the digital age, not usually to increase the reliability of AI, and human-centered AI design in process safety needs to be propagated.
Alert of the Second Decision-maker: An Introduction to Human-AI Conflict
May 25, 2023


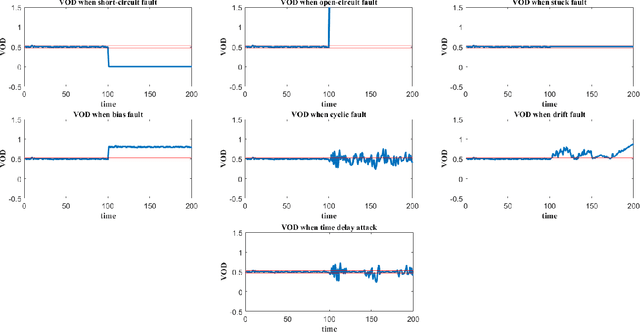
The collaboration between humans and artificial intelligence (AI) is a significant feature in this digital age. However, humans and AI may have observation, interpretation, and action conflicts when working synchronously. This phenomenon is often masked by faults and, unfortunately, overlooked. This paper systematically introduces the human-AI conflict concept, causes, measurement methods, and risk assessment. The results highlight that there is a potential second decision-maker besides the human, which is the AI; the human-AI conflict is a unique and emerging risk in digitalized process systems; and this is an interdisciplinary field that needs to be distinguished from traditional fault and failure analysis; the conflict risk is significant and cannot be ignored.