 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning with Pseudo-Labels for Multi-View 3D Pose Estimation
Paper and Code
Dec 27, 2021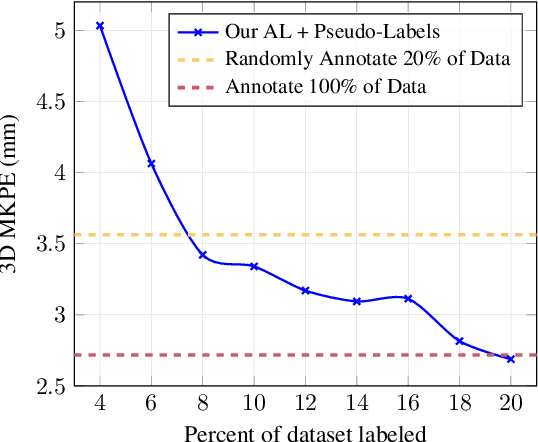
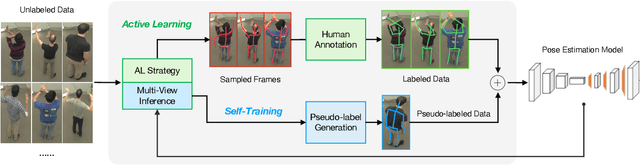
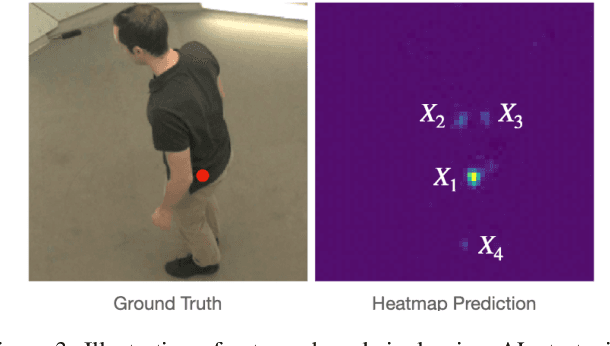
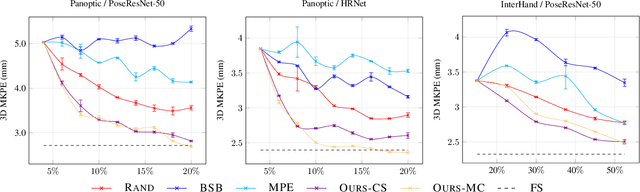
Pose estimation of the human body/hand is a fundamental problem in computer vision, and learning-based solutions require a large amount of annotated data. Given limited annotation budgets, a common approach to increasing label efficiency is Active Learning (AL), which selects examples with the highest value to annotate, but choosing the selection strategy is often nontrivial. In this work, we improve Active Learning for the problem of 3D pose estimation in a multi-view setting, which is of increasing importance in many application scenarios. We develop a framework that allows us to efficiently extend existing single-view AL strategies, and then propose two novel AL strategies that make full use of multi-view geometry. Moreover, we demonstrate additional performance gains by incorporating predicted pseudo-labels, which is a form of self-training. Our system significantly outperforms baselines in 3D body and hand pose estimation on two large-scale benchmarks: CMU Panoptic Studio and InterHand2.6M. Notably, on CMU Panoptic Studio, we are able to match the performance of a fully-supervised model using only 20% of labeled training data.