 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Apr 02, 2026High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
FRESA:Feedforward Reconstruction of Personalized Skinned Avatars from Few Images
Mar 24, 2025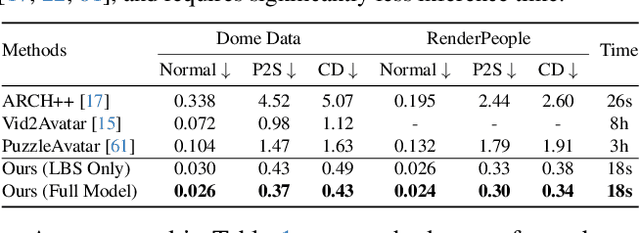
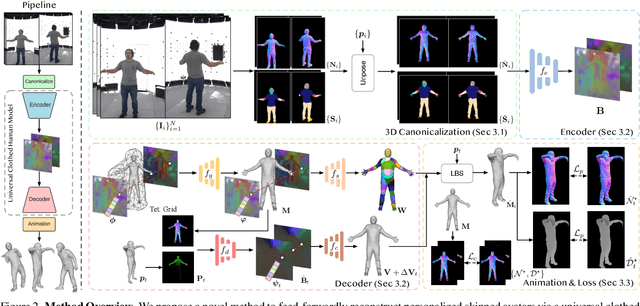
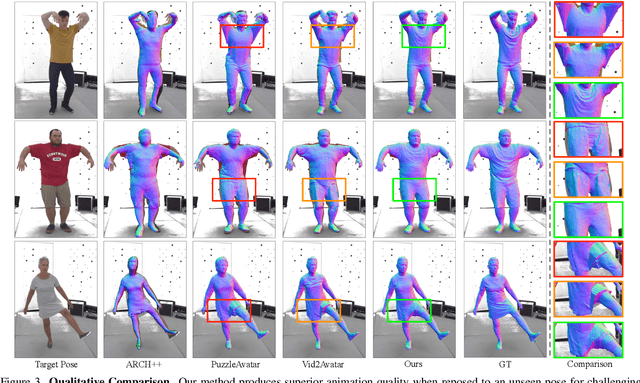
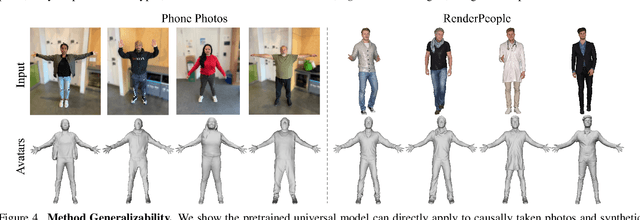
We present a novel method for reconstructing personalized 3D human avatars with realistic animation from only a few images. Due to the large variations in body shapes, poses, and cloth types, existing methods mostly require hours of per-subject optimization during inference, which limits their practical applications. In contrast, we learn a universal prior from over a thousand clothed humans to achieve instant feedforward generation and zero-shot generalization. Specifically, instead of rigging the avatar with shared skinning weights, we jointly infer personalized avatar shape, skinning weights, and pose-dependent deformations, which effectively improves overall geometric fidelity and reduces deformation artifacts. Moreover, to normalize pose variations and resolve coupled ambiguity between canonical shapes and skinning weights, we design a 3D canonicalization process to produce pixel-aligned initial conditions, which helps to reconstruct fine-grained geometric details. We then propose a multi-frame feature aggregation to robustly reduce artifacts introduced in canonicalization and fuse a plausible avatar preserving person-specific identities. Finally, we train the model in an end-to-end framework on a large-scale capture dataset, which contains diverse human subjects paired with high-quality 3D scans. Extensive experiments show that our method generates more authentic reconstruction and animation than state-of-the-arts, and can be directly generalized to inputs from casually taken phone photos. Project page and code is available at https://github.com/rongakowang/FRESA.
Vid2Avatar-Pro: Authentic Avatar from Videos in the Wild via Universal Prior
Mar 03, 2025We present Vid2Avatar-Pro, a method to create photorealistic and animatable 3D human avatars from monocular in-the-wild videos. Building a high-quality avatar that supports animation with diverse poses from a monocular video is challenging because the observation of pose diversity and view points is inherently limited. The lack of pose variations typically leads to poor generalization to novel poses, and avatars can easily overfit to limited input view points, producing artifacts and distortions from other views. In this work, we address these limitations by leveraging a universal prior model (UPM) learned from a large corpus of multi-view clothed human performance capture data. We build our representation on top of expressive 3D Gaussians with canonical front and back maps shared across identities. Once the UPM is learned to accurately reproduce the large-scale multi-view human images, we fine-tune the model with an in-the-wild video via inverse rendering to obtain a personalized photorealistic human avatar that can be faithfully animated to novel human motions and rendered from novel views. The experiments show that our approach based on the learned universal prior sets a new state-of-the-art in monocular avatar reconstruction by substantially outperforming existing approaches relying only on heuristic regularization or a shape prior of minimally clothed bodies (e.g., SMPL) on publicly available datasets.
URAvatar: Universal Relightable Gaussian Codec Avatars
Oct 31, 2024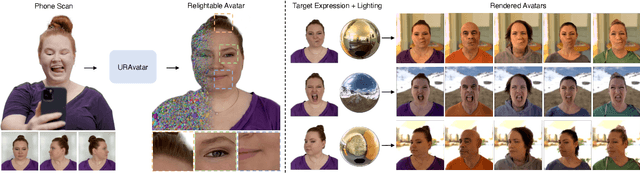

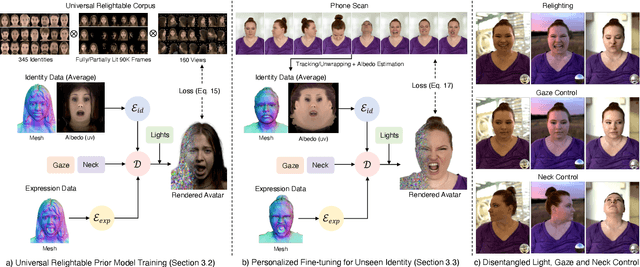
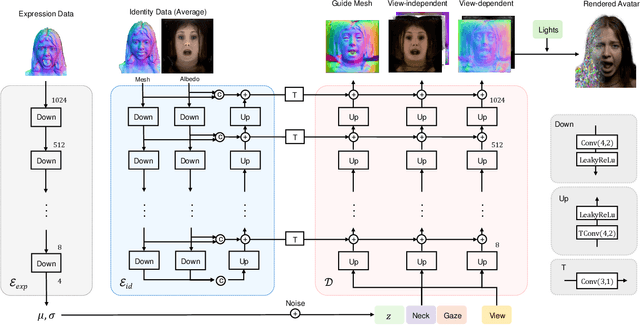
We present a new approach to creating photorealistic and relightable head avatars from a phone scan with unknown illumination. The reconstructed avatars can be animated and relit in real time with the global illumination of diverse environments. Unlike existing approaches that estimate parametric reflectance parameters via inverse rendering, our approach directly models learnable radiance transfer that incorporates global light transport in an efficient manner for real-time rendering. However, learning such a complex light transport that can generalize across identities is non-trivial. A phone scan in a single environment lacks sufficient information to infer how the head would appear in general environments. To address this, we build a universal relightable avatar model represented by 3D Gaussians. We train on hundreds of high-quality multi-view human scans with controllable point lights. High-resolution geometric guidance further enhances the reconstruction accuracy and generalization. Once trained, we finetune the pretrained model on a phone scan using inverse rendering to obtain a personalized relightable avatar. Our experiments establish the efficacy of our design, outperforming existing approaches while retaining real-time rendering capability.
Universal Facial Encoding of Codec Avatars from VR Headsets
Jul 17, 2024



Faithful real-time facial animation is essential for avatar-mediated telepresence in Virtual Reality (VR). To emulate authentic communication, avatar animation needs to be efficient and accurate: able to capture both extreme and subtle expressions within a few milliseconds to sustain the rhythm of natural conversations. The oblique and incomplete views of the face, variability in the donning of headsets, and illumination variation due to the environment are some of the unique challenges in generalization to unseen faces. In this paper, we present a method that can animate a photorealistic avatar in realtime from head-mounted cameras (HMCs) on a consumer VR headset. We present a self-supervised learning approach, based on a cross-view reconstruction objective, that enables generalization to unseen users. We present a lightweight expression calibration mechanism that increases accuracy with minimal additional cost to run-time efficiency. We present an improved parameterization for precise ground-truth generation that provides robustness to environmental variation. The resulting system produces accurate facial animation for unseen users wearing VR headsets in realtime. We compare our approach to prior face-encoding methods demonstrating significant improvements in both quantitative metrics and qualitative results.
* SIGGRAPH 2024 (ACM Transactions on Graphics (TOG))
Rasterized Edge Gradients: Handling Discontinuities Differentiably
May 03, 2024



Computing the gradients of a rendering process is paramount for diverse applications in computer vision and graphics. However, accurate computation of these gradients is challenging due to discontinuities and rendering approximations, particularly for surface-based representations and rasterization-based rendering. We present a novel method for computing gradients at visibility discontinuities for rasterization-based differentiable renderers. Our method elegantly simplifies the traditionally complex problem through a carefully designed approximation strategy, allowing for a straightforward, effective, and performant solution. We introduce a novel concept of micro-edges, which allows us to treat the rasterized images as outcomes of a differentiable, continuous process aligned with the inherently non-differentiable, discrete-pixel rasterization. This technique eliminates the necessity for rendering approximations or other modifications to the forward pass, preserving the integrity of the rendered image, which makes it applicable to rasterized masks, depth, and normals images where filtering is prohibitive. Utilizing micro-edges simplifies gradient interpretation at discontinuities and enables handling of geometry intersections, offering an advantage over the prior art. We showcase our method in dynamic human head scene reconstruction, demonstrating effective handling of camera images and segmentation masks.
URHand: Universal Relightable Hands
Jan 10, 2024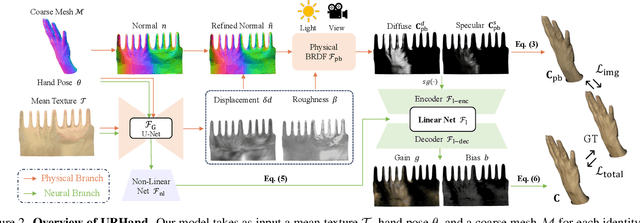
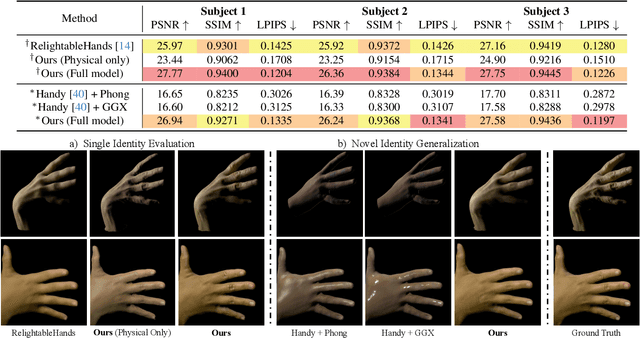
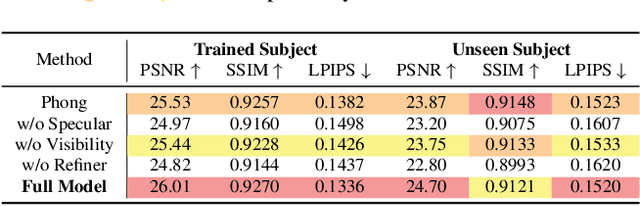
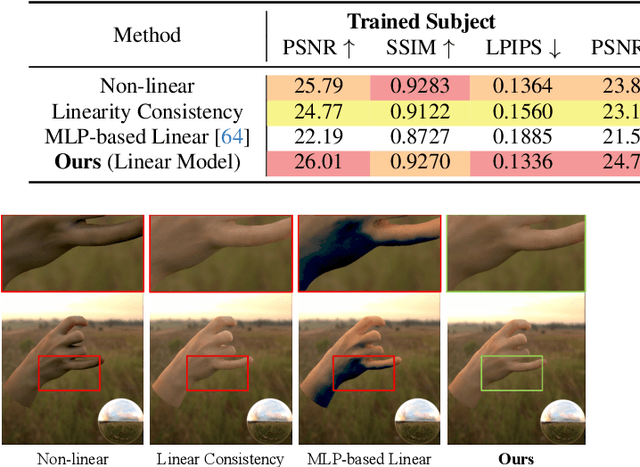
Existing photorealistic relightable hand models require extensive identity-specific observations in different views, poses, and illuminations, and face challenges in generalizing to natural illuminations and novel identities. To bridge this gap, we present URHand, the first universal relightable hand model that generalizes across viewpoints, poses, illuminations, and identities. Our model allows few-shot personalization using images captured with a mobile phone, and is ready to be photorealistically rendered under novel illuminations. To simplify the personalization process while retaining photorealism, we build a powerful universal relightable prior based on neural relighting from multi-view images of hands captured in a light stage with hundreds of identities. The key challenge is scaling the cross-identity training while maintaining personalized fidelity and sharp details without compromising generalization under natural illuminations. To this end, we propose a spatially varying linear lighting model as the neural renderer that takes physics-inspired shading as input feature. By removing non-linear activations and bias, our specifically designed lighting model explicitly keeps the linearity of light transport. This enables single-stage training from light-stage data while generalizing to real-time rendering under arbitrary continuous illuminations across diverse identities. In addition, we introduce the joint learning of a physically based model and our neural relighting model, which further improves fidelity and generalization. Extensive experiments show that our approach achieves superior performance over existing methods in terms of both quality and generalizability. We also demonstrate quick personalization of URHand from a short phone scan of an unseen identity.
RelightableHands: Efficient Neural Relighting of Articulated Hand Models
Feb 09, 2023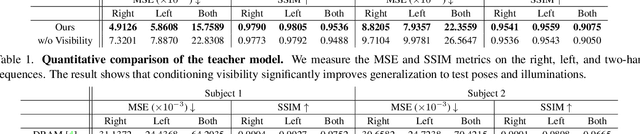
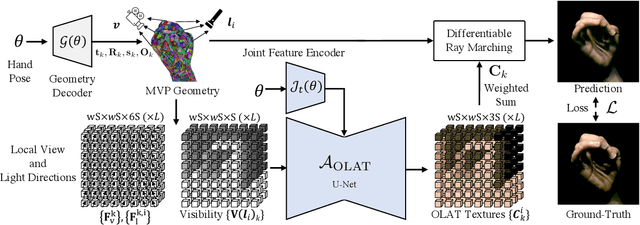

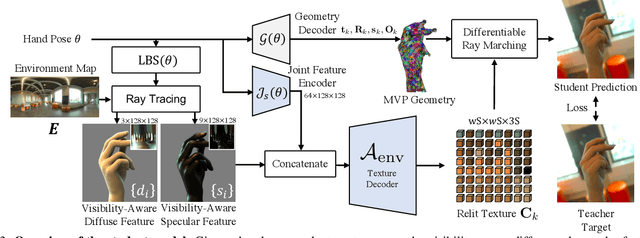
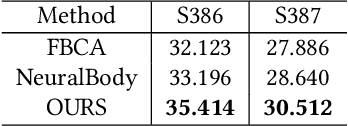
We present the first neural relighting approach for rendering high-fidelity personalized hands that can be animated in real-time under novel illumination. Our approach adopts a teacher-student framework, where the teacher learns appearance under a single point light from images captured in a light-stage, allowing us to synthesize hands in arbitrary illuminations but with heavy compute. Using images rendered by the teacher model as training data, an efficient student model directly predicts appearance under natural illuminations in real-time. To achieve generalization, we condition the student model with physics-inspired illumination features such as visibility, diffuse shading, and specular reflections computed on a coarse proxy geometry, maintaining a small computational overhead. Our key insight is that these features have strong correlation with subsequent global light transport effects, which proves sufficient as conditioning data for the neural relighting network. Moreover, in contrast to bottleneck illumination conditioning, these features are spatially aligned based on underlying geometry, leading to better generalization to unseen illuminations and poses. In our experiments, we demonstrate the efficacy of our illumination feature representations, outperforming baseline approaches. We also show that our approach can photorealistically relight two interacting hands at real-time speeds. https://sh8.io/#/relightable_hands
Multiface: A Dataset for Neural Face Rendering
Jul 22, 2022



Photorealistic avatars of human faces have come a long way in recent years, yet research along this area is limited by a lack of publicly available, high-quality datasets covering both, dense multi-view camera captures, and rich facial expressions of the captured subjects. In this work, we present Multiface, a new multi-view, high-resolution human face dataset collected from 13 identities at Reality Labs Research for neural face rendering. We introduce Mugsy, a large scale multi-camera apparatus to capture high-resolution synchronized videos of a facial performance. The goal of Multiface is to close the gap in accessibility to high quality data in the academic community and to enable research in VR telepresence. Along with the release of the dataset, we conduct ablation studies on the influence of different model architectures toward the model's interpolation capacity of novel viewpoint and expressions. With a conditional VAE model serving as our baseline, we found that adding spatial bias, texture warp field, and residual connections improves performance on novel view synthesis. Our code and data is available at: https://github.com/facebookresearch/multiface
Drivable Volumetric Avatars using Texel-Aligned Features
Jul 20, 2022
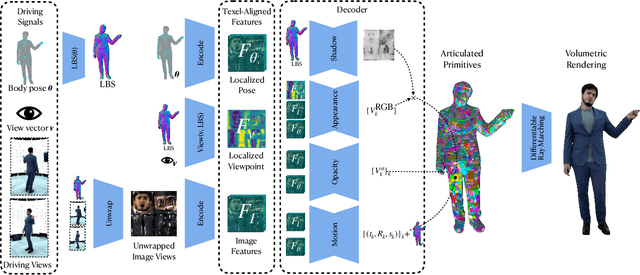
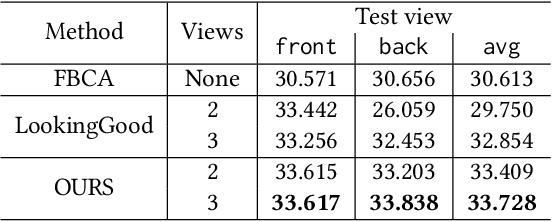
Photorealistic telepresence requires both high-fidelity body modeling and faithful driving to enable dynamically synthesized appearance that is indistinguishable from reality. In this work, we propose an end-to-end framework that addresses two core challenges in modeling and driving full-body avatars of real people. One challenge is driving an avatar while staying faithful to details and dynamics that cannot be captured by a global low-dimensional parameterization such as body pose. Our approach supports driving of clothed avatars with wrinkles and motion that a real driving performer exhibits beyond the training corpus. Unlike existing global state representations or non-parametric screen-space approaches, we introduce texel-aligned features -- a localised representation which can leverage both the structural prior of a skeleton-based parametric model and observed sparse image signals at the same time. Another challenge is modeling a temporally coherent clothed avatar, which typically requires precise surface tracking. To circumvent this, we propose a novel volumetric avatar representation by extending mixtures of volumetric primitives to articulated objects. By explicitly incorporating articulation, our approach naturally generalizes to unseen poses. We also introduce a localized viewpoint conditioning, which leads to a large improvement in generalization of view-dependent appearance. The proposed volumetric representation does not require high-quality mesh tracking as a prerequisite and brings significant quality improvements compared to mesh-based counterparts. In our experiments, we carefully examine our design choices and demonstrate the efficacy of our approach, outperforming the state-of-the-art methods on challenging driving scenarios.