 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURHand: Universal Relightable Hands
Jan 10, 2024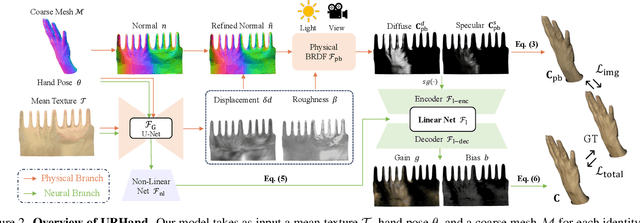
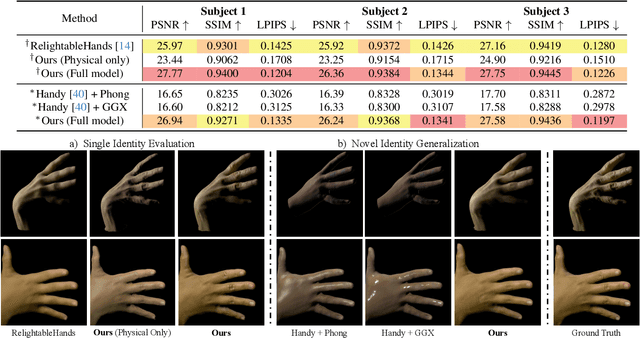
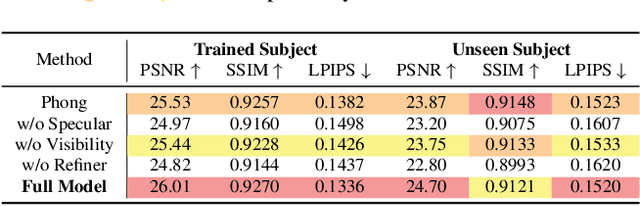
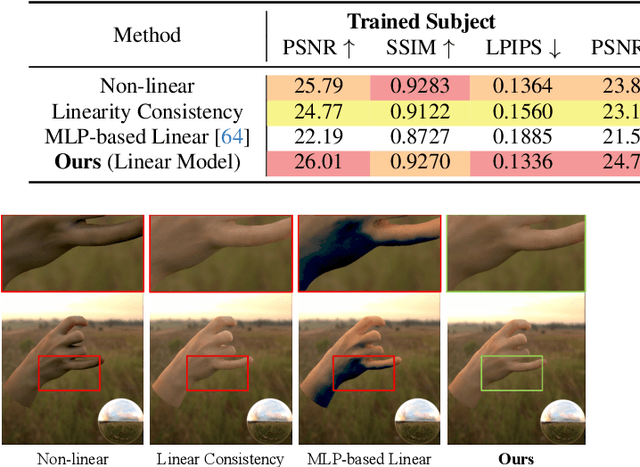
Existing photorealistic relightable hand models require extensive identity-specific observations in different views, poses, and illuminations, and face challenges in generalizing to natural illuminations and novel identities. To bridge this gap, we present URHand, the first universal relightable hand model that generalizes across viewpoints, poses, illuminations, and identities. Our model allows few-shot personalization using images captured with a mobile phone, and is ready to be photorealistically rendered under novel illuminations. To simplify the personalization process while retaining photorealism, we build a powerful universal relightable prior based on neural relighting from multi-view images of hands captured in a light stage with hundreds of identities. The key challenge is scaling the cross-identity training while maintaining personalized fidelity and sharp details without compromising generalization under natural illuminations. To this end, we propose a spatially varying linear lighting model as the neural renderer that takes physics-inspired shading as input feature. By removing non-linear activations and bias, our specifically designed lighting model explicitly keeps the linearity of light transport. This enables single-stage training from light-stage data while generalizing to real-time rendering under arbitrary continuous illuminations across diverse identities. In addition, we introduce the joint learning of a physically based model and our neural relighting model, which further improves fidelity and generalization. Extensive experiments show that our approach achieves superior performance over existing methods in terms of both quality and generalizability. We also demonstrate quick personalization of URHand from a short phone scan of an unseen identity.
Multiface: A Dataset for Neural Face Rendering
Jul 22, 2022



Photorealistic avatars of human faces have come a long way in recent years, yet research along this area is limited by a lack of publicly available, high-quality datasets covering both, dense multi-view camera captures, and rich facial expressions of the captured subjects. In this work, we present Multiface, a new multi-view, high-resolution human face dataset collected from 13 identities at Reality Labs Research for neural face rendering. We introduce Mugsy, a large scale multi-camera apparatus to capture high-resolution synchronized videos of a facial performance. The goal of Multiface is to close the gap in accessibility to high quality data in the academic community and to enable research in VR telepresence. Along with the release of the dataset, we conduct ablation studies on the influence of different model architectures toward the model's interpolation capacity of novel viewpoint and expressions. With a conditional VAE model serving as our baseline, we found that adding spatial bias, texture warp field, and residual connections improves performance on novel view synthesis. Our code and data is available at: https://github.com/facebookresearch/multiface