 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKinema4D: Kinematic 4D World Modeling for Spatiotemporal Embodied Simulation
Mar 17, 2026Simulating robot-world interactions is a cornerstone of Embodied AI. Recently, a few works have shown promise in leveraging video generations to transcend the rigid visual/physical constraints of traditional simulators. However, they primarily operate in 2D space or are guided by static environmental cues, ignoring the fundamental reality that robot-world interactions are inherently 4D spatiotemporal events that require precise interactive modeling. To restore this 4D essence while ensuring the precise robot control, we introduce Kinema4D, a new action-conditioned 4D generative robotic simulator that disentangles the robot-world interaction into: i) Precise 4D representation of robot controls: we drive a URDF-based 3D robot via kinematics, producing a precise 4D robot control trajectory. ii) Generative 4D modeling of environmental reactions: we project the 4D robot trajectory into a pointmap as a spatiotemporal visual signal, controlling the generative model to synthesize complex environments' reactive dynamics into synchronized RGB/pointmap sequences. To facilitate training, we curated a large-scale dataset called Robo4D-200k, comprising 201,426 robot interaction episodes with high-quality 4D annotations. Extensive experiments demonstrate that our method effectively simulates physically-plausible, geometry-consistent, and embodiment-agnostic interactions that faithfully mirror diverse real-world dynamics. For the first time, it shows potential zero-shot transfer capability, providing a high-fidelity foundation for advancing next-generation embodied simulation.
HSImul3R: Physics-in-the-Loop Reconstruction of Simulation-Ready Human-Scene Interactions
Mar 16, 2026We present HSImul3R, a unified framework for simulation-ready 3D reconstruction of human-scene interactions (HSI) from casual captures, including sparse-view images and monocular videos. Existing methods suffer from a perception-simulation gap: visually plausible reconstructions often violate physical constraints, leading to instability in physics engines and failure in embodied AI applications. To bridge this gap, we introduce a physically-grounded bi-directional optimization pipeline that treats the physics simulator as an active supervisor to jointly refine human dynamics and scene geometry. In the forward direction, we employ Scene-targeted Reinforcement Learning to optimize human motion under dual supervision of motion fidelity and contact stability. In the reverse direction, we propose Direct Simulation Reward Optimization, which leverages simulation feedback on gravitational stability and interaction success to refine scene geometry. We further present HSIBench, a new benchmark with diverse objects and interaction scenarios. Extensive experiments demonstrate that HSImul3R produces the first stable, simulation-ready HSI reconstructions and can be directly deployed to real-world humanoid robots.
ArtHOI: Articulated Human-Object Interaction Synthesis by 4D Reconstruction from Video Priors
Mar 04, 2026Synthesizing physically plausible articulated human-object interactions (HOI) without 3D/4D supervision remains a fundamental challenge. While recent zero-shot approaches leverage video diffusion models to synthesize human-object interactions, they are largely confined to rigid-object manipulation and lack explicit 4D geometric reasoning. To bridge this gap, we formulate articulated HOI synthesis as a 4D reconstruction problem from monocular video priors: given only a video generated by a diffusion model, we reconstruct a full 4D articulated scene without any 3D supervision. This reconstruction-based approach treats the generated 2D video as supervision for an inverse rendering problem, recovering geometrically consistent and physically plausible 4D scenes that naturally respect contact, articulation, and temporal coherence. We introduce ArtHOI, the first zero-shot framework for articulated human-object interaction synthesis via 4D reconstruction from video priors. Our key designs are: 1) Flow-based part segmentation: leveraging optical flow as a geometric cue to disentangle dynamic from static regions in monocular video; 2) Decoupled reconstruction pipeline: joint optimization of human motion and object articulation is unstable under monocular ambiguity, so we first recover object articulation, then synthesize human motion conditioned on the reconstructed object states. ArtHOI bridges video-based generation and geometry-aware reconstruction, producing interactions that are both semantically aligned and physically grounded. Across diverse articulated scenes (e.g., opening fridges, cabinets, microwaves), ArtHOI significantly outperforms prior methods in contact accuracy, penetration reduction, and articulation fidelity, extending zero-shot interaction synthesis beyond rigid manipulation through reconstruction-informed synthesis.
PI-Light: Physics-Inspired Diffusion for Full-Image Relighting
Jan 29, 2026Full-image relighting remains a challenging problem due to the difficulty of collecting large-scale structured paired data, the difficulty of maintaining physical plausibility, and the limited generalizability imposed by data-driven priors. Existing attempts to bridge the synthetic-to-real gap for full-scene relighting remain suboptimal. To tackle these challenges, we introduce Physics-Inspired diffusion for full-image reLight ($π$-Light, or PI-Light), a two-stage framework that leverages physics-inspired diffusion models. Our design incorporates (i) batch-aware attention, which improves the consistency of intrinsic predictions across a collection of images, (ii) a physics-guided neural rendering module that enforces physically plausible light transport, (iii) physics-inspired losses that regularize training dynamics toward a physically meaningful landscape, thereby enhancing generalizability to real-world image editing, and (iv) a carefully curated dataset of diverse objects and scenes captured under controlled lighting conditions. Together, these components enable efficient finetuning of pretrained diffusion models while also providing a solid benchmark for downstream evaluation. Experiments demonstrate that $π$-Light synthesizes specular highlights and diffuse reflections across a wide variety of materials, achieving superior generalization to real-world scenes compared with prior approaches.
DynamicVLA: A Vision-Language-Action Model for Dynamic Object Manipulation
Jan 29, 2026Manipulating dynamic objects remains an open challenge for Vision-Language-Action (VLA) models, which, despite strong generalization in static manipulation, struggle in dynamic scenarios requiring rapid perception, temporal anticipation, and continuous control. We present DynamicVLA, a framework for dynamic object manipulation that integrates temporal reasoning and closed-loop adaptation through three key designs: 1) a compact 0.4B VLA using a convolutional vision encoder for spatially efficient, structurally faithful encoding, enabling fast multimodal inference; 2) Continuous Inference, enabling overlapping reasoning and execution for lower latency and timely adaptation to object motion; and 3) Latent-aware Action Streaming, which bridges the perception-execution gap by enforcing temporally aligned action execution. To fill the missing foundation of dynamic manipulation data, we introduce the Dynamic Object Manipulation (DOM) benchmark, built from scratch with an auto data collection pipeline that efficiently gathers 200K synthetic episodes across 2.8K scenes and 206 objects, and enables fast collection of 2K real-world episodes without teleoperation. Extensive evaluations demonstrate remarkable improvements in response speed, perception, and generalization, positioning DynamicVLA as a unified framework for general dynamic object manipulation across embodiments.
OnlineSI: Taming Large Language Model for Online 3D Understanding and Grounding
Jan 23, 2026In recent years, researchers have increasingly been interested in how to enable Multimodal Large Language Models (MLLM) to possess spatial understanding and reasoning capabilities. However, most existing methods overlook the importance of the ability to continuously work in an ever-changing world, and lack the possibility of deployment on embodied systems in real-world environments. In this work, we introduce OnlineSI, a framework that can continuously improve its spatial understanding of its surroundings given a video stream. Our core idea is to maintain a finite spatial memory to retain past observations, ensuring the computation required for each inference does not increase as the input accumulates. We further integrate 3D point cloud information with semantic information, helping MLLM to better locate and identify objects in the scene. To evaluate our method, we introduce the Fuzzy $F_1$-Score to mitigate ambiguity, and test our method on two representative datasets. Experiments demonstrate the effectiveness of our method, paving the way towards real-world embodied systems.
LongVie 2: Multimodal Controllable Ultra-Long Video World Model
Dec 15, 2025Building video world models upon pretrained video generation systems represents an important yet challenging step toward general spatiotemporal intelligence. A world model should possess three essential properties: controllability, long-term visual quality, and temporal consistency. To this end, we take a progressive approach-first enhancing controllability and then extending toward long-term, high-quality generation. We present LongVie 2, an end-to-end autoregressive framework trained in three stages: (1) Multi-modal guidance, which integrates dense and sparse control signals to provide implicit world-level supervision and improve controllability; (2) Degradation-aware training on the input frame, bridging the gap between training and long-term inference to maintain high visual quality; and (3) History-context guidance, which aligns contextual information across adjacent clips to ensure temporal consistency. We further introduce LongVGenBench, a comprehensive benchmark comprising 100 high-resolution one-minute videos covering diverse real-world and synthetic environments. Extensive experiments demonstrate that LongVie 2 achieves state-of-the-art performance in long-range controllability, temporal coherence, and visual fidelity, and supports continuous video generation lasting up to five minutes, marking a significant step toward unified video world modeling.
PhysX-Anything: Simulation-Ready Physical 3D Assets from Single Image
Nov 17, 20253D modeling is shifting from static visual representations toward physical, articulated assets that can be directly used in simulation and interaction. However, most existing 3D generation methods overlook key physical and articulation properties, thereby limiting their utility in embodied AI. To bridge this gap, we introduce PhysX-Anything, the first simulation-ready physical 3D generative framework that, given a single in-the-wild image, produces high-quality sim-ready 3D assets with explicit geometry, articulation, and physical attributes. Specifically, we propose the first VLM-based physical 3D generative model, along with a new 3D representation that efficiently tokenizes geometry. It reduces the number of tokens by 193x, enabling explicit geometry learning within standard VLM token budgets without introducing any special tokens during fine-tuning and significantly improving generative quality. In addition, to overcome the limited diversity of existing physical 3D datasets, we construct a new dataset, PhysX-Mobility, which expands the object categories in prior physical 3D datasets by over 2x and includes more than 2K common real-world objects with rich physical annotations. Extensive experiments on PhysX-Mobility and in-the-wild images demonstrate that PhysX-Anything delivers strong generative performance and robust generalization. Furthermore, simulation-based experiments in a MuJoCo-style environment validate that our sim-ready assets can be directly used for contact-rich robotic policy learning. We believe PhysX-Anything can substantially empower a broad range of downstream applications, especially in embodied AI and physics-based simulation.
Simulating the Visual World with Artificial Intelligence: A Roadmap
Nov 11, 2025The landscape of video generation is shifting, from a focus on generating visually appealing clips to building virtual environments that support interaction and maintain physical plausibility. These developments point toward the emergence of video foundation models that function not only as visual generators but also as implicit world models, models that simulate the physical dynamics, agent-environment interactions, and task planning that govern real or imagined worlds. This survey provides a systematic overview of this evolution, conceptualizing modern video foundation models as the combination of two core components: an implicit world model and a video renderer. The world model encodes structured knowledge about the world, including physical laws, interaction dynamics, and agent behavior. It serves as a latent simulation engine that enables coherent visual reasoning, long-term temporal consistency, and goal-driven planning. The video renderer transforms this latent simulation into realistic visual observations, effectively producing videos as a "window" into the simulated world. We trace the progression of video generation through four generations, in which the core capabilities advance step by step, ultimately culminating in a world model, built upon a video generation model, that embodies intrinsic physical plausibility, real-time multimodal interaction, and planning capabilities spanning multiple spatiotemporal scales. For each generation, we define its core characteristics, highlight representative works, and examine their application domains such as robotics, autonomous driving, and interactive gaming. Finally, we discuss open challenges and design principles for next-generation world models, including the role of agent intelligence in shaping and evaluating these systems. An up-to-date list of related works is maintained at this link.
One View, Many Worlds: Single-Image to 3D Object Meets Generative Domain Randomization for One-Shot 6D Pose Estimation
Sep 09, 2025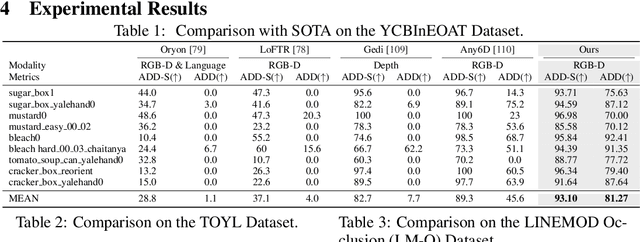
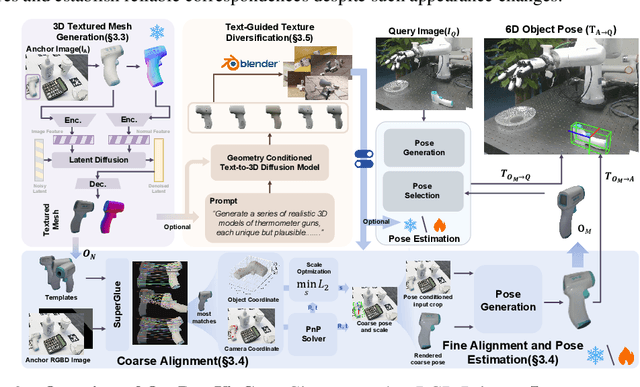
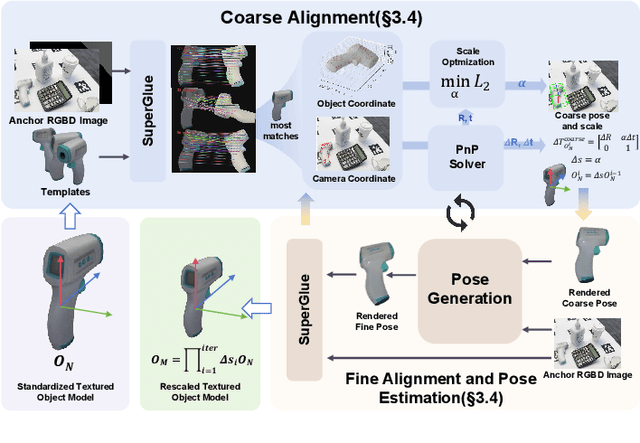
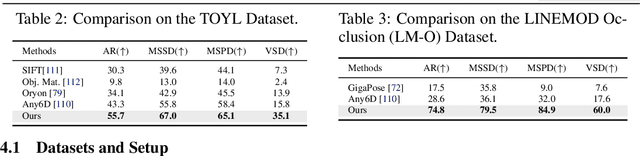
Estimating the 6D pose of arbitrary unseen objects from a single reference image is critical for robotics operating in the long-tail of real-world instances. However, this setting is notoriously challenging: 3D models are rarely available, single-view reconstructions lack metric scale, and domain gaps between generated models and real-world images undermine robustness. We propose OnePoseViaGen, a pipeline that tackles these challenges through two key components. First, a coarse-to-fine alignment module jointly refines scale and pose by combining multi-view feature matching with render-and-compare refinement. Second, a text-guided generative domain randomization strategy diversifies textures, enabling effective fine-tuning of pose estimators with synthetic data. Together, these steps allow high-fidelity single-view 3D generation to support reliable one-shot 6D pose estimation. On challenging benchmarks (YCBInEOAT, Toyota-Light, LM-O), OnePoseViaGen achieves state-of-the-art performance far surpassing prior approaches. We further demonstrate robust dexterous grasping with a real robot hand, validating the practicality of our method in real-world manipulation. Project page: https://gzwsama.github.io/OnePoseviaGen.github.io/