 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVid-CamEdit: Video Camera Trajectory Editing with Generative Rendering from Estimated Geometry
Jun 16, 2025We introduce Vid-CamEdit, a novel framework for video camera trajectory editing, enabling the re-synthesis of monocular videos along user-defined camera paths. This task is challenging due to its ill-posed nature and the limited multi-view video data for training. Traditional reconstruction methods struggle with extreme trajectory changes, and existing generative models for dynamic novel view synthesis cannot handle in-the-wild videos. Our approach consists of two steps: estimating temporally consistent geometry, and generative rendering guided by this geometry. By integrating geometric priors, the generative model focuses on synthesizing realistic details where the estimated geometry is uncertain. We eliminate the need for extensive 4D training data through a factorized fine-tuning framework that separately trains spatial and temporal components using multi-view image and video data. Our method outperforms baselines in producing plausible videos from novel camera trajectories, especially in extreme extrapolation scenarios on real-world footage.
Free4D: Tuning-free 4D Scene Generation with Spatial-Temporal Consistency
Mar 26, 2025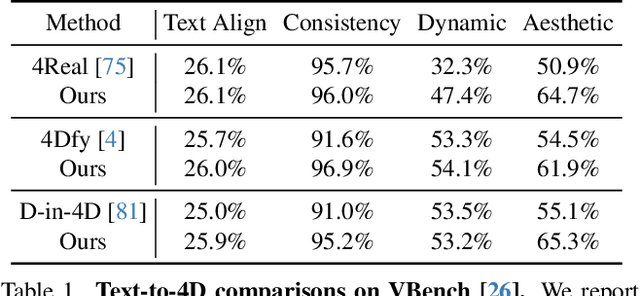
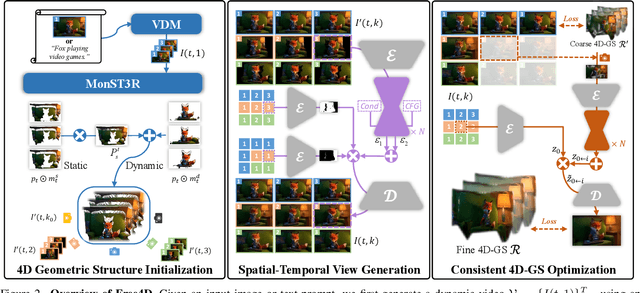
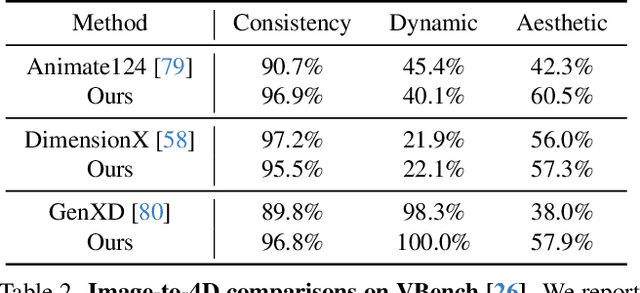

We present Free4D, a novel tuning-free framework for 4D scene generation from a single image. Existing methods either focus on object-level generation, making scene-level generation infeasible, or rely on large-scale multi-view video datasets for expensive training, with limited generalization ability due to the scarcity of 4D scene data. In contrast, our key insight is to distill pre-trained foundation models for consistent 4D scene representation, which offers promising advantages such as efficiency and generalizability. 1) To achieve this, we first animate the input image using image-to-video diffusion models followed by 4D geometric structure initialization. 2) To turn this coarse structure into spatial-temporal consistent multiview videos, we design an adaptive guidance mechanism with a point-guided denoising strategy for spatial consistency and a novel latent replacement strategy for temporal coherence. 3) To lift these generated observations into consistent 4D representation, we propose a modulation-based refinement to mitigate inconsistencies while fully leveraging the generated information. The resulting 4D representation enables real-time, controllable rendering, marking a significant advancement in single-image-based 4D scene generation.
HumanGif: Single-View Human Diffusion with Generative Prior
Feb 17, 2025
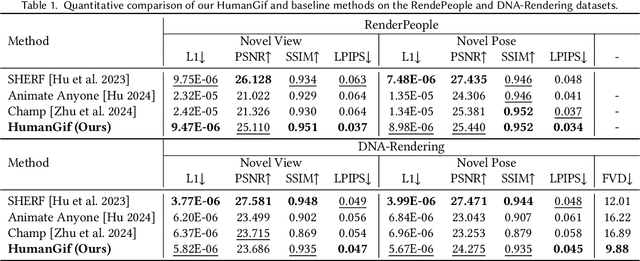
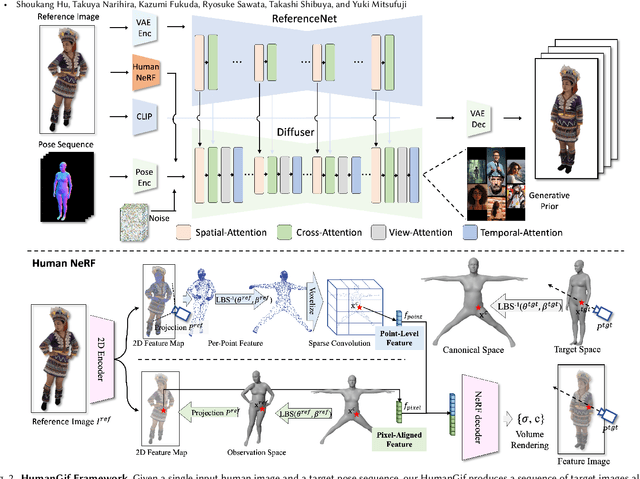

While previous single-view-based 3D human reconstruction methods made significant progress in novel view synthesis, it remains a challenge to synthesize both view-consistent and pose-consistent results for animatable human avatars from a single image input. Motivated by the success of 2D character animation, we propose <strong>HumanGif</strong>, a single-view human diffusion model with generative prior. Specifically, we formulate the single-view-based 3D human novel view and pose synthesis as a single-view-conditioned human diffusion process, utilizing generative priors from foundational diffusion models. To ensure fine-grained and consistent novel view and pose synthesis, we introduce a Human NeRF module in HumanGif to learn spatially aligned features from the input image, implicitly capturing the relative camera and human pose transformation. Furthermore, we introduce an image-level loss during optimization to bridge the gap between latent and image spaces in diffusion models. Extensive experiments on RenderPeople and DNA-Rendering datasets demonstrate that HumanGif achieves the best perceptual performance, with better generalizability for novel view and pose synthesis.
Towards Effective and Efficient Non-autoregressive Decoding Using Block-based Attention Mask
Jun 14, 2024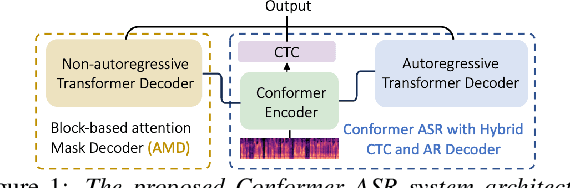
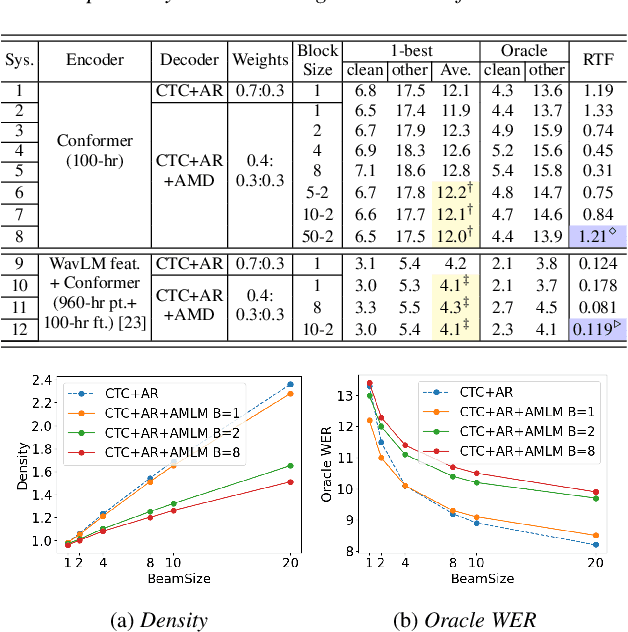
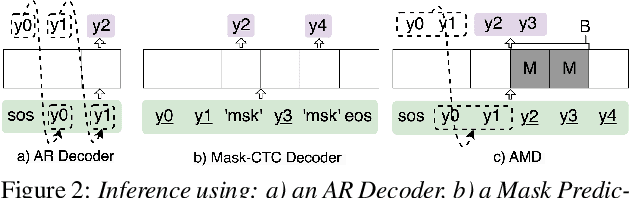
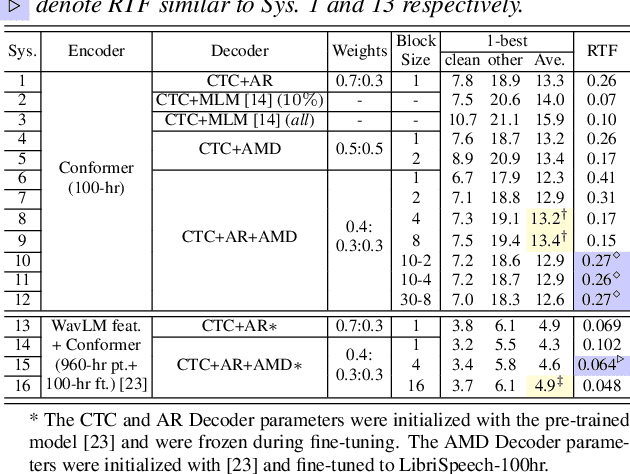
This paper proposes a novel non-autoregressive (NAR) block-based Attention Mask Decoder (AMD) that flexibly balances performance-efficiency trade-offs for Conformer ASR systems. AMD performs parallel NAR inference within contiguous blocks of output labels that are concealed using attention masks, while conducting left-to-right AR prediction and history context amalgamation between blocks. A beam search algorithm is designed to leverage a dynamic fusion of CTC, AR Decoder, and AMD probabilities. Experiments on the LibriSpeech-100hr corpus suggest the tripartite Decoder incorporating the AMD module produces a maximum decoding speed-up ratio of 1.73x over the baseline CTC+AR decoding, while incurring no statistically significant word error rate (WER) increase on the test sets. When operating with the same decoding real time factors, statistically significant WER reductions of up to 0.7% and 0.3% absolute (5.3% and 6.1% relative) were obtained over the CTC+AR baseline.
One-pass Multiple Conformer and Foundation Speech Systems Compression and Quantization Using An All-in-one Neural Model
Jun 14, 2024



We propose a novel one-pass multiple ASR systems joint compression and quantization approach using an all-in-one neural model. A single compression cycle allows multiple nested systems with varying Encoder depths, widths, and quantization precision settings to be simultaneously constructed without the need to train and store individual target systems separately. Experiments consistently demonstrate the multiple ASR systems compressed in a single all-in-one model produced a word error rate (WER) comparable to, or lower by up to 1.01\% absolute (6.98\% relative) than individually trained systems of equal complexity. A 3.4x overall system compression and training time speed-up was achieved. Maximum model size compression ratios of 12.8x and 3.93x were obtained over the baseline Switchboard-300hr Conformer and LibriSpeech-100hr fine-tuned wav2vec2.0 models, respectively, incurring no statistically significant WER increase.
GenWarp: Single Image to Novel Views with Semantic-Preserving Generative Warping
May 27, 2024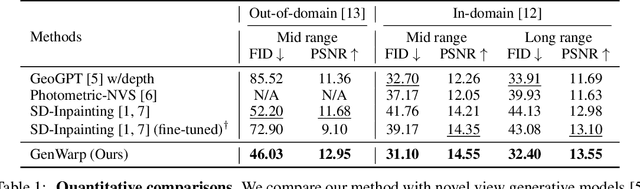
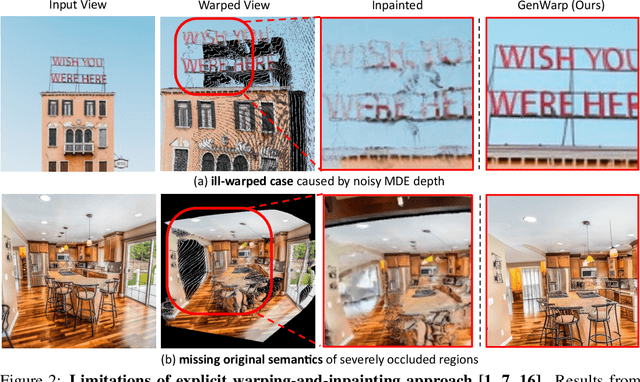

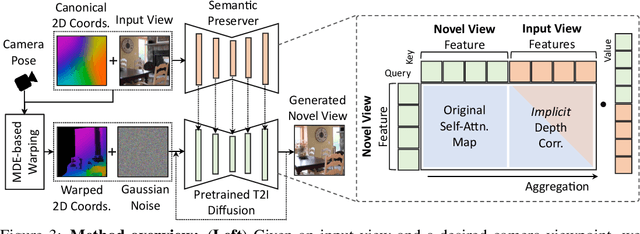
Generating novel views from a single image remains a challenging task due to the complexity of 3D scenes and the limited diversity in the existing multi-view datasets to train a model on. Recent research combining large-scale text-to-image (T2I) models with monocular depth estimation (MDE) has shown promise in handling in-the-wild images. In these methods, an input view is geometrically warped to novel views with estimated depth maps, then the warped image is inpainted by T2I models. However, they struggle with noisy depth maps and loss of semantic details when warping an input view to novel viewpoints. In this paper, we propose a novel approach for single-shot novel view synthesis, a semantic-preserving generative warping framework that enables T2I generative models to learn where to warp and where to generate, through augmenting cross-view attention with self-attention. Our approach addresses the limitations of existing methods by conditioning the generative model on source view images and incorporating geometric warping signals. Qualitative and quantitative evaluations demonstrate that our model outperforms existing methods in both in-domain and out-of-domain scenarios. Project page is available at https://GenWarp-NVS.github.io/.
Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo
May 20, 2024



We present MVSGaussian, a new generalizable 3D Gaussian representation approach derived from Multi-View Stereo (MVS) that can efficiently reconstruct unseen scenes. Specifically, 1) we leverage MVS to encode geometry-aware Gaussian representations and decode them into Gaussian parameters. 2) To further enhance performance, we propose a hybrid Gaussian rendering that integrates an efficient volume rendering design for novel view synthesis. 3) To support fast fine-tuning for specific scenes, we introduce a multi-view geometric consistent aggregation strategy to effectively aggregate the point clouds generated by the generalizable model, serving as the initialization for per-scene optimization. Compared with previous generalizable NeRF-based methods, which typically require minutes of fine-tuning and seconds of rendering per image, MVSGaussian achieves real-time rendering with better synthesis quality for each scene. Compared with the vanilla 3D-GS, MVSGaussian achieves better view synthesis with less training computational cost. Extensive experiments on DTU, Real Forward-facing, NeRF Synthetic, and Tanks and Temples datasets validate that MVSGaussian attains state-of-the-art performance with convincing generalizability, real-time rendering speed, and fast per-scene optimization.
GSTalker: Real-time Audio-Driven Talking Face Generation via Deformable Gaussian Splatting
Apr 29, 2024We present GStalker, a 3D audio-driven talking face generation model with Gaussian Splatting for both fast training (40 minutes) and real-time rendering (125 FPS) with a 3$\sim$5 minute video for training material, in comparison with previous 2D and 3D NeRF-based modeling frameworks which require hours of training and seconds of rendering per frame. Specifically, GSTalker learns an audio-driven Gaussian deformation field to translate and transform 3D Gaussians to synchronize with audio information, in which multi-resolution hashing grid-based tri-plane and temporal smooth module are incorporated to learn accurate deformation for fine-grained facial details. In addition, a pose-conditioned deformation field is designed to model the stabilized torso. To enable efficient optimization of the condition Gaussian deformation field, we initialize 3D Gaussians by learning a coarse static Gaussian representation. Extensive experiments in person-specific videos with audio tracks validate that GSTalker can generate high-fidelity and audio-lips synchronized results with fast training and real-time rendering speed.
GauHuman: Articulated Gaussian Splatting from Monocular Human Videos
Dec 05, 2023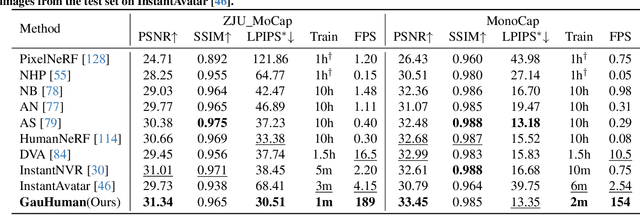
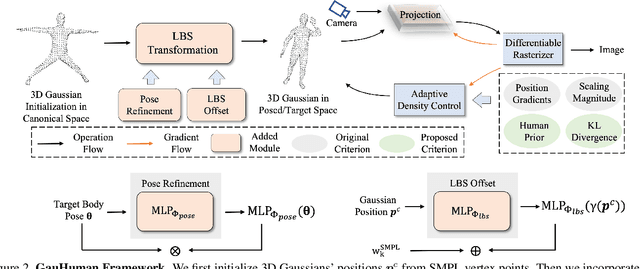

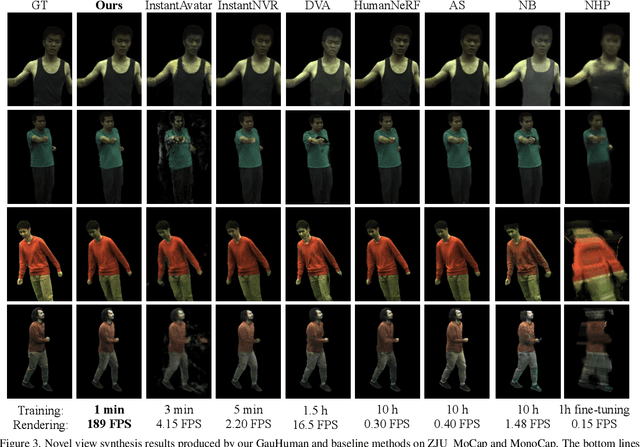
We present, GauHuman, a 3D human model with Gaussian Splatting for both fast training (1 ~ 2 minutes) and real-time rendering (up to 189 FPS), compared with existing NeRF-based implicit representation modelling frameworks demanding hours of training and seconds of rendering per frame. Specifically, GauHuman encodes Gaussian Splatting in the canonical space and transforms 3D Gaussians from canonical space to posed space with linear blend skinning (LBS), in which effective pose and LBS refinement modules are designed to learn fine details of 3D humans under negligible computational cost. Moreover, to enable fast optimization of GauHuman, we initialize and prune 3D Gaussians with 3D human prior, while splitting/cloning via KL divergence guidance, along with a novel merge operation for further speeding up. Extensive experiments on ZJU_Mocap and MonoCap datasets demonstrate that GauHuman achieves state-of-the-art performance quantitatively and qualitatively with fast training and real-time rendering speed. Notably, without sacrificing rendering quality, GauHuman can fast model the 3D human performer with ~13k 3D Gaussians.
HumanLiff: Layer-wise 3D Human Generation with Diffusion Model
Aug 18, 2023



3D human generation from 2D images has achieved remarkable progress through the synergistic utilization of neural rendering and generative models. Existing 3D human generative models mainly generate a clothed 3D human as an undetectable 3D model in a single pass, while rarely considering the layer-wise nature of a clothed human body, which often consists of the human body and various clothes such as underwear, outerwear, trousers, shoes, etc. In this work, we propose HumanLiff, the first layer-wise 3D human generative model with a unified diffusion process. Specifically, HumanLiff firstly generates minimal-clothed humans, represented by tri-plane features, in a canonical space, and then progressively generates clothes in a layer-wise manner. In this way, the 3D human generation is thus formulated as a sequence of diffusion-based 3D conditional generation. To reconstruct more fine-grained 3D humans with tri-plane representation, we propose a tri-plane shift operation that splits each tri-plane into three sub-planes and shifts these sub-planes to enable feature grid subdivision. To further enhance the controllability of 3D generation with 3D layered conditions, HumanLiff hierarchically fuses tri-plane features and 3D layered conditions to facilitate the 3D diffusion model learning. Extensive experiments on two layer-wise 3D human datasets, SynBody (synthetic) and TightCap (real-world), validate that HumanLiff significantly outperforms state-of-the-art methods in layer-wise 3D human generation. Our code will be available at https://skhu101.github.io/HumanLiff.