 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Data-free and Training-free Compression for Speech Foundation Models Using Parameter Clustering
Jun 11, 2026This paper presents a novel data-free and training-free compression approach for speech foundation models using channelwise clustering via k-means. More fine-grained, mixed sparsity pruning by layer-level varying number of parameter clusters is also explored. Experiments conducted on the LibriSpeech dataset suggest that when operating with pruning sparsity of 50% on HuBERT-large, consistent WER reductions of 27.73%/18.61% absolute (34.37%/21.91% relative) over the magnitude-based pruning were obtained on the test-clean and test-other subsets before fine-tuning and 0.19%/0.79% absolute (3.36%/4.62% relative) after fine-tuning with only 3 epochs. Similar WER reductions of 2.86%/5.02% absolute (59.21%/55.29% relative) were observed against magnitudebased pruning on Whisper-large-v3 at 10% sparsity, all with no significant WER increase relative to the uncompressed baseline.
UNISON: A Unified Sound Generation and Editing Framework via Deep LLM Fusion
May 29, 2026We present UNISON, a latent diffusion framework that unifies speech generation, sound generation, and audio editing within a single model. A single model handles text-to-audio, text-to-speech, zero-shot speaker cloning, mixed speech-and-sound generation, scene-level audio editing, speech-in-scene editing, and timed temporal composition, all of which share a single set of weights. Our architecture features two core designs: (1) Layer-wise deep LLM fusion, which injects hidden states from uniformly sampled layers of a frozen MLLM into corresponding MM-DiT blocks via learned projections, providing depth-matched semantic conditioning that improves instruction following over single-layer baselines; and (2) a unified multi-task architecture where task identity is encoded solely by a channel-wise mask and source audio is provided through VAE-encoded channel concatenation. Training is stabilized by an online GPU-side multi-task data synthesis pipeline with task-homogeneous batching and a two-stage curriculum. With 621M--732M trainable parameters, UNISON achieves results competitive with or exceeding task-specialist models across evaluated domains, while being roughly $4\times$ smaller than comparable unified systems.
MTR-DuplexBench: Towards a Comprehensive Evaluation of Multi-Round Conversations for Full-Duplex Speech Language Models
Nov 13, 2025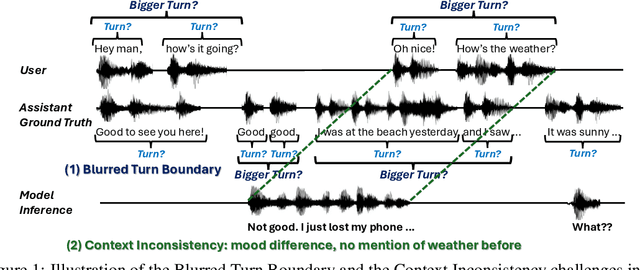

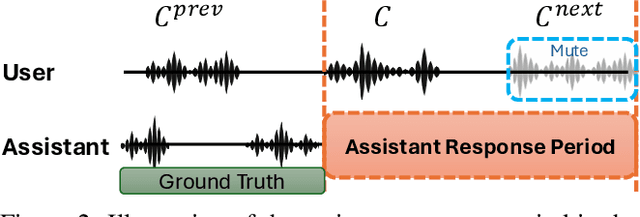

Full-Duplex Speech Language Models (FD-SLMs) enable real-time, overlapping conversational interactions, offering a more dynamic user experience compared to traditional half-duplex models. However, existing benchmarks primarily focus on evaluating single-round interactions and conversational features, neglecting the complexities of multi-round communication and critical capabilities such as instruction following and safety. Evaluating FD-SLMs in multi-round settings poses significant challenges, including blurred turn boundaries in communication and context inconsistency during model inference. To address these gaps, we introduce MTR-DuplexBench, a novel benchmark that segments continuous full-duplex dialogues into discrete turns, enabling comprehensive, turn-by-turn evaluation of FD-SLMs across dialogue quality, conversational dynamics, instruction following, and safety. Experimental results reveal that current FD-SLMs face difficulties in maintaining consistent performance across multiple rounds and evaluation dimensions, highlighting the necessity and effectiveness of our proposed benchmark. The benchmark and code will be available in the future.
MOPSA: Mixture of Prompt-Experts Based Speaker Adaptation for Elderly Speech Recognition
May 30, 2025



This paper proposes a novel Mixture of Prompt-Experts based Speaker Adaptation approach (MOPSA) for elderly speech recognition. It allows zero-shot, real-time adaptation to unseen speakers, and leverages domain knowledge tailored to elderly speakers. Top-K most distinctive speaker prompt clusters derived using K-means serve as experts. A router network is trained to dynamically combine clustered prompt-experts. Acoustic and language level variability among elderly speakers are modelled using separate encoder and decoder prompts for Whisper. Experiments on the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech datasets suggest that online MOPSA adaptation outperforms the speaker-independent (SI) model by statistically significant word error rate (WER) or character error rate (CER) reductions of 0.86% and 1.47% absolute (4.21% and 5.40% relative). Real-time factor (RTF) speed-up ratios of up to 16.12 times are obtained over offline batch-mode adaptation.
Towards LLM-Empowered Fine-Grained Speech Descriptors for Explainable Emotion Recognition
May 29, 2025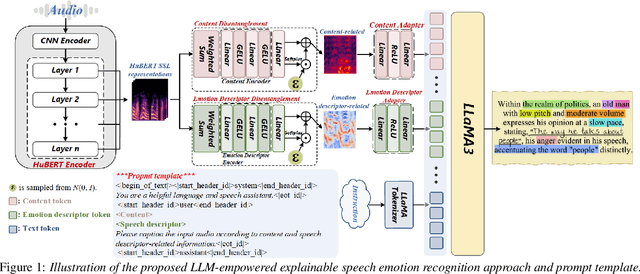
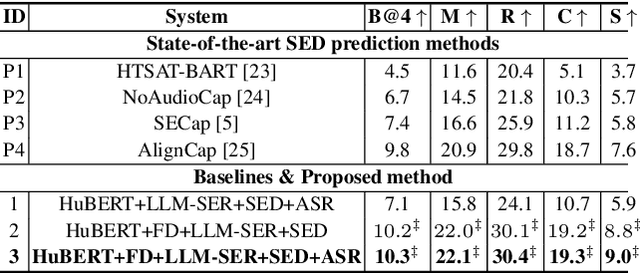
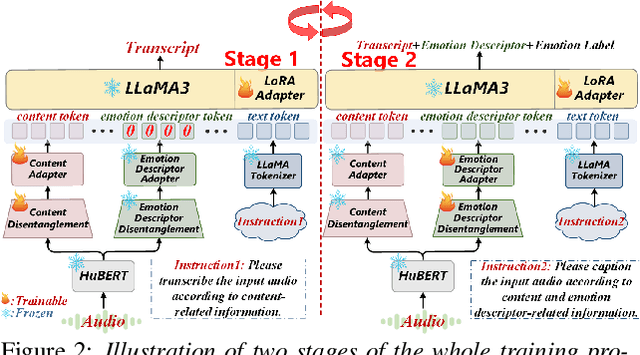
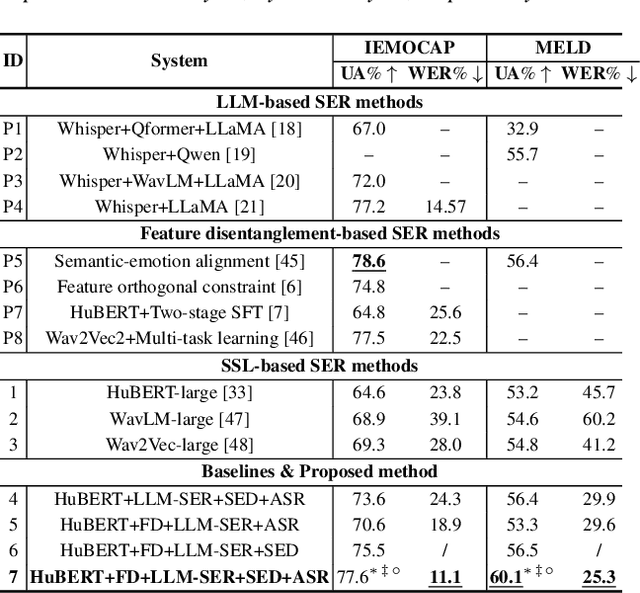
This paper presents a novel end-to-end LLM-empowered explainable speech emotion recognition (SER) approach. Fine-grained speech emotion descriptor (SED) features, e.g., pitch, tone and emphasis, are disentangled from HuBERT SSL representations via alternating LLM fine-tuning to joint SER-SED prediction and ASR tasks. VAE compressed HuBERT features derived via Information Bottleneck (IB) are used to adjust feature granularity. Experiments on the IEMOCAP and MELD benchmarks demonstrate that our approach consistently outperforms comparable LLaMA-based SER baselines, including those using either (a) alternating multi-task fine-tuning alone or (b) feature disentanglement only. Statistically significant increase of SER unweighted accuracy by up to 4.0% and 3.7% absolute (5.4% and 6.6% relative) are obtained. More importantly, emotion descriptors offer further explainability for SER.
Effective and Efficient One-pass Compression of Speech Foundation Models Using Sparsity-aware Self-pinching Gates
May 28, 2025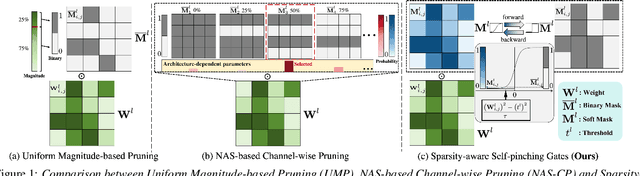
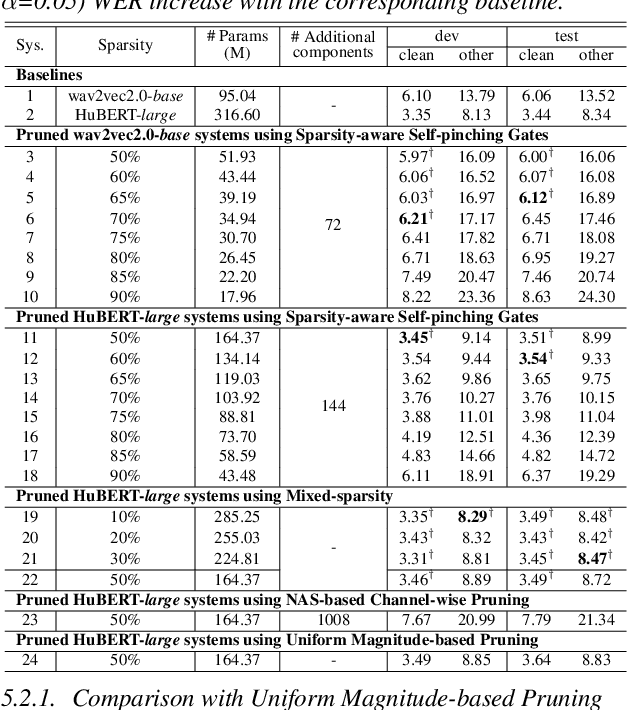
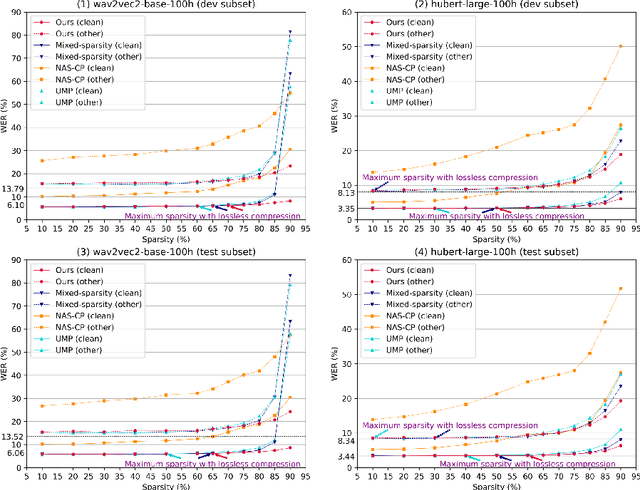
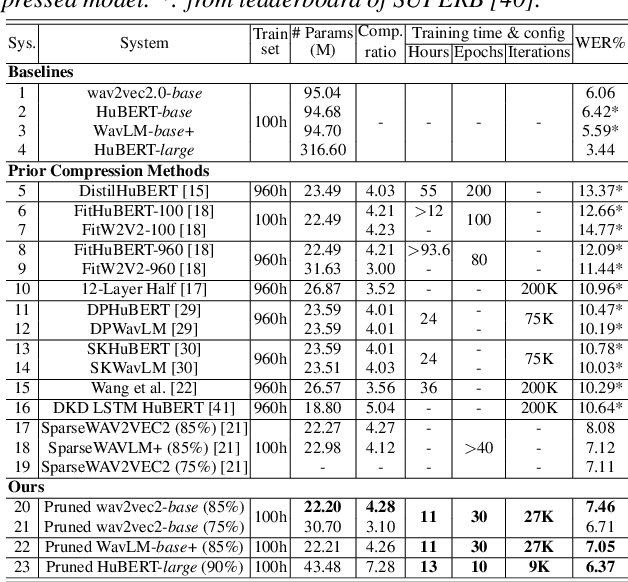
This paper presents a novel approach for speech foundation models compression that tightly integrates model pruning and parameter update into a single stage. Highly compact layer-level tied self-pinching gates each containing only a single learnable threshold are jointly trained with uncompressed models and used in fine-grained neuron level pruning. Experiments conducted on the LibriSpeech-100hr corpus suggest that our approach reduces the number of parameters of wav2vec2.0-base and HuBERT-large models by 65% and 60% respectively, while incurring no statistically significant word error rate (WER) increase on the test-clean dataset. Compared to previously published methods on the same task, our approach not only achieves the lowest WER of 7.05% on the test-clean dataset under a comparable model compression ratio of 4.26x, but also operates with at least 25% less model compression time.
Towards One-bit ASR: Extremely Low-bit Conformer Quantization Using Co-training and Stochastic Precision
May 27, 2025Model compression has become an emerging need as the sizes of modern speech systems rapidly increase. In this paper, we study model weight quantization, which directly reduces the memory footprint to accommodate computationally resource-constrained applications. We propose novel approaches to perform extremely low-bit (i.e., 2-bit and 1-bit) quantization of Conformer automatic speech recognition systems using multiple precision model co-training, stochastic precision, and tensor-wise learnable scaling factors to alleviate quantization incurred performance loss. The proposed methods can achieve performance-lossless 2-bit and 1-bit quantization of Conformer ASR systems trained with the 300-hr Switchboard and 960-hr LibriSpeech corpus. Maximum overall performance-lossless compression ratios of 16.2 and 16.6 times are achieved without a statistically significant increase in the word error rate (WER) over the full precision baseline systems, respectively.
Unfolding A Few Structures for The Many: Memory-Efficient Compression of Conformer and Speech Foundation Models
May 27, 2025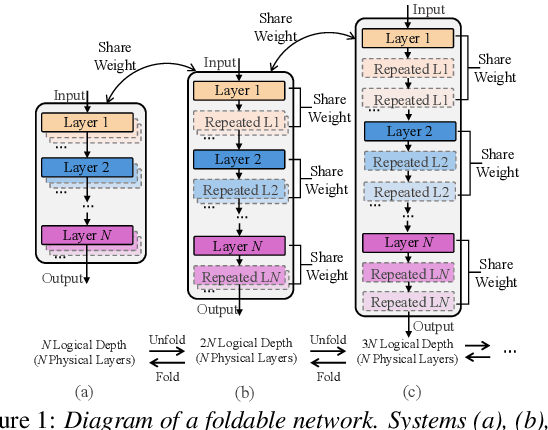
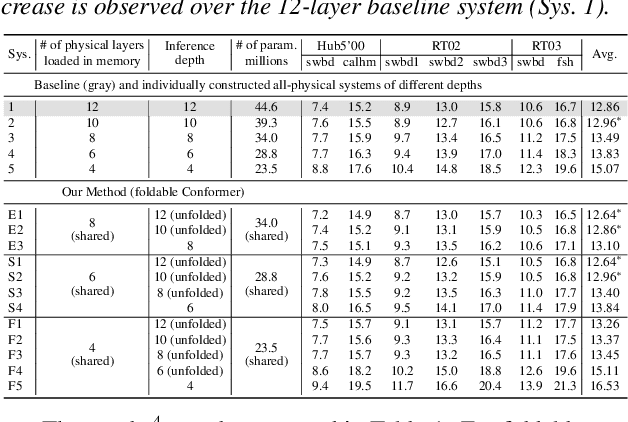
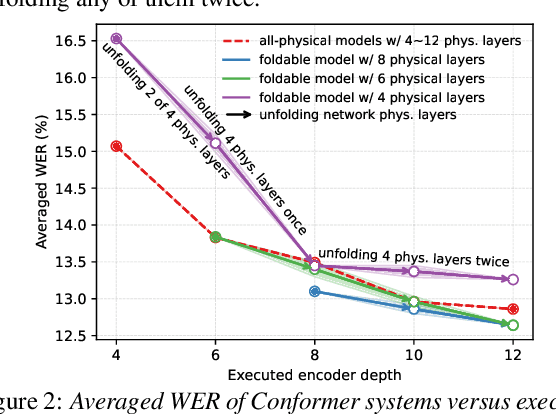
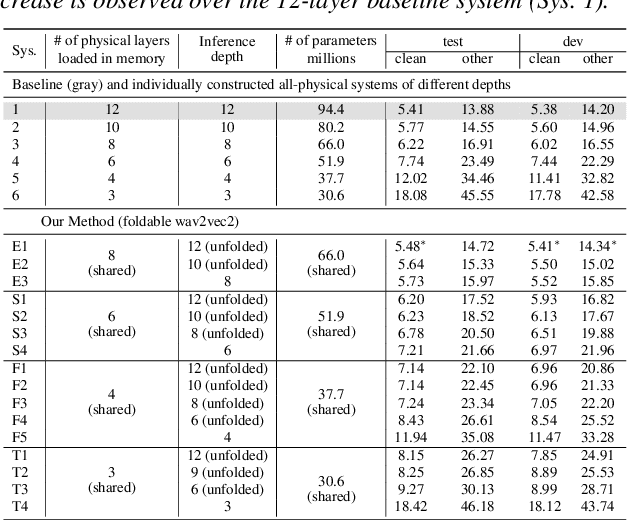
This paper presents a novel memory-efficient model compression approach for Conformer ASR and speech foundation systems. Our approach features a unique "small-to-large" design. A compact "seed" model containing a few Conformer or Transformer blocks is trained and unfolded many times to emulate the performance of larger uncompressed models with different logical depths. The seed model and many unfolded paths are jointly trained within a single unfolding cycle. The KL-divergence between the largest unfolded and smallest seed models is used in a self-distillation process to minimize their performance disparity. Experimental results show that our foldable model produces ASR performance comparable to individually constructed Conformer and wav2vec2/HuBERT speech foundation models under various depth configurations, while requiring only minimal memory and storage. Conformer and wav2vec2 models with a reduction of 35% and 30% parameters are obtained without loss of performance, respectively.
Phone-purity Guided Discrete Tokens for Dysarthric Speech Recognition
Jan 08, 2025



Discrete tokens extracted provide efficient and domain adaptable speech features. Their application to disordered speech that exhibits articulation imprecision and large mismatch against normal voice remains unexplored. To improve their phonetic discrimination that is weakened during unsupervised K-means or vector quantization of continuous features, this paper proposes novel phone-purity guided (PPG) discrete tokens for dysarthric speech recognition. Phonetic label supervision is used to regularize maximum likelihood and reconstruction error costs used in standard K-means and VAE-VQ based discrete token extraction. Experiments conducted on the UASpeech corpus suggest that the proposed PPG discrete token features extracted from HuBERT consistently outperform hybrid TDNN and End-to-End (E2E) Conformer systems using non-PPG based K-means or VAE-VQ tokens across varying codebook sizes by statistically significant word error rate (WER) reductions up to 0.99\% and 1.77\% absolute (3.21\% and 4.82\% relative) respectively on the UASpeech test set of 16 dysarthric speakers. The lowest WER of 23.25\% was obtained by combining systems using different token features. Consistent improvements on the phone purity metric were also achieved. T-SNE visualization further demonstrates sharper decision boundaries were produced between K-means/VAE-VQ clusters after introducing phone-purity guidance.
Effective and Efficient Mixed Precision Quantization of Speech Foundation Models
Jan 07, 2025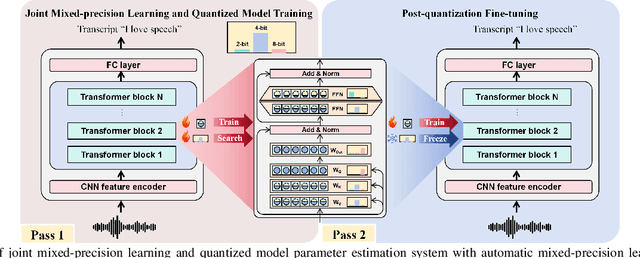
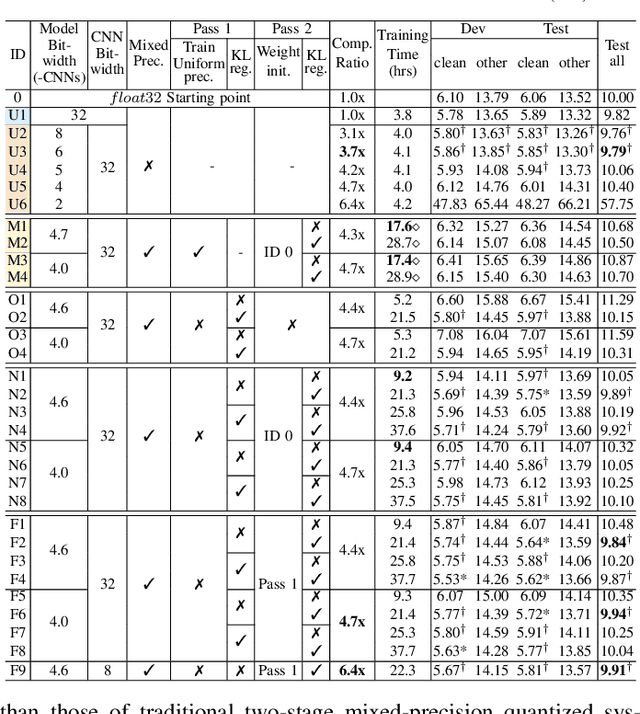
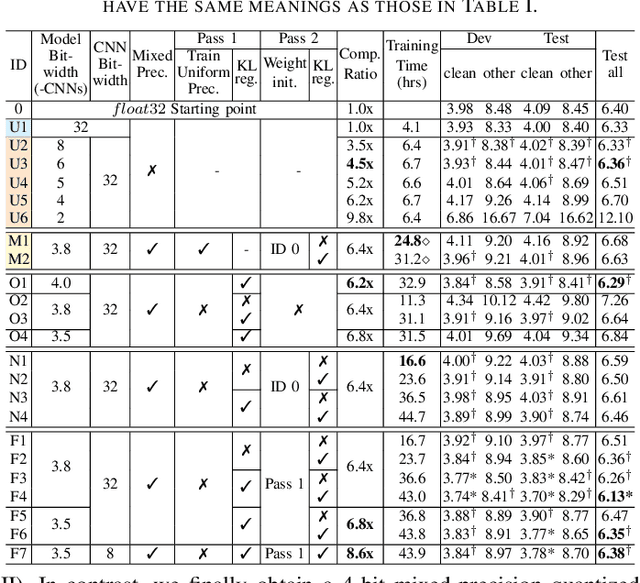
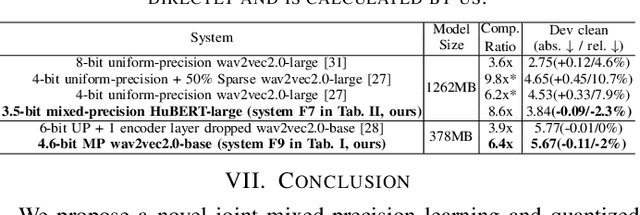
This paper presents a novel mixed-precision quantization approach for speech foundation models that tightly integrates mixed-precision learning and quantized model parameter estimation into one single model compression stage. Experiments conducted on LibriSpeech dataset with fine-tuned wav2vec2.0-base and HuBERT-large models suggest the resulting mixed-precision quantized models increased the lossless compression ratio by factors up to 1.7x and 1.9x over the respective uniform-precision and two-stage mixed-precision quantized baselines that perform precision learning and model parameters quantization in separate and disjointed stages, while incurring no statistically word error rate (WER) increase over the 32-bit full-precision models. The system compression time of wav2vec2.0-base and HuBERT-large models is reduced by up to 1.9 and 1.5 times over the two-stage mixed-precision baselines, while both produce lower WERs. The best-performing 3.5-bit mixed-precision quantized HuBERT-large model produces a lossless compression ratio of 8.6x over the 32-bit full-precision system.