 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSICL-AT: Another way to adapt Auditory LLM to low-resource task
Jan 26, 2026Auditory Large Language Models (LLMs) have demonstrated strong performance across a wide range of speech and audio understanding tasks. Nevertheless, they often struggle when applied to low-resource or unfamiliar tasks. In case of labeled in-domain data is scarce or mismatched to the true test distribution, direct fine-tuning can be brittle. In-Context Learning (ICL) provides a training-free, inference-time solution by adapting auditory LLMs through conditioning on a few in-domain demonstrations. In this work, we first show that \emph{Vanilla ICL}, improves zero-shot performance across diverse speech and audio tasks for selected models which suggest this ICL adaptation capability can be generalized to multimodal setting. Building on this, we propose \textbf{Speech In-Context Learning Adaptation Training (SICL-AT)}, a post-training recipe utilizes only high resource speech data intending to strengthen model's in-context learning capability. The enhancement can generalize to audio understanding/reasoning task. Experiments indicate our proposed method consistently outperforms direct fine-tuning in low-resource scenario.
Discovery and Reinforcement of Tool-Integrated Reasoning Chains via Rollout Trees
Jan 13, 2026Tool-Integrated Reasoning has emerged as a key paradigm to augment Large Language Models (LLMs) with computational capabilities, yet integrating tool-use into long Chain-of-Thought (long CoT) remains underexplored, largely due to the scarcity of training data and the challenge of integrating tool-use without compromising the model's intrinsic long-chain reasoning. In this paper, we introduce DART (Discovery And Reinforcement of Tool-Integrated Reasoning Chains via Rollout Trees), a reinforcement learning framework that enables spontaneous tool-use during long CoT reasoning without human annotation. DART operates by constructing dynamic rollout trees during training to discover valid tool-use opportunities, branching out at promising positions to explore diverse tool-integrated trajectories. Subsequently, a tree-based process advantage estimation identifies and credits specific sub-trajectories where tool invocation positively contributes to the solution, effectively reinforcing these beneficial behaviors. Extensive experiments on challenging benchmarks like AIME and GPQA-Diamond demonstrate that DART significantly outperforms existing methods, successfully harmonizing tool execution with long CoT reasoning.
Towards Fine-Grained and Multi-Granular Contrastive Language-Speech Pre-training
Jan 06, 2026Modeling fine-grained speaking styles remains challenging for language-speech representation pre-training, as existing speech-text models are typically trained with coarse captions or task-specific supervision, and scalable fine-grained style annotations are unavailable. We present FCaps, a large-scale dataset with fine-grained free-text style descriptions, encompassing 47k hours of speech and 19M fine-grained captions annotated via a novel end-to-end pipeline that directly grounds detailed captions in audio, thereby avoiding the error propagation caused by LLM-based rewriting in existing cascaded pipelines. Evaluations using LLM-as-a-judge demonstrate that our annotations surpass existing cascaded annotations in terms of correctness, coverage, and naturalness. Building on FCaps, we propose CLSP, a contrastive language-speech pre-trained model that integrates global and fine-grained supervision, enabling unified representations across multiple granularities. Extensive experiments demonstrate that CLSP learns fine-grained and multi-granular speech-text representations that perform reliably across global and fine-grained speech-text retrieval, zero-shot paralinguistic classification, and speech style similarity scoring, with strong alignment to human judgments. All resources will be made publicly available.
Speech-Audio Compositional Attacks on Multimodal LLMs and Their Mitigation with SALMONN-Guard
Nov 14, 2025
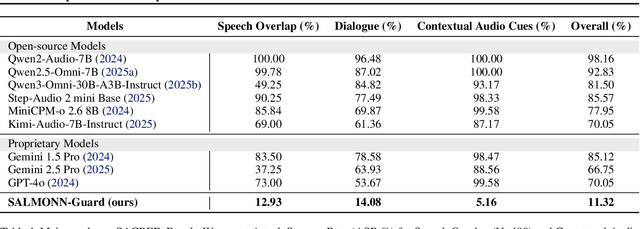
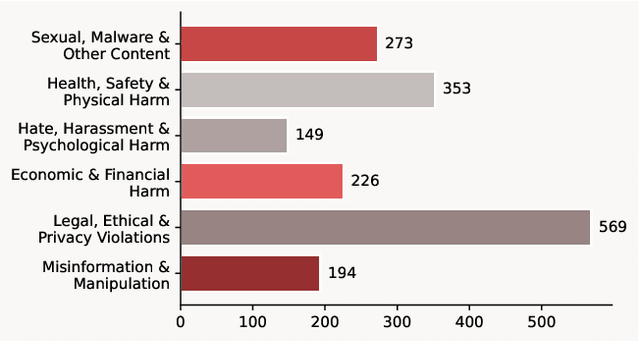
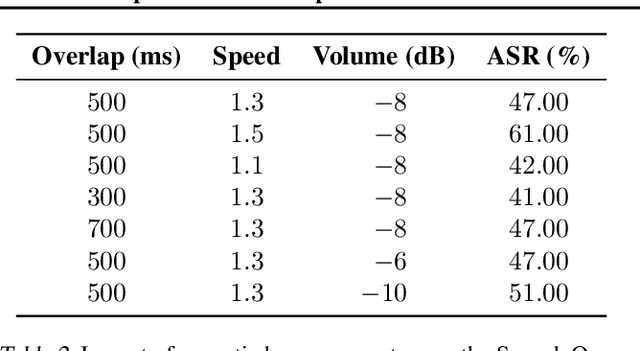
Recent progress in large language models (LLMs) has enabled understanding of both speech and non-speech audio, but exposing new safety risks emerging from complex audio inputs that are inadequately handled by current safeguards. We introduce SACRED-Bench (Speech-Audio Composition for RED-teaming) to evaluate the robustness of LLMs under complex audio-based attacks. Unlike existing perturbation-based methods that rely on noise optimization or white-box access, SACRED-Bench exploits speech-audio composition mechanisms. SACRED-Bench adopts three mechanisms: (a) speech overlap and multi-speaker dialogue, which embeds harmful prompts beneath or alongside benign speech; (b) speech-audio mixture, which imply unsafe intent via non-speech audio alongside benign speech or audio; and (c) diverse spoken instruction formats (open-ended QA, yes/no) that evade text-only filters. Experiments show that, even Gemini 2.5 Pro, the state-of-the-art proprietary LLM, still exhibits 66% attack success rate in SACRED-Bench test set, exposing vulnerabilities under cross-modal, speech-audio composition attacks. To bridge this gap, we propose SALMONN-Guard, a safeguard LLM that jointly inspects speech, audio, and text for safety judgments, reducing attack success down to 20%. Our results highlight the need for audio-aware defenses for the safety of multimodal LLMs. The benchmark and SALMONN-Guard checkpoints can be found at https://huggingface.co/datasets/tsinghua-ee/SACRED-Bench. Warning: this paper includes examples that may be offensive or harmful.
SPEAR: A Unified SSL Framework for Learning Speech and Audio Representations
Oct 29, 2025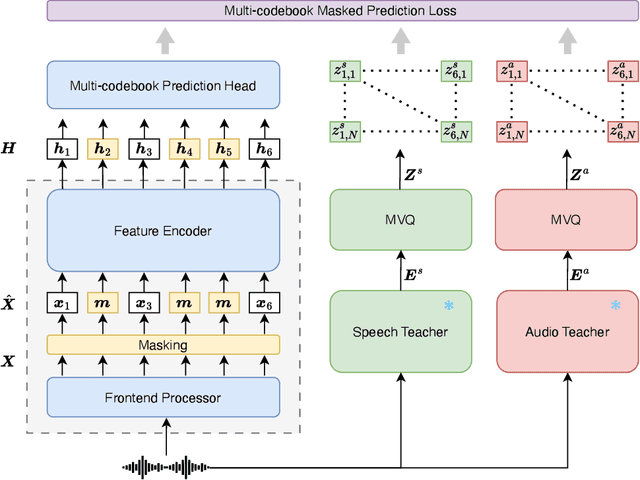

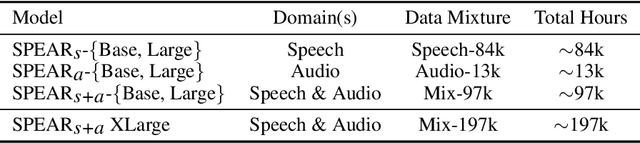
Self-Supervised Learning (SSL) excels at learning generic representations of acoustic signals, yet prevailing methods remain domain-specific, tailored to either speech or general audio, hindering the development of a unified representation model with a comprehensive capability over both domains. To address this, we present SPEAR (SPEech and Audio Representations), the first SSL framework to successfully learn unified speech and audio representations from a mixture of speech and audio data. SPEAR proposes a unified pre-training objective based on masked prediction of fine-grained discrete tokens for both speech and general audio. These tokens are derived from continuous speech and audio representations using a Multi-codebook Vector Quantisation (MVQ) method, retaining rich acoustic detail essential for modelling both speech and complex audio events. SPEAR is applied to pre-train both single-domain and unified speech-and-audio SSL models. Our speech-domain model establishes a new state-of-the-art on the SUPERB benchmark, a speech processing benchmark for SSL models, matching or surpassing the highly competitive WavLM Large on 12 out of 15 tasks with the same pre-training corpora and a similar model size. Crucially, our unified model learns complementary features and demonstrates comprehensive capabilities across two major benchmarks, SUPERB and HEAR, for evaluating audio representations. By further scaling up the model size and pre-training data, we present a unified model with 600M parameters that excels in both domains, establishing it as one of the most powerful and versatile open-source SSL models for auditory understanding. The inference code and pre-trained models will be made publicly available.
Towards One-bit ASR: Extremely Low-bit Conformer Quantization Using Co-training and Stochastic Precision
May 27, 2025Model compression has become an emerging need as the sizes of modern speech systems rapidly increase. In this paper, we study model weight quantization, which directly reduces the memory footprint to accommodate computationally resource-constrained applications. We propose novel approaches to perform extremely low-bit (i.e., 2-bit and 1-bit) quantization of Conformer automatic speech recognition systems using multiple precision model co-training, stochastic precision, and tensor-wise learnable scaling factors to alleviate quantization incurred performance loss. The proposed methods can achieve performance-lossless 2-bit and 1-bit quantization of Conformer ASR systems trained with the 300-hr Switchboard and 960-hr LibriSpeech corpus. Maximum overall performance-lossless compression ratios of 16.2 and 16.6 times are achieved without a statistically significant increase in the word error rate (WER) over the full precision baseline systems, respectively.
Unfolding A Few Structures for The Many: Memory-Efficient Compression of Conformer and Speech Foundation Models
May 27, 2025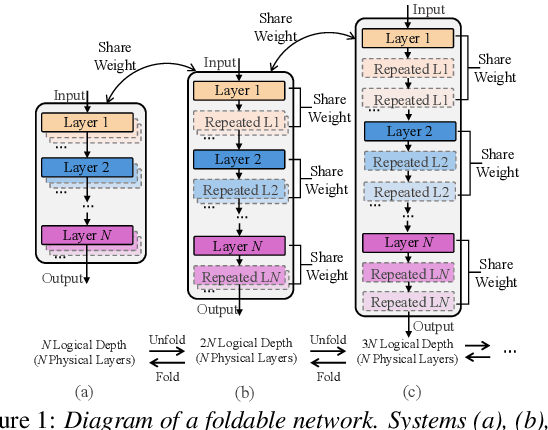
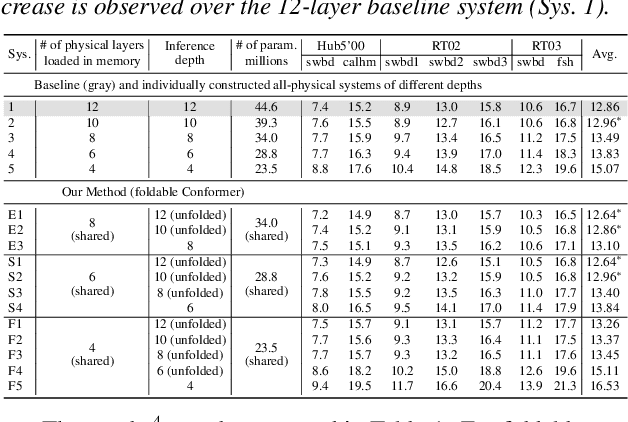
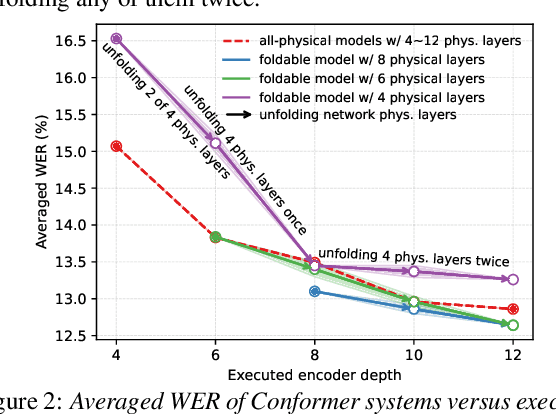
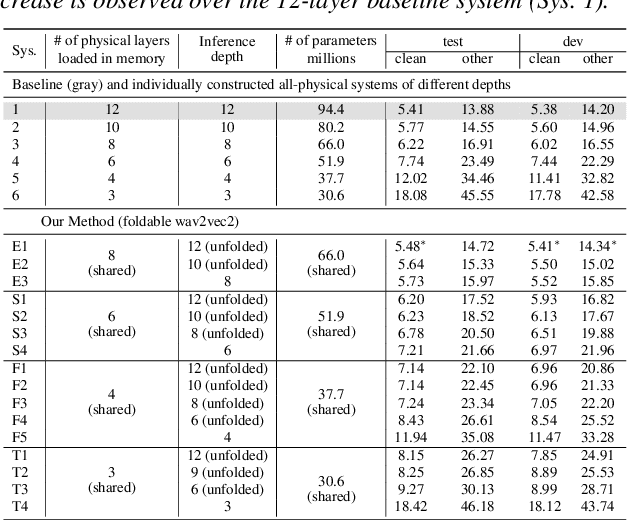
This paper presents a novel memory-efficient model compression approach for Conformer ASR and speech foundation systems. Our approach features a unique "small-to-large" design. A compact "seed" model containing a few Conformer or Transformer blocks is trained and unfolded many times to emulate the performance of larger uncompressed models with different logical depths. The seed model and many unfolded paths are jointly trained within a single unfolding cycle. The KL-divergence between the largest unfolded and smallest seed models is used in a self-distillation process to minimize their performance disparity. Experimental results show that our foldable model produces ASR performance comparable to individually constructed Conformer and wav2vec2/HuBERT speech foundation models under various depth configurations, while requiring only minimal memory and storage. Conformer and wav2vec2 models with a reduction of 35% and 30% parameters are obtained without loss of performance, respectively.
Effective and Efficient Mixed Precision Quantization of Speech Foundation Models
Jan 07, 2025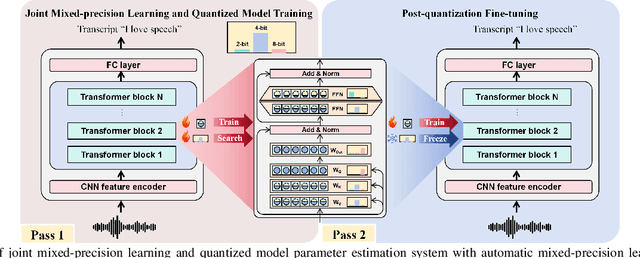
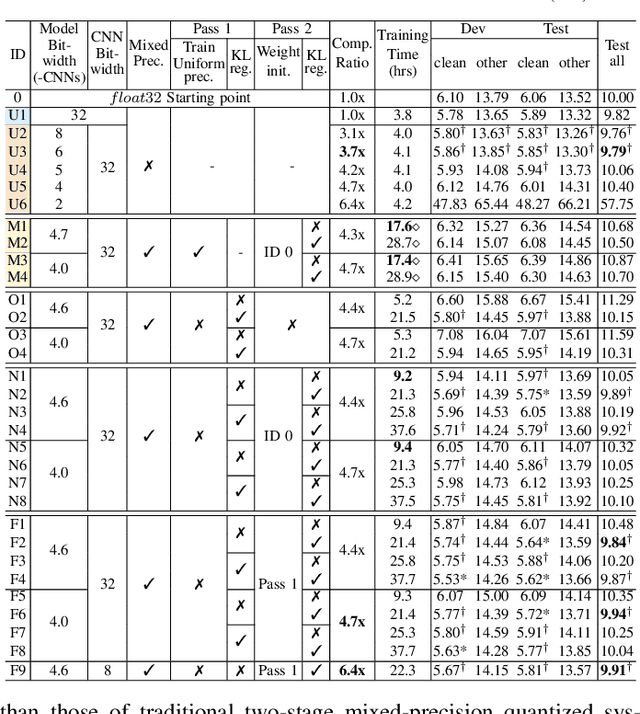
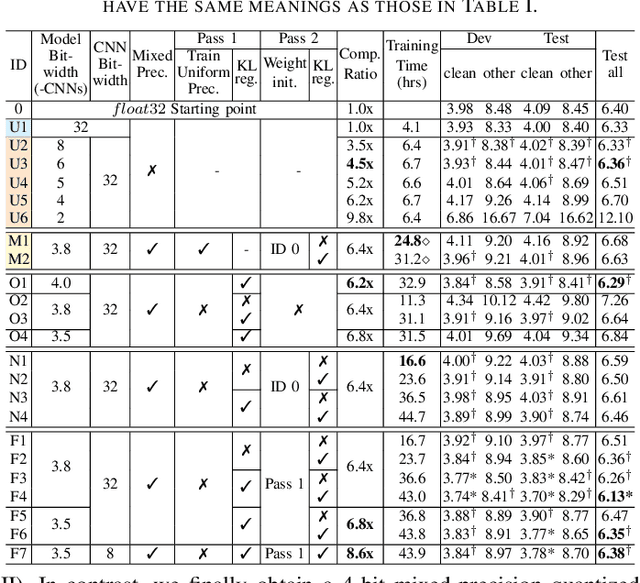
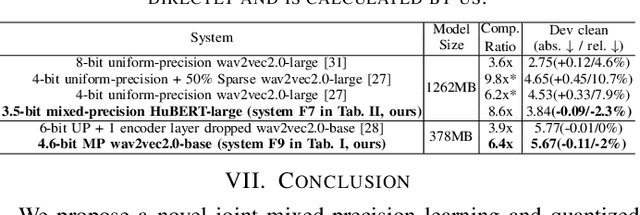
This paper presents a novel mixed-precision quantization approach for speech foundation models that tightly integrates mixed-precision learning and quantized model parameter estimation into one single model compression stage. Experiments conducted on LibriSpeech dataset with fine-tuned wav2vec2.0-base and HuBERT-large models suggest the resulting mixed-precision quantized models increased the lossless compression ratio by factors up to 1.7x and 1.9x over the respective uniform-precision and two-stage mixed-precision quantized baselines that perform precision learning and model parameters quantization in separate and disjointed stages, while incurring no statistically word error rate (WER) increase over the 32-bit full-precision models. The system compression time of wav2vec2.0-base and HuBERT-large models is reduced by up to 1.9 and 1.5 times over the two-stage mixed-precision baselines, while both produce lower WERs. The best-performing 3.5-bit mixed-precision quantized HuBERT-large model produces a lossless compression ratio of 8.6x over the 32-bit full-precision system.
Structured Speaker-Deficiency Adaptation of Foundation Models for Dysarthric and Elderly Speech Recognition
Dec 25, 2024

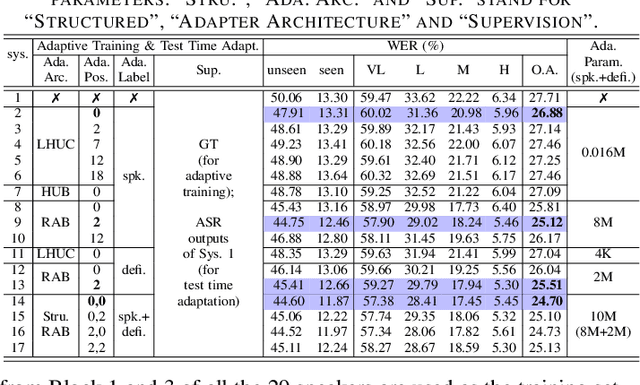

Data-intensive fine-tuning of speech foundation models (SFMs) to scarce and diverse dysarthric and elderly speech leads to data bias and poor generalization to unseen speakers. This paper proposes novel structured speaker-deficiency adaptation approaches for SSL pre-trained SFMs on such data. Speaker and speech deficiency invariant SFMs were constructed in their supervised adaptive fine-tuning stage to reduce undue bias to training data speakers, and serves as a more neutral and robust starting point for test time unsupervised adaptation. Speech variability attributed to speaker identity and speech impairment severity, or aging induced neurocognitive decline, are modelled using separate adapters that can be combined together to model any seen or unseen speaker. Experiments on the UASpeech dysarthric and DementiaBank Pitt elderly speech corpora suggest structured speaker-deficiency adaptation of HuBERT and Wav2vec2-conformer models consistently outperforms baseline SFMs using either: a) no adapters; b) global adapters shared among all speakers; or c) single attribute adapters modelling speaker or deficiency labels alone by statistically significant WER reductions up to 3.01% and 1.50% absolute (10.86% and 6.94% relative) on the two tasks respectively. The lowest published WER of 19.45% (49.34% on very low intelligibility, 33.17% on unseen words) is obtained on the UASpeech test set of 16 dysarthric speakers.
k2SSL: A Faster and Better Framework for Self-Supervised Speech Representation Learning
Nov 26, 2024Self-supervised learning (SSL) has achieved great success in speech-related tasks, driven by advancements in speech encoder architectures and the expansion of datasets. While Transformer and Conformer architectures have dominated SSL backbones, encoders like Zipformer, which excel in automatic speech recognition (ASR), remain unexplored in SSL. Concurrently, inefficiencies in data processing within existing SSL training frameworks, such as fairseq, pose challenges in managing the growing volumes of training data. To address these issues, we propose k2SSL, an open-source framework that offers faster, more memory-efficient, and better-performing self-supervised speech representation learning, with a focus on downstream ASR tasks. The optimized HuBERT and proposed Zipformer-based SSL systems exhibit substantial reductions in both training time and memory usage during SSL training. Experiments on LibriSpeech and Libri-Light demonstrate that Zipformer-based SSL systems significantly outperform comparable HuBERT and WavLM systems, achieving a relative WER reduction on dev-other/test-other of up to 34.8%/32.4% compared to HuBERT Base after supervised fine-tuning, along with a 3.5x pre-training speedup in total GPU hours.