 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGC-LoRA: Gated Convolutional LoRA for Parameter-Efficient Acoustic Adaptation
Jun 09, 2026Transformer-based Speech Foundation Models excel in most Automatic Speech Recognition tasks but often suffer performance degradation when applied to domains with mismatched acoustic characteristics. While Parameter Efficient Fine-Tuning (PEFT) methods, such as Low-Rank Adaptation (LoRA), adjust global attention, they lack the local context modeling crucial for capturing domain-specific variations. We propose GC-LoRA, a novel adapter architecture that injects Conformer-style local convolutional processing into pretrained Transformer encoders. By integrating a lightweight adapter to encoder attention output projections, our method efficiently captures local acoustic dependencies without disrupting pretrained global representations. Experiments across diverse datasets (acoustically-degraded, bandlimited, dialectal, child) demonstrate the efficacy of our approach, achieving Word Error Rate (WER) reductions of up to 10.9% compared to baselines while adding minimal trainable parameters.
Gumbel-BEARD: Automatic Layer Selection for Self-Supervised Adaptation of Whisper in Low-Resource Domains
Jun 09, 2026Speech foundation models often struggle in low-resource domains due to domain mismatch and data scarcity. We propose Gumbel-BEARD, a domain adaptation framework that automates Whisper encoder layer selection via an end-to-end trainable hard Gumbel-Softmax selector. It enables self-supervised adaptation with a BEST-RQ objective that dynamically adapts to target acoustic characteristics without manual tuning. Experiments on the MyST child speech corpus demonstrate efficiency and scalability: with 10 h of labeled data for fine-tuning, our method matches a fully supervised baseline trained on the complete 133 h labeled set. We establish new state-of-the-art word error rates (WERs) of 8.21% using Whisper-medium on MyST and 11.06% using Whisper-small on the OGI Spontaneous dataset. Evaluation on CORAAL further confirms robustness to adult dialectal domain shifts, with up to 6% relative WER reduction, highlighting the generalizability of our approach to diverse low-resource conditions.
Entropy-Aware Domain-Routed Mixture-of-Experts Speech-LLM Framework: A Case Study of Multi-Domain Child-Adult ASR
Jun 09, 2026While Speech Large Language Models (Speech-LLMs) have achieved strong performance on adult Automatic Speech Recognition (ASR), their effectiveness on child speech remains under-explored, and single models often struggle to handle diverse adult and child age groups simultaneously. This paper proposes a Mixture-of-Experts (MoE) Speech-LLM for unified ASR across adult and child speech spanning diverse environments and age groups. The framework employs a Classifier-based Domain Router (C-DR) with a coarse-to-fine strategy and integrates both a Mixture-of-Projectors (MoP) and a Mixture-of-LoRAs (MoL) to model domain-specific variations. To address routing uncertainty near domain boundaries, an Entropy-Aware Routing (EAR) mechanism is introduced to dynamically incorporate a shared expert. Experiments on public child corpora demonstrate consistent improvements over baselines while preserving adult ASR performance. To our knowledge, this is the first work leveraging Speech-LLMs for unified, multi-domain ASR encompassing both children and adults.
STACodec: Semantic Token Assignment for Balancing Acoustic Fidelity and Semantic Information in Audio Codecs
Feb 05, 2026Neural audio codecs are widely used for audio compression and can be integrated into token-based language models. Traditional codecs preserve acoustic details well but lack semantic information. Recent hybrid codecs attempt to incorporate semantic information through distillation, but this often degrades reconstruction performance, making it difficult to achieve both. To address this limitation, we introduce STACodec, a unified codec that integrates semantic information from self-supervised learning (SSL) models into the first layer of residual vector quantization (RVQ-1) via semantic token assignment (STA). To further eliminate reliance on SSL-based semantic tokenizers and improve efficiency during inference, we propose a semantic pre-distillation (SPD) module, which predicts semantic tokens directly for assignment to the first RVQ layer during inference. Experimental results show that STACodec outperforms existing hybrid codecs in both audio reconstruction and downstream semantic tasks, demonstrating a better balance between acoustic fidelity and semantic capability.
CHSER: A Dataset and Case Study on Generative Speech Error Correction for Child ASR
May 24, 2025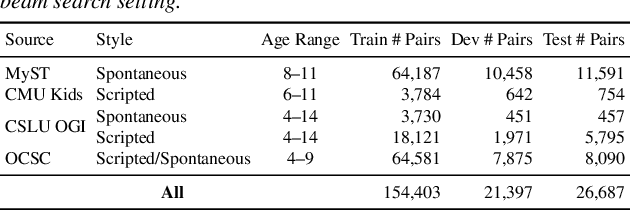
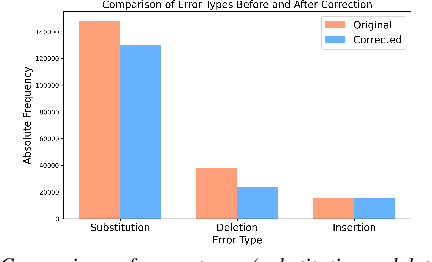
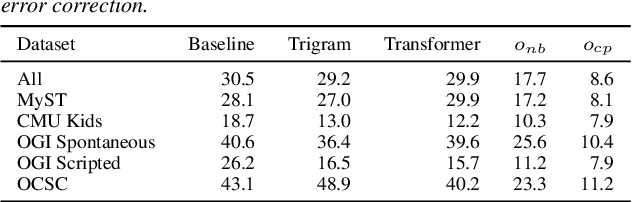
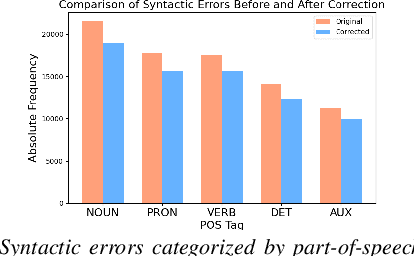
Automatic Speech Recognition (ASR) systems struggle with child speech due to its distinct acoustic and linguistic variability and limited availability of child speech datasets, leading to high transcription error rates. While ASR error correction (AEC) methods have improved adult speech transcription, their effectiveness on child speech remains largely unexplored. To address this, we introduce CHSER, a Generative Speech Error Correction (GenSEC) dataset for child speech, comprising 200K hypothesis-transcription pairs spanning diverse age groups and speaking styles. Results demonstrate that fine-tuning on the CHSER dataset achieves up to a 28.5% relative WER reduction in a zero-shot setting and a 13.3% reduction when applied to fine-tuned ASR systems. Additionally, our error analysis reveals that while GenSEC improves substitution and deletion errors, it struggles with insertions and child-specific disfluencies. These findings highlight the potential of GenSEC for improving child ASR.
LibriheavyMix: A 20,000-Hour Dataset for Single-Channel Reverberant Multi-Talker Speech Separation, ASR and Speaker Diarization
Sep 01, 2024



The evolving speech processing landscape is increasingly focused on complex scenarios like meetings or cocktail parties with multiple simultaneous speakers and far-field conditions. Existing methodologies for addressing these challenges fall into two categories: multi-channel and single-channel solutions. Single-channel approaches, notable for their generality and convenience, do not require specific information about microphone arrays. This paper presents a large-scale far-field overlapping speech dataset, crafted to advance research in speech separation, recognition, and speaker diarization. This dataset is a critical resource for decoding ``Who said What and When'' in multi-talker, reverberant environments, a daunting challenge in the field. Additionally, we introduce a pipeline system encompassing speech separation, recognition, and diarization as a foundational benchmark. Evaluations on the WHAMR! dataset validate the broad applicability of the proposed data.
Advancing Multi-talker ASR Performance with Large Language Models
Aug 30, 2024



Recognizing overlapping speech from multiple speakers in conversational scenarios is one of the most challenging problem for automatic speech recognition (ASR). Serialized output training (SOT) is a classic method to address multi-talker ASR, with the idea of concatenating transcriptions from multiple speakers according to the emission times of their speech for training. However, SOT-style transcriptions, derived from concatenating multiple related utterances in a conversation, depend significantly on modeling long contexts. Therefore, compared to traditional methods that primarily emphasize encoder performance in attention-based encoder-decoder (AED) architectures, a novel approach utilizing large language models (LLMs) that leverages the capabilities of pre-trained decoders may be better suited for such complex and challenging scenarios. In this paper, we propose an LLM-based SOT approach for multi-talker ASR, leveraging pre-trained speech encoder and LLM, fine-tuning them on multi-talker dataset using appropriate strategies. Experimental results demonstrate that our approach surpasses traditional AED-based methods on the simulated dataset LibriMix and achieves state-of-the-art performance on the evaluation set of the real-world dataset AMI, outperforming the AED model trained with 1000 times more supervised data in previous works.
SA-Paraformer: Non-autoregressive End-to-End Speaker-Attributed ASR
Oct 07, 2023



Joint modeling of multi-speaker ASR and speaker diarization has recently shown promising results in speaker-attributed automatic speech recognition (SA-ASR).Although being able to obtain state-of-the-art (SOTA) performance, most of the studies are based on an autoregressive (AR) decoder which generates tokens one-by-one and results in a large real-time factor (RTF). To speed up inference, we introduce a recently proposed non-autoregressive model Paraformer as an acoustic model in the SA-ASR model.Paraformer uses a single-step decoder to enable parallel generation, obtaining comparable performance to the SOTA AR transformer models. Besides, we propose a speaker-filling strategy to reduce speaker identification errors and adopt an inter-CTC strategy to enhance the encoder's ability in acoustic modeling. Experiments on the AliMeeting corpus show that our model outperforms the cascaded SA-ASR model by a 6.1% relative speaker-dependent character error rate (SD-CER) reduction on the test set. Moreover, our model achieves a comparable SD-CER of 34.8% with only 1/10 RTF compared with the SOTA joint AR SA-ASR model.
The second multi-channel multi-party meeting transcription challenge 2.0): A benchmark for speaker-attributed ASR
Sep 24, 2023



With the success of the first Multi-channel Multi-party Meeting Transcription challenge (M2MeT), the second M2MeT challenge (M2MeT 2.0) held in ASRU2023 particularly aims to tackle the complex task of speaker-attributed ASR (SA-ASR), which directly addresses the practical and challenging problem of "who spoke what at when" at typical meeting scenario. We particularly established two sub-tracks. 1) The fixed training condition sub-track, where the training data is constrained to predetermined datasets, but participants can use any open-source pre-trained model. 2) The open training condition sub-track, which allows for the use of all available data and models. In addition, we release a new 10-hour test set for challenge ranking. This paper provides an overview of the dataset, track settings, results, and analysis of submitted systems, as a benchmark to show the current state of speaker-attributed ASR.
CASA-ASR: Context-Aware Speaker-Attributed ASR
May 21, 2023



Recently, speaker-attributed automatic speech recognition (SA-ASR) has attracted a wide attention, which aims at answering the question ``who spoke what''. Different from modular systems, end-to-end (E2E) SA-ASR minimizes the speaker-dependent recognition errors directly and shows a promising applicability. In this paper, we propose a context-aware SA-ASR (CASA-ASR) model by enhancing the contextual modeling ability of E2E SA-ASR. Specifically, in CASA-ASR, a contextual text encoder is involved to aggregate the semantic information of the whole utterance, and a context-dependent scorer is employed to model the speaker discriminability by contrasting with speakers in the context. In addition, a two-pass decoding strategy is further proposed to fully leverage the contextual modeling ability resulting in a better recognition performance. Experimental results on AliMeeting corpus show that the proposed CASA-ASR model outperforms the original E2E SA-ASR system with a relative improvement of 11.76% in terms of speaker-dependent character error rate.