 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffAttack: Diffusion-based Timbre-reserved Adversarial Attack in Speaker Identification
Jan 09, 2025



Being a form of biometric identification, the security of the speaker identification (SID) system is of utmost importance. To better understand the robustness of SID systems, we aim to perform more realistic attacks in SID, which are challenging for both humans and machines to detect. In this study, we propose DiffAttack, a novel timbre-reserved adversarial attack approach that exploits the capability of a diffusion-based voice conversion (DiffVC) model to generate adversarial fake audio with distinct target speaker attribution. By introducing adversarial constraints into the generative process of the diffusion-based voice conversion model, we craft fake samples that effectively mislead target models while preserving speaker-wise characteristics. Specifically, inspired by the use of randomly sampled Gaussian noise in conventional adversarial attacks and diffusion processes, we incorporate adversarial constraints into the reverse diffusion process. These constraints subtly guide the reverse diffusion process toward aligning with the target speaker distribution. Our experiments on the LibriTTS dataset indicate that DiffAttack significantly improves the attack success rate compared to vanilla DiffVC and other methods. Moreover, objective and subjective evaluations demonstrate that introducing adversarial constraints does not compromise the speech quality generated by the DiffVC model.
SQ-Whisper: Speaker-Querying based Whisper Model for Target-Speaker ASR
Dec 07, 2024Benefiting from massive and diverse data sources, speech foundation models exhibit strong generalization and knowledge transfer capabilities to a wide range of downstream tasks. However, a limitation arises from their exclusive handling of single-speaker speech input, making them ineffective in recognizing multi-speaker overlapped speech, a common occurrence in real-world scenarios. In this study, we delve into the adaptation of speech foundation models to eliminate interfering speakers from overlapping speech and perform target-speaker automatic speech recognition (TS-ASR). Initially, we utilize the Whisper model as the foundation for adaptation and conduct a thorough comparison of its integration with existing target-speaker adaptation techniques. We then propose an innovative model termed Speaker-Querying Whisper (SQ-Whisper), which employs a set number of trainable queries to capture speaker prompts from overlapping speech based on target-speaker enrollment. These prompts serve to steer the model in extracting speaker-specific features and accurately recognizing target-speaker transcriptions. Experimental results demonstrate that our approach effectively adapts the pre-trained speech foundation model to TS-ASR. Compared with the robust TS-HuBERT model, the proposed SQ-Whisper significantly improves performance, yielding up to 15% and 10% relative reductions in word error rates (WERs) on the Libri2Mix and WSJ0-2Mix datasets, respectively. With data augmentation, we establish new state-of-the-art WERs of 14.6% on the Libri2Mix Test set and 4.4% on the WSJ0-2Mix Test set. Furthermore, we evaluate our model on the real-world AMI meeting dataset, which shows consistent improvement over other adaptation methods.
Optimizing Dysarthria Wake-Up Word Spotting: An End-to-End Approach for SLT 2024 LRDWWS Challenge
Sep 16, 2024Speech has emerged as a widely embraced user interface across diverse applications. However, for individuals with dysarthria, the inherent variability in their speech poses significant challenges. This paper presents an end-to-end Pretrain-based Dual-filter Dysarthria Wake-up word Spotting (PD-DWS) system for the SLT 2024 Low-Resource Dysarthria Wake-Up Word Spotting Challenge. Specifically, our system improves performance from two key perspectives: audio modeling and dual-filter strategy. For audio modeling, we propose an innovative 2branch-d2v2 model based on the pre-trained data2vec2 (d2v2), which can simultaneously model automatic speech recognition (ASR) and wake-up word spotting (WWS) tasks through a unified multi-task finetuning paradigm. Additionally, a dual-filter strategy is introduced to reduce the false accept rate (FAR) while maintaining the same false reject rate (FRR). Experimental results demonstrate that our PD-DWS system achieves an FAR of 0.00321 and an FRR of 0.005, with a total score of 0.00821 on the test-B eval set, securing first place in the challenge.
NPU-NTU System for Voice Privacy 2024 Challenge
Sep 06, 2024

Speaker anonymization is an effective privacy protection solution that conceals the speaker's identity while preserving the linguistic content and paralinguistic information of the original speech. To establish a fair benchmark and facilitate comparison of speaker anonymization systems, the VoicePrivacy Challenge (VPC) was held in 2020 and 2022, with a new edition planned for 2024. In this paper, we describe our proposed speaker anonymization system for VPC 2024. Our system employs a disentangled neural codec architecture and a serial disentanglement strategy to gradually disentangle the global speaker identity and time-variant linguistic content and paralinguistic information. We introduce multiple distillation methods to disentangle linguistic content, speaker identity, and emotion. These methods include semantic distillation, supervised speaker distillation, and frame-level emotion distillation. Based on these distillations, we anonymize the original speaker identity using a weighted sum of a set of candidate speaker identities and a randomly generated speaker identity. Our system achieves the best trade-off of privacy protection and emotion preservation in VPC 2024.
Leveraging Open Knowledge for Advancing Task Expertise in Large Language Models
Aug 28, 2024



The cultivation of expertise for large language models (LLMs) to solve tasks of specific areas often requires special-purpose tuning with calibrated behaviors on the expected stable outputs. To avoid huge cost brought by manual preparation of instruction datasets and training resources up to hundreds of hours, the exploitation of open knowledge including a wealth of low rank adaptation (LoRA) models and instruction datasets serves as a good starting point. However, existing methods on model and data selection focus on the performance of general-purpose capabilities while neglecting the knowledge gap exposed in domain-specific deployment. In the present study, we propose to bridge such gap by introducing few human-annotated samples (i.e., K-shot) for advancing task expertise of LLMs with open knowledge. Specifically, we develop an efficient and scalable pipeline to cost-efficiently produce task experts where K-shot data intervene in selecting the most promising expert candidates and the task-relevant instructions. A mixture-of-expert (MoE) system is built to make the best use of individual-yet-complementary knowledge between multiple experts. We unveil the two keys to the success of a MoE system, 1) the abidance by K-shot, and 2) the insistence on diversity. For the former, we ensure that models that truly possess problem-solving abilities on K-shot are selected rather than those blind guessers. Besides, during data selection, instructions that share task-relevant contexts with K-shot are prioritized. For the latter, we highlight the diversity of constituting experts and that of the fine-tuning instructions throughout the model and data selection process. Extensive experimental results confirm the superiority of our approach over existing methods on utilization of open knowledge across various tasks. Codes and models will be released later.
Towards Rehearsal-Free Multilingual ASR: A LoRA-based Case Study on Whisper
Aug 20, 2024



Pre-trained multilingual speech foundation models, like Whisper, have shown impressive performance across different languages. However, adapting these models to new or specific languages is computationally extensive and faces catastrophic forgetting problems. Addressing these issues, our study investigates strategies to enhance the model on new languages in the absence of original training data, while also preserving the established performance on the original languages. Specifically, we first compare various LoRA-based methods to find out their vulnerability to forgetting. To mitigate this issue, we propose to leverage the LoRA parameters from the original model for approximate orthogonal gradient descent on the new samples. Additionally, we also introduce a learnable rank coefficient to allocate trainable parameters for more efficient training. Our experiments with a Chinese Whisper model (for Uyghur and Tibetan) yield better results with a more compact parameter set.
Unleashing the Power of Data Tsunami: A Comprehensive Survey on Data Assessment and Selection for Instruction Tuning of Language Models
Aug 07, 2024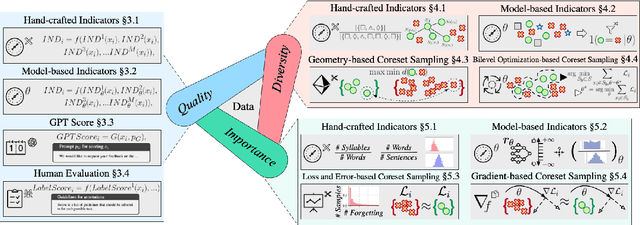
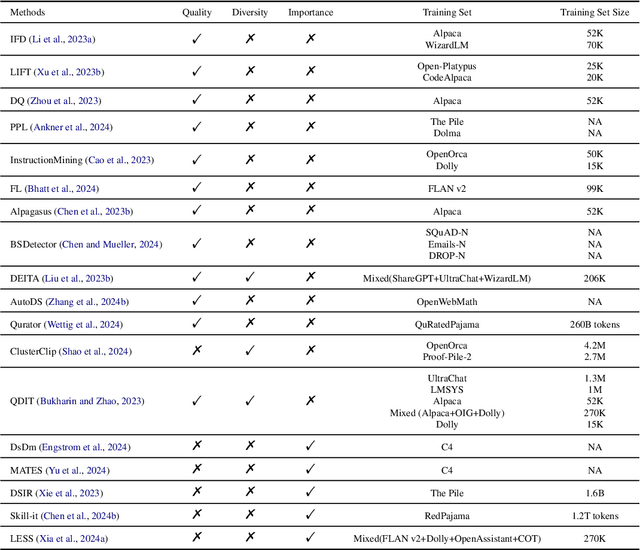
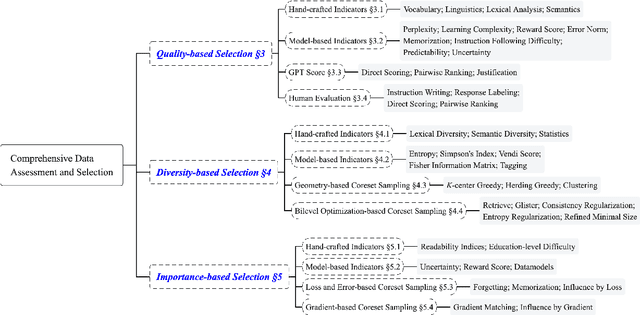
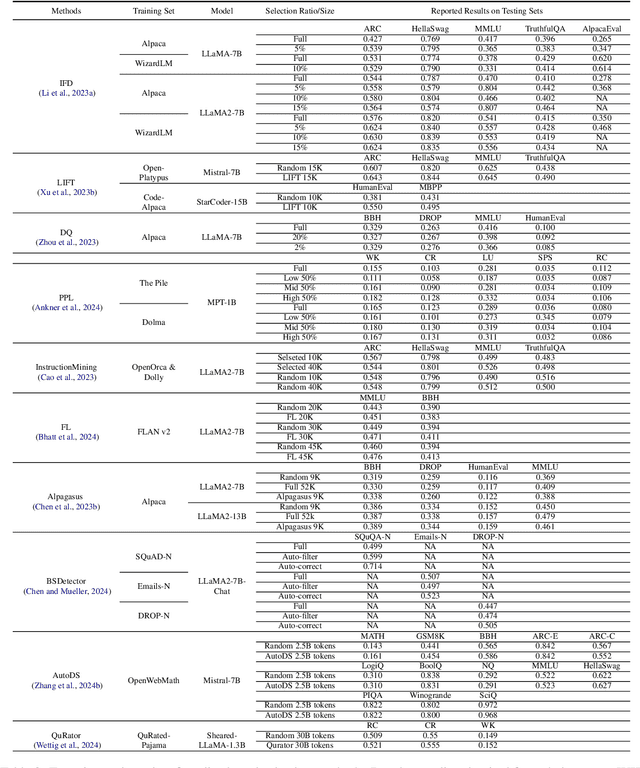
Instruction tuning plays a critical role in aligning large language models (LLMs) with human preference. Despite the vast amount of open instruction datasets, naively training a LLM on all existing instructions may not be optimal and practical. To pinpoint the most beneficial datapoints, data assessment and selection methods have been proposed in the fields of natural language processing (NLP) and deep learning. However, under the context of instruction tuning, there still exists a gap in knowledge on what kind of data evaluation metrics can be employed and how they can be integrated into the selection mechanism. To bridge this gap, we present a comprehensive review on existing literature of data assessment and selection especially for instruction tuning of LLMs. We systematically categorize all applicable methods into quality-based, diversity-based, and importance-based ones where a unified, fine-grained taxonomy is structured. For each category, representative methods are elaborated to describe the landscape of relevant research. In addition, comparison between latest methods is conducted on their officially reported results to provide in-depth discussions on their limitations. Finally, we summarize the open challenges and propose the promosing avenues for future studies. All related contents are available at https://github.com/yuleiqin/fantastic-data-engineering.
CRMSP: A Semi-supervised Approach for Key Information Extraction with Class-Rebalancing and Merged Semantic Pseudo-Labeling
Jul 19, 2024There is a growing demand in the field of KIE (Key Information Extraction) to apply semi-supervised learning to save manpower and costs, as training document data using fully-supervised methods requires labor-intensive manual annotation. The main challenges of applying SSL in the KIE are (1) underestimation of the confidence of tail classes in the long-tailed distribution and (2) difficulty in achieving intra-class compactness and inter-class separability of tail features. To address these challenges, we propose a novel semi-supervised approach for KIE with Class-Rebalancing and Merged Semantic Pseudo-Labeling (CRMSP). Firstly, the Class-Rebalancing Pseudo-Labeling (CRP) module introduces a reweighting factor to rebalance pseudo-labels, increasing attention to tail classes. Secondly, we propose the Merged Semantic Pseudo-Labeling (MSP) module to cluster tail features of unlabeled data by assigning samples to Merged Prototypes (MP). Additionally, we designed a new contrastive loss specifically for MSP. Extensive experimental results on three well-known benchmarks demonstrate that CRMSP achieves state-of-the-art performance. Remarkably, CRMSP achieves 3.24% f1-score improvement over state-of-the-art on the CORD.
MUSA: Multi-lingual Speaker Anonymization via Serial Disentanglement
Jul 16, 2024



Speaker anonymization is an effective privacy protection solution designed to conceal the speaker's identity while preserving the linguistic content and para-linguistic information of the original speech. While most prior studies focus solely on a single language, an ideal speaker anonymization system should be capable of handling multiple languages. This paper proposes MUSA, a Multi-lingual Speaker Anonymization approach that employs a serial disentanglement strategy to perform a step-by-step disentanglement from a global time-invariant representation to a temporal time-variant representation. By utilizing semantic distillation and self-supervised speaker distillation, the serial disentanglement strategy can avoid strong inductive biases and exhibit superior generalization performance across different languages. Meanwhile, we propose a straightforward anonymization strategy that employs empty embedding with zero values to simulate the speaker identity concealment process, eliminating the need for conversion to a pseudo-speaker identity and thereby reducing the complexity of speaker anonymization process. Experimental results on VoicePrivacy official datasets and multi-lingual datasets demonstrate that MUSA can effectively protect speaker privacy while preserving linguistic content and para-linguistic information.
Distinctive and Natural Speaker Anonymization via Singular Value Transformation-assisted Matrix
May 17, 2024



Speaker anonymization is an effective privacy protection solution that aims to conceal the speaker's identity while preserving the naturalness and distinctiveness of the original speech. Mainstream approaches use an utterance-level vector from a pre-trained automatic speaker verification (ASV) model to represent speaker identity, which is then averaged or modified for anonymization. However, these systems suffer from deterioration in the naturalness of anonymized speech, degradation in speaker distinctiveness, and severe privacy leakage against powerful attackers. To address these issues and especially generate more natural and distinctive anonymized speech, we propose a novel speaker anonymization approach that models a matrix related to speaker identity and transforms it into an anonymized singular value transformation-assisted matrix to conceal the original speaker identity. Our approach extracts frame-level speaker vectors from a pre-trained ASV model and employs an attention mechanism to create a speaker-score matrix and speaker-related tokens. Notably, the speaker-score matrix acts as the weight for the corresponding speaker-related token, representing the speaker's identity. The singular value transformation-assisted matrix is generated by recomposing the decomposed orthonormal eigenvectors matrix and non-linear transformed singular through Singular Value Decomposition (SVD). Experiments on VoicePrivacy Challenge datasets demonstrate the effectiveness of our approach in protecting speaker privacy under all attack scenarios while maintaining speech naturalness and distinctiveness.