 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe TEA-ASLP System for Multilingual Conversational Speech Recognition and Speech Diarization in MLC-SLM 2025 Challenge
Jul 24, 2025This paper presents the TEA-ASLP's system submitted to the MLC-SLM 2025 Challenge, addressing multilingual conversational automatic speech recognition (ASR) in Task I and speech diarization ASR in Task II. For Task I, we enhance Ideal-LLM model by integrating known language identification and a multilingual MOE LoRA structure, along with using CTC-predicted tokens as prompts to improve autoregressive generation. The model is trained on approximately 180k hours of multilingual ASR data. In Task II, we replace the baseline English-Chinese speaker diarization model with a more suitable English-only version. Our approach achieves a 30.8% reduction in word error rate (WER) compared to the baseline speech language model, resulting in a final WER of 9.60% in Task I and a time-constrained minimum-permutation WER of 17.49% in Task II, earning first and second place in the respective challenge tasks.
Towards Rehearsal-Free Multilingual ASR: A LoRA-based Case Study on Whisper
Aug 20, 2024



Pre-trained multilingual speech foundation models, like Whisper, have shown impressive performance across different languages. However, adapting these models to new or specific languages is computationally extensive and faces catastrophic forgetting problems. Addressing these issues, our study investigates strategies to enhance the model on new languages in the absence of original training data, while also preserving the established performance on the original languages. Specifically, we first compare various LoRA-based methods to find out their vulnerability to forgetting. To mitigate this issue, we propose to leverage the LoRA parameters from the original model for approximate orthogonal gradient descent on the new samples. Additionally, we also introduce a learnable rank coefficient to allocate trainable parameters for more efficient training. Our experiments with a Chinese Whisper model (for Uyghur and Tibetan) yield better results with a more compact parameter set.
U2-KWS: Unified Two-pass Open-vocabulary Keyword Spotting with Keyword Bias
Dec 15, 2023Open-vocabulary keyword spotting (KWS), which allows users to customize keywords, has attracted increasingly more interest. However, existing methods based on acoustic models and post-processing train the acoustic model with ASR training criteria to model all phonemes, making the acoustic model under-optimized for the KWS task. To solve this problem, we propose a novel unified two-pass open-vocabulary KWS (U2-KWS) framework inspired by the two-pass ASR model U2. Specifically, we employ the CTC branch as the first stage model to detect potential keyword candidates and the decoder branch as the second stage model to validate candidates. In order to enhance any customized keywords, we redesign the U2 training procedure for U2-KWS and add keyword information by audio and text cross-attention into both branches. We perform experiments on our internal dataset and Aishell-1. The results show that U2-KWS can achieve a significant relative wake-up rate improvement of 41% compared to the traditional customized KWS systems when the false alarm rate is fixed to 0.5 times per hour.
Spike-Triggered Contextual Biasing for End-to-End Mandarin Speech Recognition
Oct 07, 2023



The attention-based deep contextual biasing method has been demonstrated to effectively improve the recognition performance of end-to-end automatic speech recognition (ASR) systems on given contextual phrases. However, unlike shallow fusion methods that directly bias the posterior of the ASR model, deep biasing methods implicitly integrate contextual information, making it challenging to control the degree of bias. In this study, we introduce a spike-triggered deep biasing method that simultaneously supports both explicit and implicit bias. Moreover, both bias approaches exhibit significant improvements and can be cascaded with shallow fusion methods for better results. Furthermore, we propose a context sampling enhancement strategy and improve the contextual phrase filtering algorithm. Experiments on the public WenetSpeech Mandarin biased-word dataset show a 32.0% relative CER reduction compared to the baseline model, with an impressively 68.6% relative CER reduction on contextual phrases.
SSHR: Leveraging Self-supervised Hierarchical Representations for Multilingual Automatic Speech Recognition
Sep 29, 2023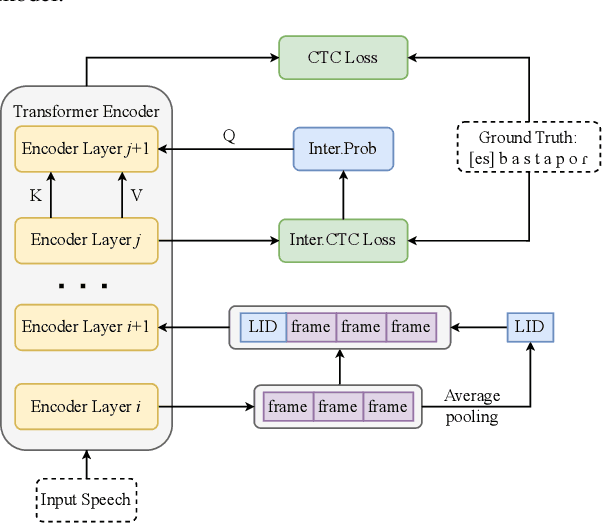
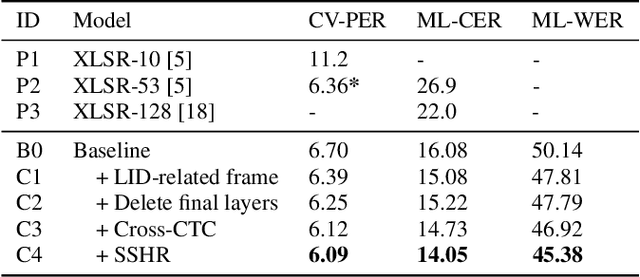

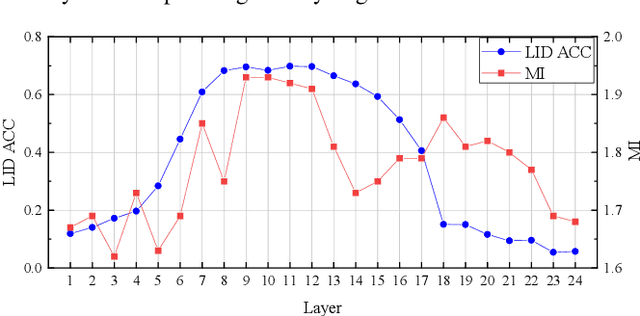
Multilingual automatic speech recognition (ASR) systems have garnered attention for their potential to extend language coverage globally. While self-supervised learning (SSL) has demonstrated its effectiveness in multilingual ASR, it is worth noting that the various layers' representations of SSL potentially contain distinct information that has not been fully leveraged. In this study, we propose a novel method that leverages self-supervised hierarchical representations (SSHR) to fine-tune multilingual ASR. We first analyze the different layers of the SSL model for language-related and content-related information, uncovering layers that show a stronger correlation. Then, we extract a language-related frame from correlated middle layers and guide specific content extraction through self-attention mechanisms. Additionally, we steer the model toward acquiring more content-related information in the final layers using our proposed Cross-CTC. We evaluate SSHR on two multilingual datasets, Common Voice and ML-SUPERB, and the experimental results demonstrate that our method achieves state-of-the-art performance to the best of our knowledge.
Adaptive Contextual Biasing for Transducer Based Streaming Speech Recognition
Jun 01, 2023By incorporating additional contextual information, deep biasing methods have emerged as a promising solution for speech recognition of personalized words. However, for real-world voice assistants, always biasing on such personalized words with high prediction scores can significantly degrade the performance of recognizing common words. To address this issue, we propose an adaptive contextual biasing method based on Context-Aware Transformer Transducer (CATT) that utilizes the biased encoder and predictor embeddings to perform streaming prediction of contextual phrase occurrences. Such prediction is then used to dynamically switch the bias list on and off, enabling the model to adapt to both personalized and common scenarios. Experiments on Librispeech and internal voice assistant datasets show that our approach can achieve up to 6.7% and 20.7% relative reduction in WER and CER compared to the baseline respectively, mitigating up to 96.7% and 84.9% of the relative WER and CER increase for common cases. Furthermore, our approach has a minimal performance impact in personalized scenarios while maintaining a streaming inference pipeline with negligible RTF increase.
Contextualized End-to-End Speech Recognition with Contextual Phrase Prediction Network
May 21, 2023



Contextual information plays a crucial role in speech recognition technologies and incorporating it into the end-to-end speech recognition models has drawn immense interest recently. However, previous deep bias methods lacked explicit supervision for bias tasks. In this study, we introduce a contextual phrase prediction network for an attention-based deep bias method. This network predicts context phrases in utterances using contextual embeddings and calculates bias loss to assist in the training of the contextualized model. Our method achieved a significant word error rate (WER) reduction across various end-to-end speech recognition models. Experiments on the LibriSpeech corpus show that our proposed model obtains a 12.1% relative WER improvement over the baseline model, and the WER of the context phrases decreases relatively by 40.5%. Moreover, by applying a context phrase filtering strategy, we also effectively eliminate the WER degradation when using a larger biasing list.
The ISCSLP 2022 Intelligent Cockpit Speech Recognition Challenge (ICSRC): Dataset, Tracks, Baseline and Results
Nov 03, 2022



This paper summarizes the outcomes from the ISCSLP 2022 Intelligent Cockpit Speech Recognition Challenge (ICSRC). We first address the necessity of the challenge and then introduce the associated dataset collected from a new-energy vehicle (NEV) covering a variety of cockpit acoustic conditions and linguistic contents. We then describe the track arrangement and the baseline system. Specifically, we set up two tracks in terms of allowed model/system size to investigate resource-constrained and -unconstrained setups, targeting to vehicle embedded as well as cloud ASR systems respectively. Finally we summarize the challenge results and provide the major observations from the submitted systems.