 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSHR: Leveraging Self-supervised Hierarchical Representations for Multilingual Automatic Speech Recognition
Paper and Code
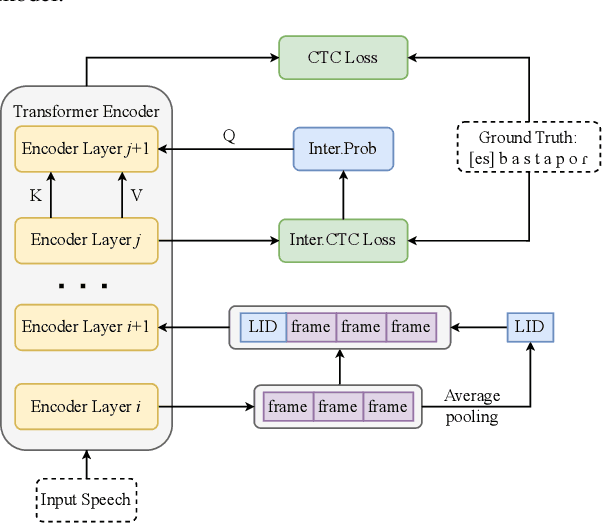
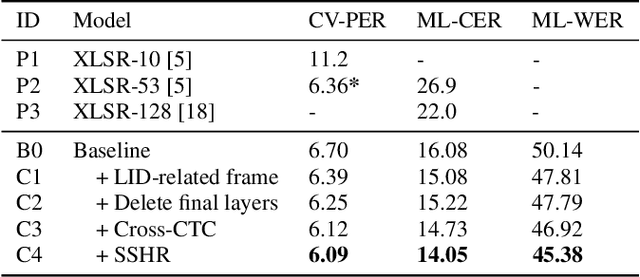

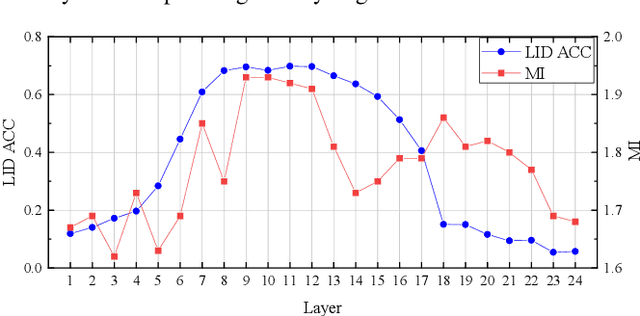
Multilingual automatic speech recognition (ASR) systems have garnered attention for their potential to extend language coverage globally. While self-supervised learning (SSL) has demonstrated its effectiveness in multilingual ASR, it is worth noting that the various layers' representations of SSL potentially contain distinct information that has not been fully leveraged. In this study, we propose a novel method that leverages self-supervised hierarchical representations (SSHR) to fine-tune multilingual ASR. We first analyze the different layers of the SSL model for language-related and content-related information, uncovering layers that show a stronger correlation. Then, we extract a language-related frame from correlated middle layers and guide specific content extraction through self-attention mechanisms. Additionally, we steer the model toward acquiring more content-related information in the final layers using our proposed Cross-CTC. We evaluate SSHR on two multilingual datasets, Common Voice and ML-SUPERB, and the experimental results demonstrate that our method achieves state-of-the-art performance to the best of our knowledge.