 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDMoLE: Mixture of LoRA Experts with Hierarchical Routing and Dynamic Thresholds for Fine-Tuning LLM-based ASR Models
Sep 30, 2024



Recent advancements in integrating Large Language Models (LLM) with automatic speech recognition (ASR) have performed remarkably in general domains. While supervised fine-tuning (SFT) of all model parameters is often employed to adapt pre-trained LLM-based ASR models to specific domains, it imposes high computational costs and notably reduces their performance in general domains. In this paper, we propose a novel parameter-efficient multi-domain fine-tuning method for adapting pre-trained LLM-based ASR models to multi-accent domains without catastrophic forgetting named \textit{HDMoLE}, which leverages hierarchical routing and dynamic thresholds based on combining low-rank adaptation (LoRA) with the mixer of experts (MoE) and can be generalized to any linear layer. Hierarchical routing establishes a clear correspondence between LoRA experts and accent domains, improving cross-domain collaboration among the LoRA experts. Unlike the static Top-K strategy for activating LoRA experts, dynamic thresholds can adaptively activate varying numbers of LoRA experts at each MoE layer. Experiments on the multi-accent and standard Mandarin datasets demonstrate the efficacy of HDMoLE. Applying HDMoLE to an LLM-based ASR model projector module achieves similar performance to full fine-tuning in the target multi-accent domains while using only 9.6% of the trainable parameters required for full fine-tuning and minimal degradation in the source general domain.
Ideal-LLM: Integrating Dual Encoders and Language-Adapted LLM for Multilingual Speech-to-Text
Sep 17, 2024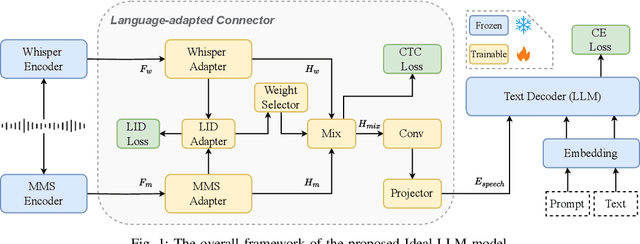
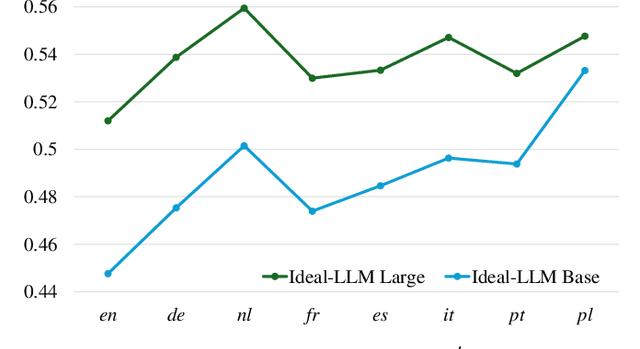
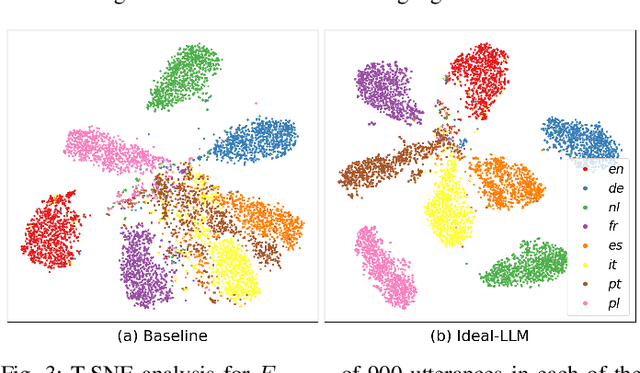

Integrating audio encoders with LLMs through connectors has enabled these models to process and comprehend audio modalities, significantly enhancing speech-to-text tasks, including automatic speech recognition (ASR) and automatic speech translation (AST). However, these methods often overlook the critical aspect of language adaptation in multilingual settings, relying instead on multilingual data without adequately addressing language differences. To address this gap, we propose the Ideal-LLM model, which employs dual multilingual encoders to enrich language feature information and utilizes a language-adapted connector to target the adaptation of each language specifically. By leveraging the complementary strengths of Whisper and MMS encoders, our approach ensures richer multilingual representations. Additionally, the language-adapted connector enhances modal transformation via a language weight selector tailored for each language. Experimental results demonstrate that Ideal-LLM significantly improves ASR performance, achieving a 32.6% relative reduction in average word error rates compared to the standard speech encoder integrated with LLMs and yields an average BLEU score of 36.78 for AST task.
MMGER: Multi-modal and Multi-granularity Generative Error Correction with LLM for Joint Accent and Speech Recognition
May 06, 2024



Despite notable advancements in automatic speech recognition (ASR), performance tends to degrade when faced with adverse conditions. Generative error correction (GER) leverages the exceptional text comprehension capabilities of large language models (LLM), delivering impressive performance in ASR error correction, where N-best hypotheses provide valuable information for transcription prediction. However, GER encounters challenges such as fixed N-best hypotheses, insufficient utilization of acoustic information, and limited specificity to multi-accent scenarios. In this paper, we explore the application of GER in multi-accent scenarios. Accents represent deviations from standard pronunciation norms, and the multi-task learning framework for simultaneous ASR and accent recognition (AR) has effectively addressed the multi-accent scenarios, making it a prominent solution. In this work, we propose a unified ASR-AR GER model, named MMGER, leveraging multi-modal correction, and multi-granularity correction. Multi-task ASR-AR learning is employed to provide dynamic 1-best hypotheses and accent embeddings. Multi-modal correction accomplishes fine-grained frame-level correction by force-aligning the acoustic features of speech with the corresponding character-level 1-best hypothesis sequence. Multi-granularity correction supplements the global linguistic information by incorporating regular 1-best hypotheses atop fine-grained multi-modal correction to achieve coarse-grained utterance-level correction. MMGER effectively mitigates the limitations of GER and tailors LLM-based ASR error correction for the multi-accent scenarios. Experiments conducted on the multi-accent Mandarin KeSpeech dataset demonstrate the efficacy of MMGER, achieving a 26.72% relative improvement in AR accuracy and a 27.55% relative reduction in ASR character error rate, compared to a well-established standard baseline.
Decoupling and Interacting Multi-Task Learning Network for Joint Speech and Accent Recognition
Nov 17, 2023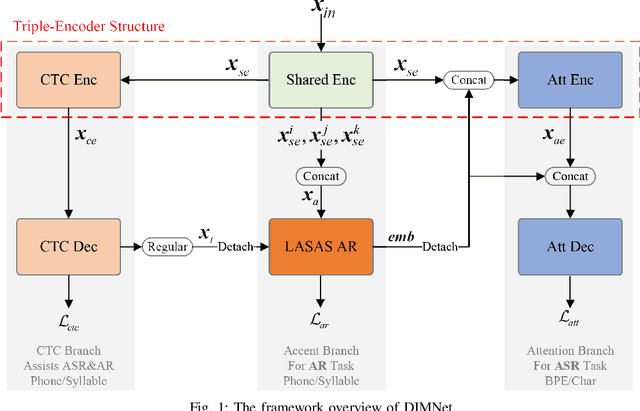

Accents, as variations from standard pronunciation, pose significant challenges for speech recognition systems. Although joint automatic speech recognition (ASR) and accent recognition (AR) training has been proven effective in handling multi-accent scenarios, current multi-task ASR-AR approaches overlook the granularity differences between tasks. Fine-grained units capture pronunciation-related accent characteristics, while coarse-grained units are better for learning linguistic information. Moreover, an explicit interaction of two tasks can also provide complementary information and improve the performance of each other, but it is rarely used by existing approaches. In this paper, we propose a novel Decoupling and Interacting Multi-task Network (DIMNet) for joint speech and accent recognition, which is comprised of a connectionist temporal classification (CTC) branch, an AR branch, an ASR branch, and a bottom feature encoder. Specifically, AR and ASR are first decoupled by separated branches and two-granular modeling units to learn task-specific representations. The AR branch is from our previously proposed linguistic-acoustic bimodal AR model and the ASR branch is an encoder-decoder based Conformer model. Then, for the task interaction, the CTC branch provides aligned text for the AR task, while accent embeddings extracted from our AR model are incorporated into the ASR branch's encoder and decoder. Finally, during ASR inference, a cross-granular rescoring method is introduced to fuse the complementary information from the CTC and attention decoder after the decoupling. Our experiments on English and Chinese datasets demonstrate the effectiveness of the proposed model, which achieves 21.45%/28.53% AR accuracy relative improvement and 32.33%/14.55% ASR error rate relative reduction over a published standard baseline, respectively.
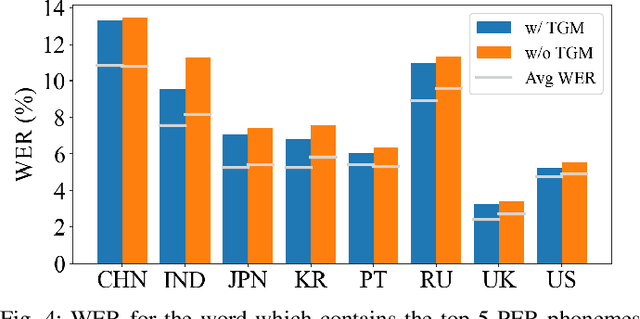
SSHR: Leveraging Self-supervised Hierarchical Representations for Multilingual Automatic Speech Recognition
Sep 29, 2023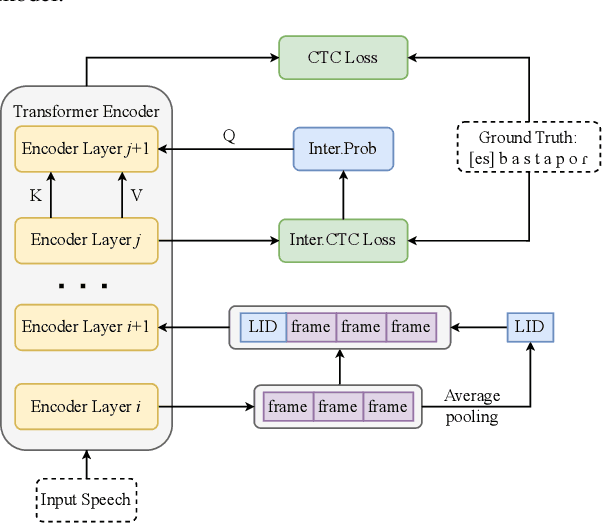
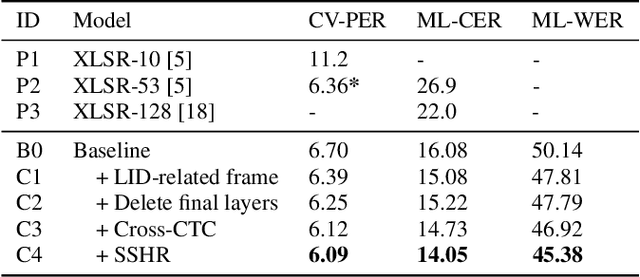

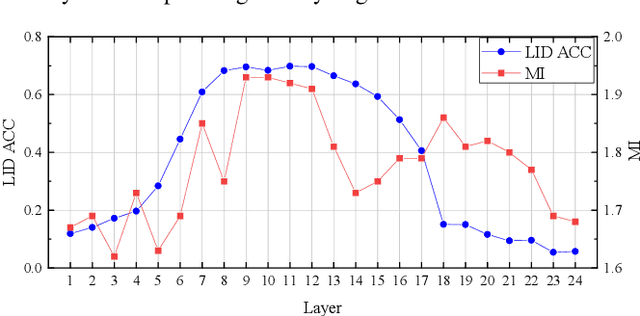
Multilingual automatic speech recognition (ASR) systems have garnered attention for their potential to extend language coverage globally. While self-supervised learning (SSL) has demonstrated its effectiveness in multilingual ASR, it is worth noting that the various layers' representations of SSL potentially contain distinct information that has not been fully leveraged. In this study, we propose a novel method that leverages self-supervised hierarchical representations (SSHR) to fine-tune multilingual ASR. We first analyze the different layers of the SSL model for language-related and content-related information, uncovering layers that show a stronger correlation. Then, we extract a language-related frame from correlated middle layers and guide specific content extraction through self-attention mechanisms. Additionally, we steer the model toward acquiring more content-related information in the final layers using our proposed Cross-CTC. We evaluate SSHR on two multilingual datasets, Common Voice and ML-SUPERB, and the experimental results demonstrate that our method achieves state-of-the-art performance to the best of our knowledge.
TranUSR: Phoneme-to-word Transcoder Based Unified Speech Representation Learning for Cross-lingual Speech Recognition
May 23, 2023



UniSpeech has achieved superior performance in cross-lingual automatic speech recognition (ASR) by explicitly aligning latent representations to phoneme units using multi-task self-supervised learning. While the learned representations transfer well from high-resource to low-resource languages, predicting words directly from these phonetic representations in downstream ASR is challenging. In this paper, we propose TranUSR, a two-stage model comprising a pre-trained UniData2vec and a phoneme-to-word Transcoder. Different from UniSpeech, UniData2vec replaces the quantized discrete representations with continuous and contextual representations from a teacher model for phonetically-aware pre-training. Then, Transcoder learns to translate phonemes to words with the aid of extra texts, enabling direct word generation. Experiments on Common Voice show that UniData2vec reduces PER by 5.3\% compared to UniSpeech, while Transcoder yields a 14.4\% WER reduction compared to grapheme fine-tuning.
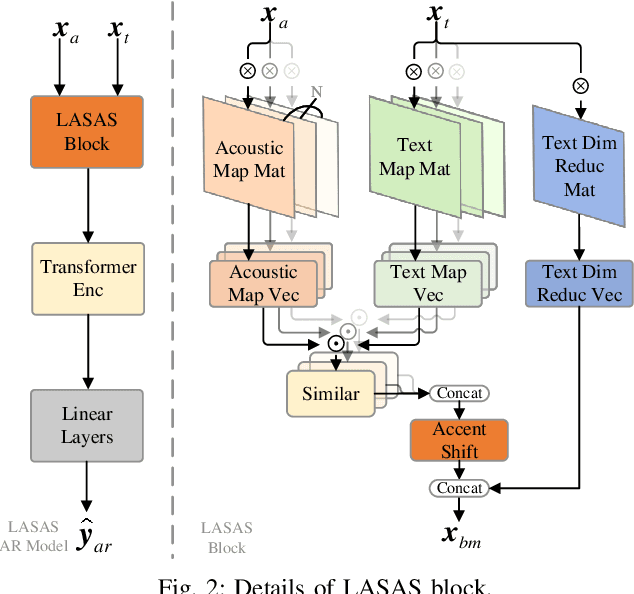
Linguistic-Acoustic Similarity Based Accent Shift for Accent Recognition
Apr 07, 2022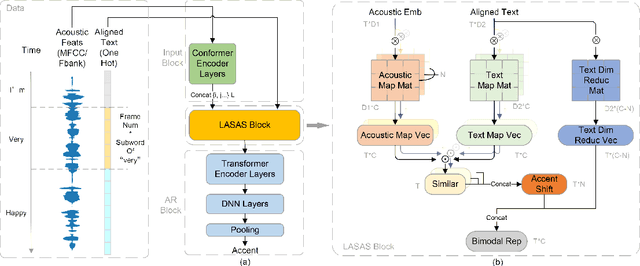
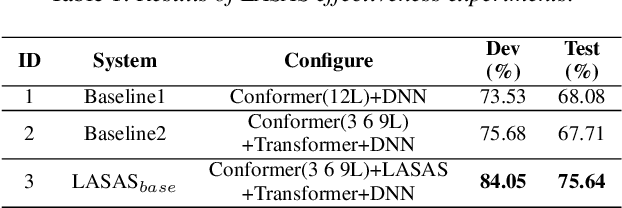
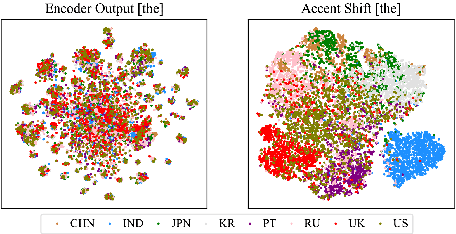
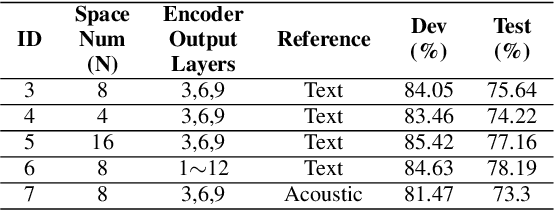
General accent recognition (AR) models tend to directly extract low-level information from spectrums, which always significantly overfit on speakers or channels. Considering accent can be regarded as a series of shifts relative to native pronunciation, distinguishing accents will be an easier task with accent shift as input. But due to the lack of native utterance as an anchor, estimating the accent shift is difficult. In this paper, we propose linguistic-acoustic similarity based accent shift (LASAS) for AR tasks. For an accent speech utterance, after mapping the corresponding text vector to multiple accent-associated spaces as anchors, its accent shift could be estimated by the similarities between the acoustic embedding and those anchors. Then, we concatenate the accent shift with a dimension-reduced text vector to obtain a linguistic-acoustic bimodal representation. Compared with pure acoustic embedding, the bimodal representation is richer and more clear by taking full advantage of both linguistic and acoustic information, which can effectively improve AR performance. Experiments on Accented English Speech Recognition Challenge (AESRC) dataset show that our method achieves 77.42% accuracy on Test set, obtaining a 6.94% relative improvement over a competitive system in the challenge.
WenetSpeech: A 10000+ Hours Multi-domain Mandarin Corpus for Speech Recognition
Oct 18, 2021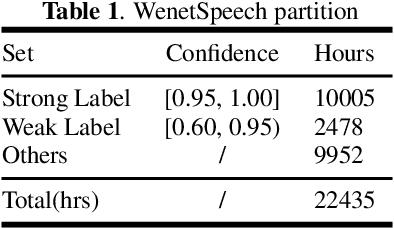

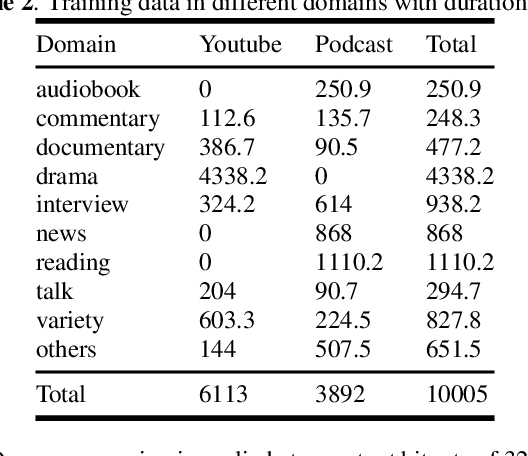
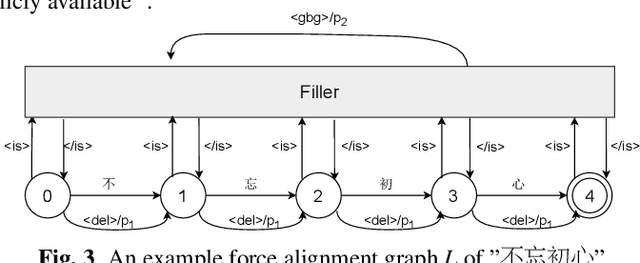
In this paper, we present WenetSpeech, a multi-domain Mandarin corpus consisting of 10000+ hours high-quality labeled speech, 2400+ hours weakly labeled speech, and about 10000 hours unlabeled speech, with 22400+ hours in total. We collect the data from YouTube and Podcast, which covers a variety of speaking styles, scenarios, domains, topics, and noisy conditions. An optical character recognition (OCR) based method is introduced to generate the audio/text segmentation candidates for the YouTube data on its corresponding video captions, while a high-quality ASR transcription system is used to generate audio/text pair candidates for the Podcast data. Then we propose a novel end-to-end label error detection approach to further validate and filter the candidates. We also provide three manually labelled high-quality test sets along with WenetSpeech for evaluation -- Dev for cross-validation purpose in training, Test_Net, collected from Internet for matched test, and Test\_Meeting, recorded from real meetings for more challenging mismatched test. Baseline systems trained with WenetSpeech are provided for three popular speech recognition toolkits, namely Kaldi, ESPnet, and WeNet, and recognition results on the three test sets are also provided as benchmarks. To the best of our knowledge, WenetSpeech is the current largest open-sourced Mandarin speech corpus with transcriptions, which benefits research on production-level speech recognition.
Auto-KWS 2021 Challenge: Task, Datasets, and Baselines
Mar 31, 2021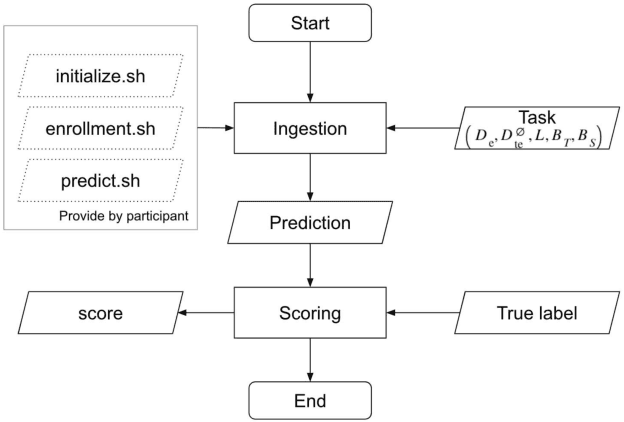


Auto-KWS 2021 challenge calls for automated machine learning (AutoML) solutions to automate the process of applying machine learning to a customized keyword spotting task. Compared with other keyword spotting tasks, Auto-KWS challenge has the following three characteristics: 1) The challenge focuses on the problem of customized keyword spotting, where the target device can only be awakened by an enrolled speaker with his specified keyword. The speaker can use any language and accent to define his keyword. 2) All dataset of the challenge is recorded in realistic environment. It is to simulate different user scenarios. 3) Auto-KWS is a "code competition", where participants need to submit AutoML solutions, then the platform automatically runs the enrollment and prediction steps with the submitted code.This challenge aims at promoting the development of a more personalized and flexible keyword spotting system. Two baseline systems are provided to all participants as references.
The NPU System for the 2020 Personalized Voice Trigger Challenge
Feb 26, 2021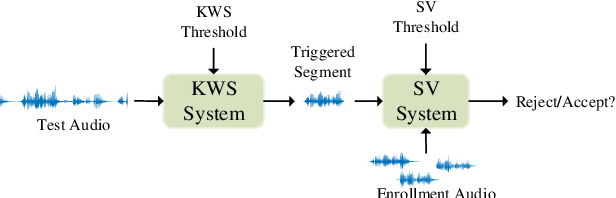
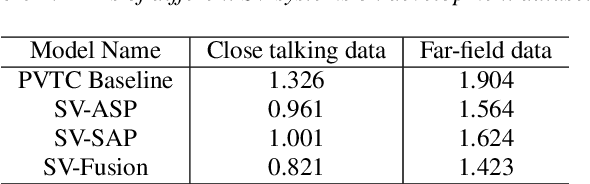
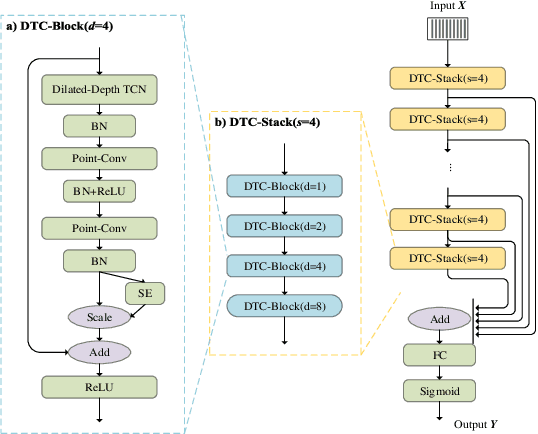

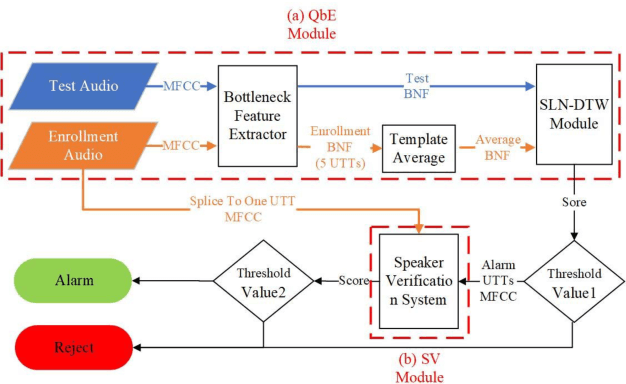
This paper describes the system developed by the NPU team for the 2020 personalized voice trigger challenge. Our submitted system consists of two independently trained subsystems: a small footprint keyword spotting (KWS) system and a speaker verification (SV) system. For the KWS system, a multi-scale dilated temporal convolutional (MDTC) network is proposed to detect wake-up word (WuW). For SV system, Write something here. The KWS predicts posterior probabilities of whether an audio utterance contains WuW and estimates the location of WuW at the same time. When the posterior probability ofWuW reaches a predefined threshold, the identity information of triggered segment is determined by the SV system. On evaluation dataset, our submitted system obtains detection costs of 0.081and 0.091 in close talking and far-field tasks, respectively.