 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistic-Acoustic Similarity Based Accent Shift for Accent Recognition
Paper and Code
Apr 07, 2022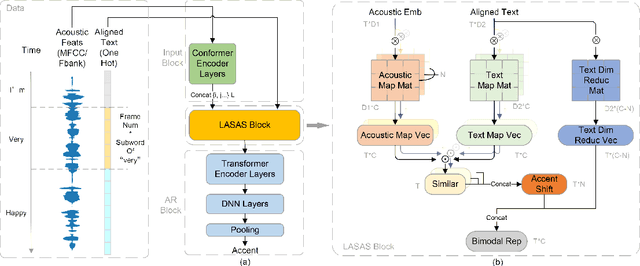
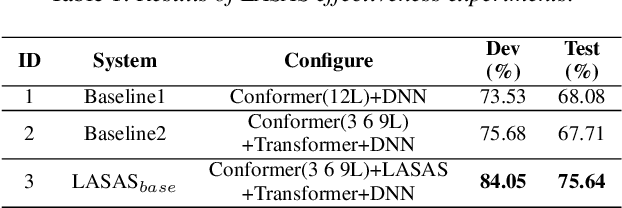
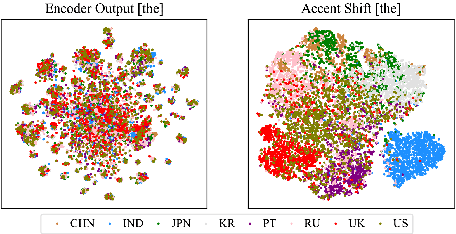
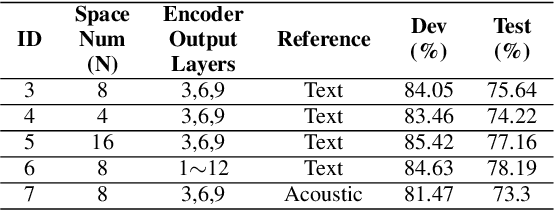
General accent recognition (AR) models tend to directly extract low-level information from spectrums, which always significantly overfit on speakers or channels. Considering accent can be regarded as a series of shifts relative to native pronunciation, distinguishing accents will be an easier task with accent shift as input. But due to the lack of native utterance as an anchor, estimating the accent shift is difficult. In this paper, we propose linguistic-acoustic similarity based accent shift (LASAS) for AR tasks. For an accent speech utterance, after mapping the corresponding text vector to multiple accent-associated spaces as anchors, its accent shift could be estimated by the similarities between the acoustic embedding and those anchors. Then, we concatenate the accent shift with a dimension-reduced text vector to obtain a linguistic-acoustic bimodal representation. Compared with pure acoustic embedding, the bimodal representation is richer and more clear by taking full advantage of both linguistic and acoustic information, which can effectively improve AR performance. Experiments on Accented English Speech Recognition Challenge (AESRC) dataset show that our method achieves 77.42% accuracy on Test set, obtaining a 6.94% relative improvement over a competitive system in the challenge.