 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling and Interacting Multi-Task Learning Network for Joint Speech and Accent Recognition
Paper and Code
Nov 17, 2023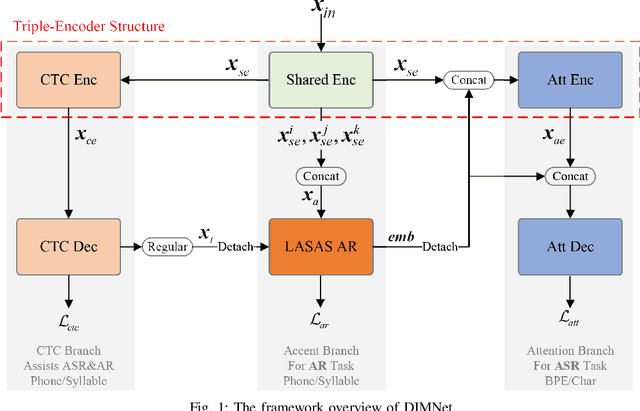
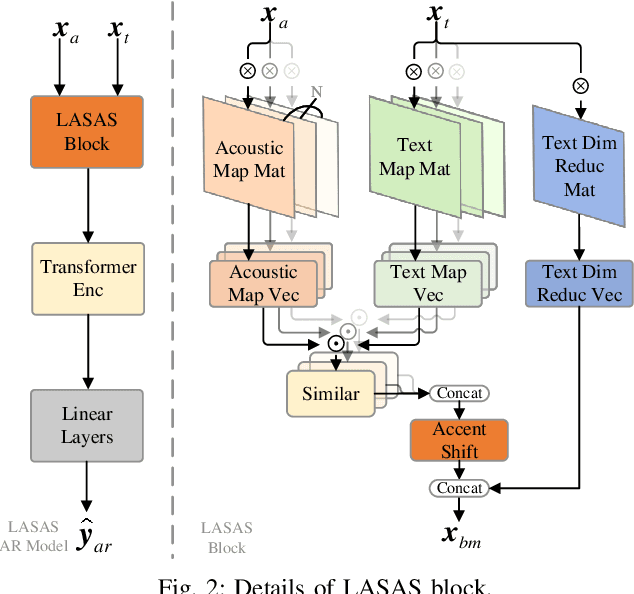
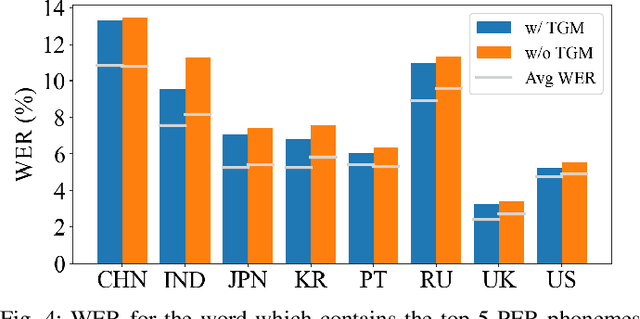

Accents, as variations from standard pronunciation, pose significant challenges for speech recognition systems. Although joint automatic speech recognition (ASR) and accent recognition (AR) training has been proven effective in handling multi-accent scenarios, current multi-task ASR-AR approaches overlook the granularity differences between tasks. Fine-grained units capture pronunciation-related accent characteristics, while coarse-grained units are better for learning linguistic information. Moreover, an explicit interaction of two tasks can also provide complementary information and improve the performance of each other, but it is rarely used by existing approaches. In this paper, we propose a novel Decoupling and Interacting Multi-task Network (DIMNet) for joint speech and accent recognition, which is comprised of a connectionist temporal classification (CTC) branch, an AR branch, an ASR branch, and a bottom feature encoder. Specifically, AR and ASR are first decoupled by separated branches and two-granular modeling units to learn task-specific representations. The AR branch is from our previously proposed linguistic-acoustic bimodal AR model and the ASR branch is an encoder-decoder based Conformer model. Then, for the task interaction, the CTC branch provides aligned text for the AR task, while accent embeddings extracted from our AR model are incorporated into the ASR branch's encoder and decoder. Finally, during ASR inference, a cross-granular rescoring method is introduced to fuse the complementary information from the CTC and attention decoder after the decoupling. Our experiments on English and Chinese datasets demonstrate the effectiveness of the proposed model, which achieves 21.45%/28.53% AR accuracy relative improvement and 32.33%/14.55% ASR error rate relative reduction over a published standard baseline, respectively.