 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Contextual Biasing for Transducer Based Streaming Speech Recognition
Jun 01, 2023By incorporating additional contextual information, deep biasing methods have emerged as a promising solution for speech recognition of personalized words. However, for real-world voice assistants, always biasing on such personalized words with high prediction scores can significantly degrade the performance of recognizing common words. To address this issue, we propose an adaptive contextual biasing method based on Context-Aware Transformer Transducer (CATT) that utilizes the biased encoder and predictor embeddings to perform streaming prediction of contextual phrase occurrences. Such prediction is then used to dynamically switch the bias list on and off, enabling the model to adapt to both personalized and common scenarios. Experiments on Librispeech and internal voice assistant datasets show that our approach can achieve up to 6.7% and 20.7% relative reduction in WER and CER compared to the baseline respectively, mitigating up to 96.7% and 84.9% of the relative WER and CER increase for common cases. Furthermore, our approach has a minimal performance impact in personalized scenarios while maintaining a streaming inference pipeline with negligible RTF increase.
Contextualized End-to-End Speech Recognition with Contextual Phrase Prediction Network
May 21, 2023



Contextual information plays a crucial role in speech recognition technologies and incorporating it into the end-to-end speech recognition models has drawn immense interest recently. However, previous deep bias methods lacked explicit supervision for bias tasks. In this study, we introduce a contextual phrase prediction network for an attention-based deep bias method. This network predicts context phrases in utterances using contextual embeddings and calculates bias loss to assist in the training of the contextualized model. Our method achieved a significant word error rate (WER) reduction across various end-to-end speech recognition models. Experiments on the LibriSpeech corpus show that our proposed model obtains a 12.1% relative WER improvement over the baseline model, and the WER of the context phrases decreases relatively by 40.5%. Moreover, by applying a context phrase filtering strategy, we also effectively eliminate the WER degradation when using a larger biasing list.
Two Stage Contextual Word Filtering for Context bias in Unified Streaming and Non-streaming Transducer
Jan 17, 2023It is difficult for an end-to-end (E2E) ASR system to recognize words such as named entities appearing infrequently in the training data. A widely used method to mitigate this issue is feeding contextual information into the acoustic model. A contextual word list is necessary, which lists all possible contextual word candidates. Previous works have proven that the size and quality of the list are crucial. A compact and accurate list can boost the performance significantly. In this paper, we propose an efficient approach to obtain a high quality contextual word list for a unified streaming and non-streaming based Conformer-Transducer (C-T) model. Specifically, we make use of the phone-level streaming output to first filter the predefined contextual word list. During the subsequent non-streaming inference, the words in the filtered list are regarded as contextual information fused into non-casual encoder and decoder to generate the final recognition results. Our approach can take advantage of streaming recognition hypothesis, improve the accuracy of the contextual ASR system and speed up the inference process as well. Experiments on two datasets demonstrates over 20% relative character error rate reduction (CERR) comparing to the baseline system. Meanwile, the RTF of our system can be stabilized within 0.15 when the size of the contextual word list grows over 6,000.
CaTT-KWS: A Multi-stage Customized Keyword Spotting Framework based on Cascaded Transducer-Transformer
Jul 04, 2022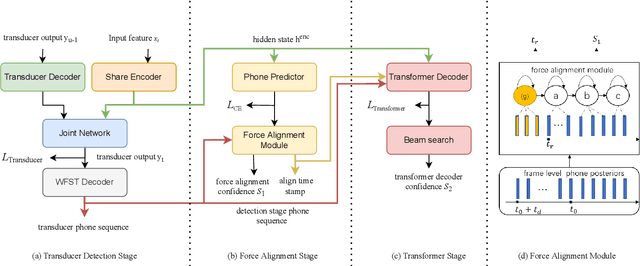
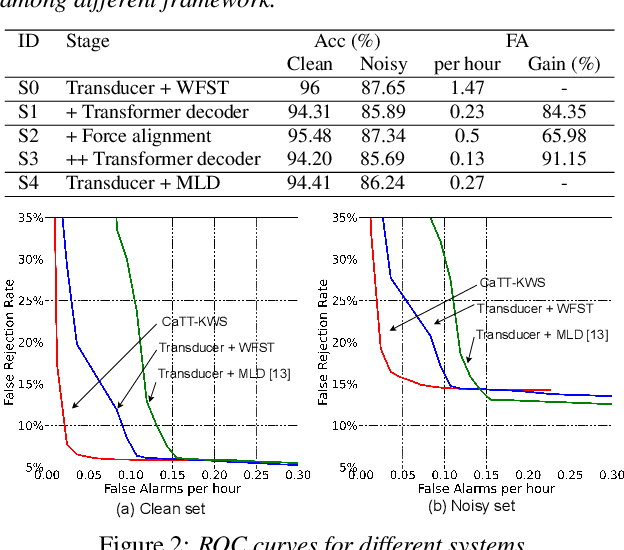
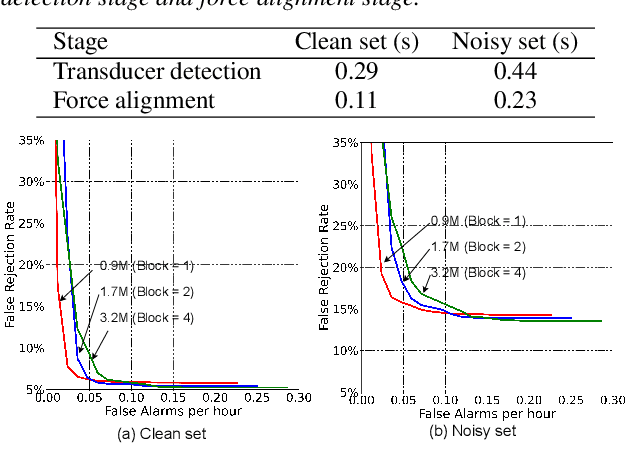
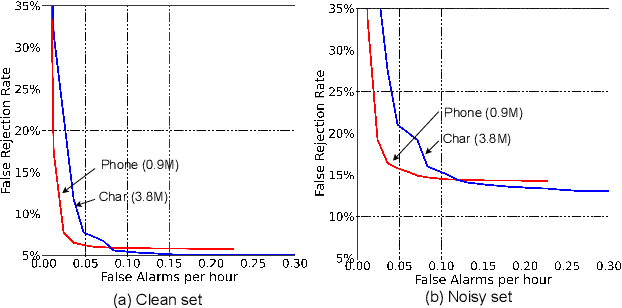
Customized keyword spotting (KWS) has great potential to be deployed on edge devices to achieve hands-free user experience. However, in real applications, false alarm (FA) would be a serious problem for spotting dozens or even hundreds of keywords, which drastically affects user experience. To solve this problem, in this paper, we leverage the recent advances in transducer and transformer based acoustic models and propose a new multi-stage customized KWS framework named Cascaded Transducer-Transformer KWS (CaTT-KWS), which includes a transducer based keyword detector, a frame-level phone predictor based force alignment module and a transformer based decoder. Specifically, the streaming transducer module is used to spot keyword candidates in audio stream. Then force alignment is implemented using the phone posteriors predicted by the phone predictor to finish the first stage keyword verification and refine the time boundaries of keyword. Finally, the transformer decoder further verifies the triggered keyword. Our proposed CaTT-KWS framework reduces FA rate effectively without obviously hurting keyword recognition accuracy. Specifically, we can get impressively 0.13 FA per hour on a challenging dataset, with over 90% relative reduction on FA comparing to the transducer based detection model, while keyword recognition accuracy only drops less than 2%.
Minimizing Sequential Confusion Error in Speech Command Recognition
Jul 04, 2022

Speech command recognition (SCR) has been commonly used on resource constrained devices to achieve hands-free user experience. However, in real applications, confusion among commands with similar pronunciations often happens due to the limited capacity of small models deployed on edge devices, which drastically affects the user experience. In this paper, inspired by the advances of discriminative training in speech recognition, we propose a novel minimize sequential confusion error (MSCE) training criterion particularly for SCR, aiming to alleviate the command confusion problem. Specifically, we aim to improve the ability of discriminating the target command from other commands on the basis of MCE discriminative criteria. We define the likelihood of different commands through connectionist temporal classification (CTC). During training, we propose several strategies to use prior knowledge creating a confusing sequence set for similar-sounding command instead of creating the whole non-target command set, which can better save the training resources and effectively reduce command confusion errors. Specifically, we design and compare three different strategies for confusing set construction. By using our proposed method, we can relatively reduce the False Reject Rate~(FRR) by 33.7% at 0.01 False Alarm Rate~(FAR) and confusion errors by 18.28% on our collected speech command set.
The NPU System for the 2020 Personalized Voice Trigger Challenge
Feb 26, 2021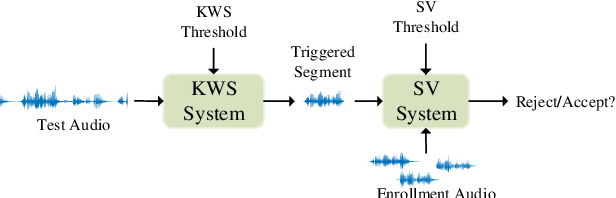
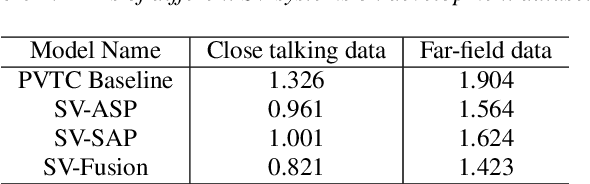
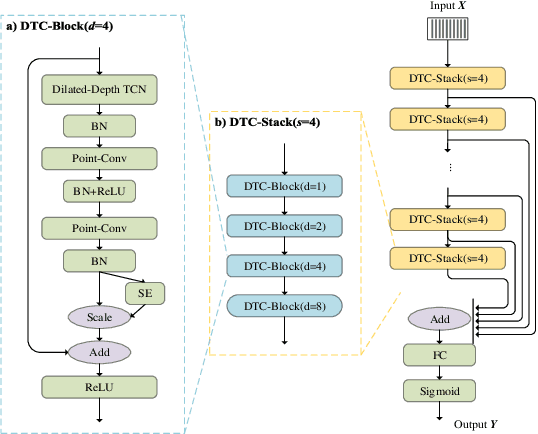

This paper describes the system developed by the NPU team for the 2020 personalized voice trigger challenge. Our submitted system consists of two independently trained subsystems: a small footprint keyword spotting (KWS) system and a speaker verification (SV) system. For the KWS system, a multi-scale dilated temporal convolutional (MDTC) network is proposed to detect wake-up word (WuW). For SV system, Write something here. The KWS predicts posterior probabilities of whether an audio utterance contains WuW and estimates the location of WuW at the same time. When the posterior probability ofWuW reaches a predefined threshold, the identity information of triggered segment is determined by the SV system. On evaluation dataset, our submitted system obtains detection costs of 0.081and 0.091 in close talking and far-field tasks, respectively.