 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaTT-KWS: A Multi-stage Customized Keyword Spotting Framework based on Cascaded Transducer-Transformer
Paper and Code
Jul 04, 2022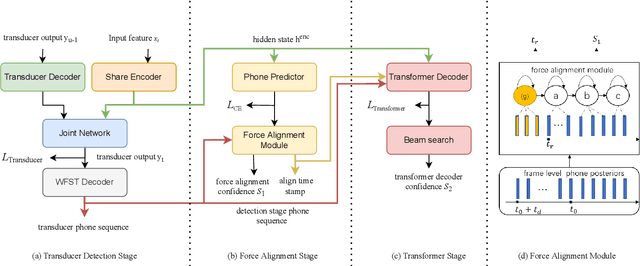
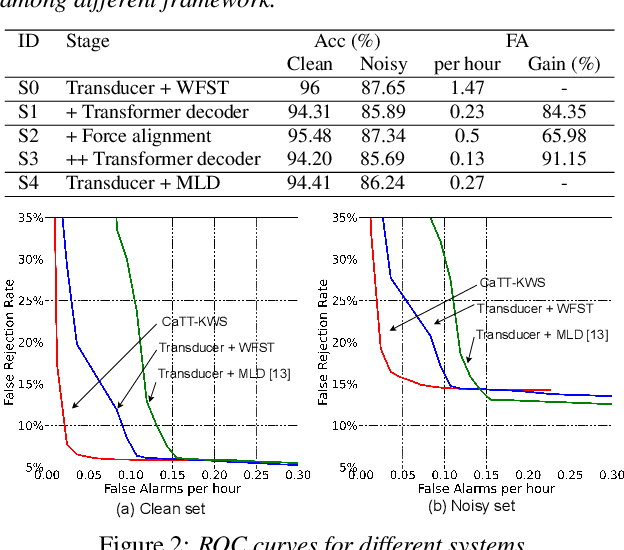
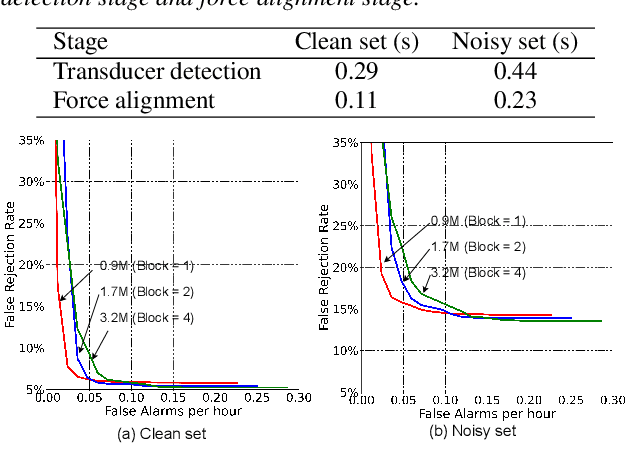
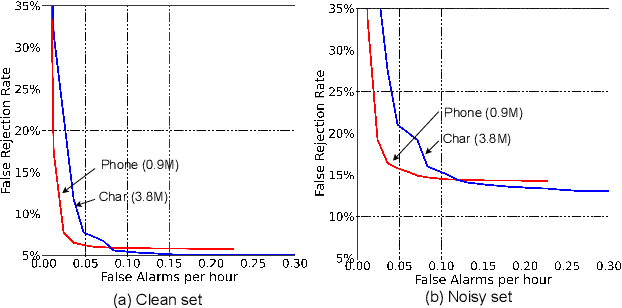
Customized keyword spotting (KWS) has great potential to be deployed on edge devices to achieve hands-free user experience. However, in real applications, false alarm (FA) would be a serious problem for spotting dozens or even hundreds of keywords, which drastically affects user experience. To solve this problem, in this paper, we leverage the recent advances in transducer and transformer based acoustic models and propose a new multi-stage customized KWS framework named Cascaded Transducer-Transformer KWS (CaTT-KWS), which includes a transducer based keyword detector, a frame-level phone predictor based force alignment module and a transformer based decoder. Specifically, the streaming transducer module is used to spot keyword candidates in audio stream. Then force alignment is implemented using the phone posteriors predicted by the phone predictor to finish the first stage keyword verification and refine the time boundaries of keyword. Finally, the transformer decoder further verifies the triggered keyword. Our proposed CaTT-KWS framework reduces FA rate effectively without obviously hurting keyword recognition accuracy. Specifically, we can get impressively 0.13 FA per hour on a challenging dataset, with over 90% relative reduction on FA comparing to the transducer based detection model, while keyword recognition accuracy only drops less than 2%.