 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Preoperative CT to Postmastoidectomy Mesh Construction:1Mastoidectomy Shape Prediction for Cochlear Implant Surgery
Jan 07, 2026Cochlear Implant (CI) surgery treats severe hearing loss by inserting an electrode array into the cochlea to stimulate the auditory nerve. An important step in this procedure is mastoidectomy, which removes part of the mastoid region of the temporal bone to provide surgical access. Accurate mastoidectomy shape prediction from preoperative imaging improves pre-surgical planning, reduces risks, and enhances surgical outcomes. Despite its importance, there are limited deep-learning-based studies regarding this topic due to the challenges of acquiring ground-truth labels. We address this gap by investigating self-supervised and weakly-supervised learning models to predict the mastoidectomy region without human annotations. We propose a hybrid self-supervised and weakly-supervised learning framework to predict the mastoidectomy region directly from preoperative CT scans, where the mastoid remains intact. Our hybrid method achieves a mean Dice score of 0.72 when predicting the complex and boundary-less mastoidectomy shape, surpassing state-of-the-art approaches and demonstrating strong performance. The method provides groundwork for constructing 3D postmastoidectomy surfaces directly from the corresponding preoperative CT scans. To our knowledge, this is the first work that integrating self-supervised and weakly-supervised learning for mastoidectomy shape prediction, offering a robust and efficient solution for CI surgical planning while leveraging 3D T-distribution loss in weakly-supervised medical imaging.
$ΔL$ Normalization: Rethink Loss Aggregation in RLVR
Sep 09, 2025We propose $\Delta L$ Normalization, a simple yet effective loss aggregation method tailored to the characteristic of dynamic generation lengths in Reinforcement Learning with Verifiable Rewards (RLVR). Recently, RLVR has demonstrated strong potential in improving the reasoning capabilities of large language models (LLMs), but a major challenge lies in the large variability of response lengths during training, which leads to high gradient variance and unstable optimization. Although previous methods such as GRPO, DAPO, and Dr. GRPO introduce different loss normalization terms to address this issue, they either produce biased estimates or still suffer from high gradient variance. By analyzing the effect of varying lengths on policy loss both theoretically and empirically, we reformulate the problem as finding a minimum-variance unbiased estimator. Our proposed $\Delta L$ Normalization not only provides an unbiased estimate of the true policy loss but also minimizes gradient variance in theory. Extensive experiments show that it consistently achieves superior results across different model sizes, maximum lengths, and tasks. Our code will be made public at https://github.com/zerolllin/Delta-L-Normalization.
Designing Gaze Analytics for ELA Instruction: A User-Centered Dashboard with Conversational AI Support
Sep 03, 2025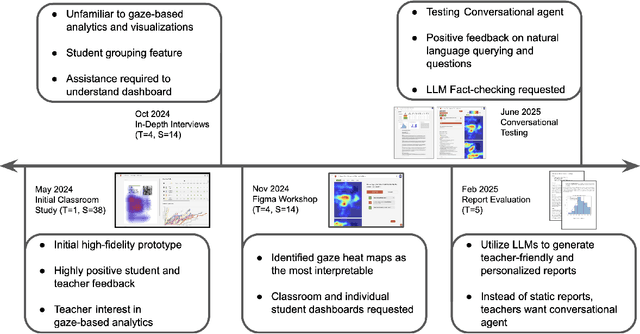
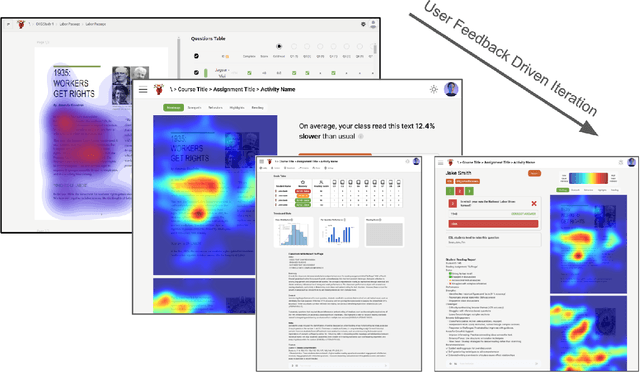
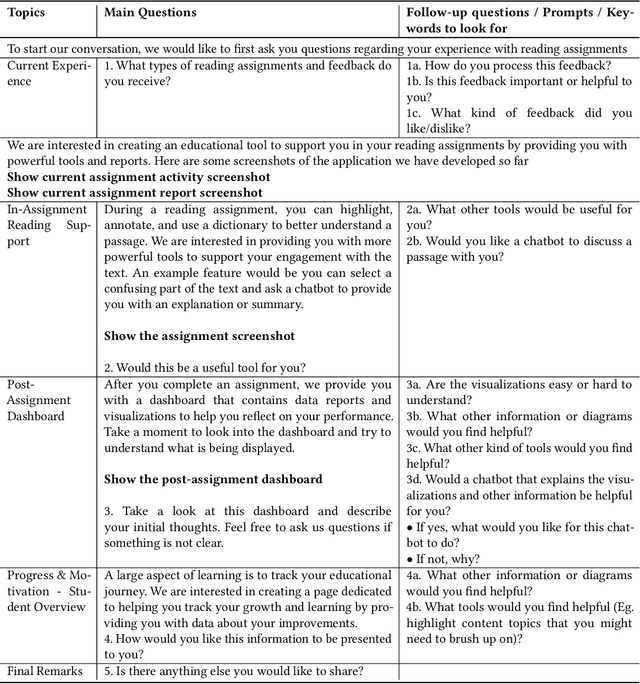
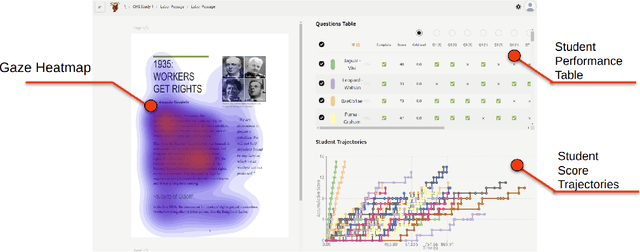
Eye-tracking offers rich insights into student cognition and engagement, but remains underutilized in classroom-facing educational technology due to challenges in data interpretation and accessibility. In this paper, we present the iterative design and evaluation of a gaze-based learning analytics dashboard for English Language Arts (ELA), developed through five studies involving teachers and students. Guided by user-centered design and data storytelling principles, we explored how gaze data can support reflection, formative assessment, and instructional decision-making. Our findings demonstrate that gaze analytics can be approachable and pedagogically valuable when supported by familiar visualizations, layered explanations, and narrative scaffolds. We further show how a conversational agent, powered by a large language model (LLM), can lower cognitive barriers to interpreting gaze data by enabling natural language interactions with multimodal learning analytics. We conclude with design implications for future EdTech systems that aim to integrate novel data modalities in classroom contexts.
WEBEYETRACK: Scalable Eye-Tracking for the Browser via On-Device Few-Shot Personalization
Aug 27, 2025With advancements in AI, new gaze estimation methods are exceeding state-of-the-art (SOTA) benchmarks, but their real-world application reveals a gap with commercial eye-tracking solutions. Factors like model size, inference time, and privacy often go unaddressed. Meanwhile, webcam-based eye-tracking methods lack sufficient accuracy, in particular due to head movement. To tackle these issues, we introduce We bEyeTrack, a framework that integrates lightweight SOTA gaze estimation models directly in the browser. It incorporates model-based head pose estimation and on-device few-shot learning with as few as nine calibration samples (k < 9). WebEyeTrack adapts to new users, achieving SOTA performance with an error margin of 2.32 cm on GazeCapture and real-time inference speeds of 2.4 milliseconds on an iPhone 14. Our open-source code is available at https://github.com/RedForestAi/WebEyeTrack.
Monocular Marker-free Patient-to-Image Intraoperative Registration for Cochlear Implant Surgery
May 23, 2025This paper presents a novel method for monocular patient-to-image intraoperative registration, specifically designed to operate without any external hardware tracking equipment or fiducial point markers. Leveraging a synthetic microscopy surgical scene dataset with a wide range of transformations, our approach directly maps preoperative CT scans to 2D intraoperative surgical frames through a lightweight neural network for real-time cochlear implant surgery guidance via a zero-shot learning approach. Unlike traditional methods, our framework seamlessly integrates with monocular surgical microscopes, making it highly practical for clinical use without additional hardware dependencies and requirements. Our method estimates camera poses, which include a rotation matrix and a translation vector, by learning from the synthetic dataset, enabling accurate and efficient intraoperative registration. The proposed framework was evaluated on nine clinical cases using a patient-specific and cross-patient validation strategy. Our results suggest that our approach achieves clinically relevant accuracy in predicting 6D camera poses for registering 3D preoperative CT scans to 2D surgical scenes with an angular error within 10 degrees in most cases, while also addressing limitations of traditional methods, such as reliance on external tracking systems or fiducial markers.
Weakly-supervised Mamba-Based Mastoidectomy Shape Prediction for Cochlear Implant Surgery Using 3D T-Distribution Loss
May 23, 2025Cochlear implant surgery is a treatment for individuals with severe hearing loss. It involves inserting an array of electrodes inside the cochlea to electrically stimulate the auditory nerve and restore hearing sensation. A crucial step in this procedure is mastoidectomy, a surgical intervention that removes part of the mastoid region of the temporal bone, providing a critical pathway to the cochlea for electrode placement. Accurate prediction of the mastoidectomy region from preoperative imaging assists presurgical planning, reduces surgical risks, and improves surgical outcomes. In previous work, a self-supervised network was introduced to predict the mastoidectomy region using only preoperative CT scans. While promising, the method suffered from suboptimal robustness, limiting its practical application. To address this limitation, we propose a novel weakly-supervised Mamba-based framework to predict accurate mastoidectomy regions directly from preoperative CT scans. Our approach utilizes a 3D T-Distribution loss function inspired by the Student-t distribution, which effectively handles the complex geometric variability inherent in mastoidectomy shapes. Weak supervision is achieved using the segmentation results from the prior self-supervised network to eliminate the need for manual data cleaning or labeling throughout the training process. The proposed method is extensively evaluated against state-of-the-art approaches, demonstrating superior performance in predicting accurate and clinically relevant mastoidectomy regions. Our findings highlight the robustness and efficiency of the weakly-supervised learning framework with the proposed novel 3D T-Distribution loss.
Vision6D: 3D-to-2D Interactive Visualization and Annotation Tool for 6D Pose Estimation
Apr 21, 2025Accurate 6D pose estimation has gained more attention over the years for robotics-assisted tasks that require precise interaction with physical objects. This paper presents an interactive 3D-to-2D visualization and annotation tool to support the 6D pose estimation research community. To the best of our knowledge, the proposed work is the first tool that allows users to visualize and manipulate 3D objects interactively on a 2D real-world scene, along with a comprehensive user study. This system supports robust 6D camera pose annotation by providing both visual cues and spatial relationships to determine object position and orientation in various environments. The annotation feature in Vision6D is particularly helpful in scenarios where the transformation matrix between the camera and world objects is unknown, as it enables accurate annotation of these objects' poses using only the camera intrinsic matrix. This capability serves as a foundational step in developing and training advanced pose estimation models across various domains. We evaluate Vision6D's effectiveness by utilizing widely-used open-source pose estimation datasets Linemod and HANDAL through comparisons between the default ground-truth camera poses with manual annotations. A user study was performed to show that Vision6D generates accurate pose annotations via visual cues in an intuitive 3D user interface. This approach aims to bridge the gap between 2D scene projections and 3D scenes, offering an effective way for researchers and developers to solve 6D pose annotation related problems. The software is open-source and publicly available at https://github.com/InteractiveGL/vision6D.
LLMs as Educational Analysts: Transforming Multimodal Data Traces into Actionable Reading Assessment Reports
Mar 03, 2025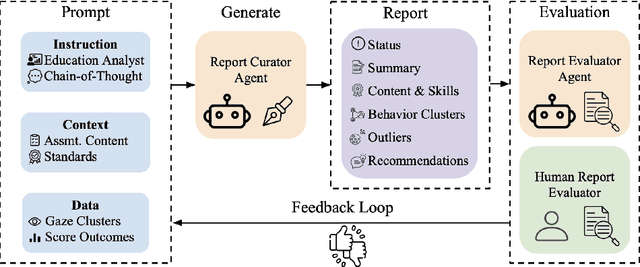
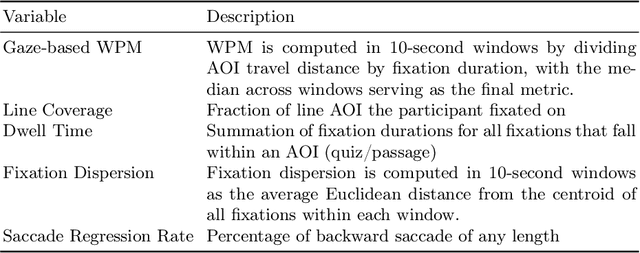

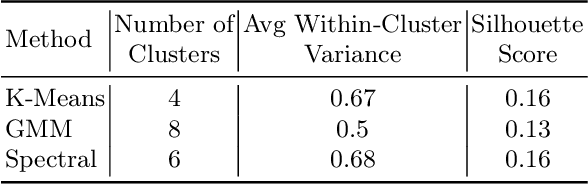
Reading assessments are essential for enhancing students' comprehension, yet many EdTech applications focus mainly on outcome-based metrics, providing limited insights into student behavior and cognition. This study investigates the use of multimodal data sources -- including eye-tracking data, learning outcomes, assessment content, and teaching standards -- to derive meaningful reading insights. We employ unsupervised learning techniques to identify distinct reading behavior patterns, and then a large language model (LLM) synthesizes the derived information into actionable reports for educators, streamlining the interpretation process. LLM experts and human educators evaluate these reports for clarity, accuracy, relevance, and pedagogical usefulness. Our findings indicate that LLMs can effectively function as educational analysts, turning diverse data into teacher-friendly insights that are well-received by educators. While promising for automating insight generation, human oversight remains crucial to ensure reliability and fairness. This research advances human-centered AI in education, connecting data-driven analytics with practical classroom applications.
SSDD-GAN: Single-Step Denoising Diffusion GAN for Cochlear Implant Surgical Scene Completion
Feb 08, 2025



Recent deep learning-based image completion methods, including both inpainting and outpainting, have demonstrated promising results in restoring corrupted images by effectively filling various missing regions. Among these, Generative Adversarial Networks (GANs) and Denoising Diffusion Probabilistic Models (DDPMs) have been employed as key generative image completion approaches, excelling in the field of generating high-quality restorations with reduced artifacts and improved fine details. In previous work, we developed a method aimed at synthesizing views from novel microscope positions for mastoidectomy surgeries; however, that approach did not have the ability to restore the surrounding surgical scene environment. In this paper, we propose an efficient method to complete the surgical scene of the synthetic postmastoidectomy dataset. Our approach leverages self-supervised learning on real surgical datasets to train a Single-Step Denoising Diffusion-GAN (SSDD-GAN), combining the advantages of diffusion models with the adversarial optimization of GANs for improved Structural Similarity results of 6%. The trained model is then directly applied to the synthetic postmastoidectomy dataset using a zero-shot approach, enabling the generation of realistic and complete surgical scenes without the need for explicit ground-truth labels from the synthetic postmastoidectomy dataset. This method addresses key limitations in previous work, offering a novel pathway for full surgical microscopy scene completion and enhancing the usability of the synthetic postmastoidectomy dataset in surgical preoperative planning and intraoperative navigation.
Beyond Instructed Tasks: Recognizing In-the-Wild Reading Behaviors in the Classroom Using Eye Tracking
Jan 30, 2025



Understanding reader behaviors such as skimming, deep reading, and scanning is essential for improving educational instruction. While prior eye-tracking studies have trained models to recognize reading behaviors, they often rely on instructed reading tasks, which can alter natural behaviors and limit the applicability of these findings to in-the-wild settings. Additionally, there is a lack of clear definitions for reading behavior archetypes in the literature. We conducted a classroom study to address these issues by collecting instructed and in-the-wild reading data. We developed a mixed-method framework, including a human-driven theoretical model, statistical analyses, and an AI classifier, to differentiate reading behaviors based on their velocity, density, and sequentiality. Our lightweight 2D CNN achieved an F1 score of 0.8 for behavior recognition, providing a robust approach for understanding in-the-wild reading. This work advances our ability to provide detailed behavioral insights to educators, supporting more targeted and effective assessment and instruction.