 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAGLE: Behavior-Enforced Agent for Grounded Learner Emulation
Feb 06, 2026Simulating student learning behaviors in open-ended problem-solving environments holds potential for education research, from training adaptive tutoring systems to stress-testing pedagogical interventions. However, collecting authentic data is challenging due to privacy concerns and the high cost of longitudinal studies. While Large Language Models (LLMs) offer a promising path to student simulation, they suffer from competency bias, optimizing for efficient correctness rather than the erratic, iterative struggle characteristic of novice learners. We present BEAGLE, a neuro-symbolic framework that addresses this bias by incorporating Self-Regulated Learning (SRL) theory into a novel architecture. BEAGLE integrates three key technical innovations: (1) a semi-Markov model that governs the timing and transitions of cognitive behaviors and metacognitive behaviors; (2) Bayesian Knowledge Tracing with explicit flaw injection to enforce realistic knowledge gaps and "unknown unknowns"; and (3) a decoupled agent design that separates high-level strategy use from code generation actions to prevent the model from silently correcting its own intentional errors. In evaluations on Python programming tasks, BEAGLE significantly outperforms state-of-the-art baselines in reproducing authentic trajectories. In a human Turing test, users were unable to distinguish synthetic traces from real student data, achieving an accuracy indistinguishable from random guessing (52.8%).
Using Large Language Models to Detect Socially Shared Regulation of Collaborative Learning
Jan 08, 2026The field of learning analytics has made notable strides in automating the detection of complex learning processes in multimodal data. However, most advancements have focused on individualized problem-solving instead of collaborative, open-ended problem-solving, which may offer both affordances (richer data) and challenges (low cohesion) to behavioral prediction. Here, we extend predictive models to automatically detect socially shared regulation of learning (SSRL) behaviors in collaborative computational modeling environments using embedding-based approaches. We leverage large language models (LLMs) as summarization tools to generate task-aware representations of student dialogue aligned with system logs. These summaries, combined with text-only embeddings, context-enriched embeddings, and log-derived features, were used to train predictive models. Results show that text-only embeddings often achieve stronger performance in detecting SSRL behaviors related to enactment or group dynamics (e.g., off-task behavior or requesting assistance). In contrast, contextual and multimodal features provide complementary benefits for constructs such as planning and reflection. Overall, our findings highlight the promise of embedding-based models for extending learning analytics by enabling scalable detection of SSRL behaviors, ultimately supporting real-time feedback and adaptive scaffolding in collaborative learning environments that teachers value.
Video-Based Performance Evaluation for ECR Drills in Synthetic Training Environments
Dec 29, 2025Effective urban warfare training requires situational awareness and muscle memory, developed through repeated practice in realistic yet controlled environments. A key drill, Enter and Clear the Room (ECR), demands threat assessment, coordination, and securing confined spaces. The military uses Synthetic Training Environments that offer scalable, controlled settings for repeated exercises. However, automatic performance assessment remains challenging, particularly when aiming for objective evaluation of cognitive, psychomotor, and teamwork skills. Traditional methods often rely on costly, intrusive sensors or subjective human observation, limiting scalability and accuracy. This paper introduces a video-based assessment pipeline that derives performance analytics from training videos without requiring additional hardware. By utilizing computer vision models, the system extracts 2D skeletons, gaze vectors, and movement trajectories. From these data, we develop task-specific metrics that measure psychomotor fluency, situational awareness, and team coordination. These metrics feed into an extended Cognitive Task Analysis (CTA) hierarchy, which employs a weighted combination to generate overall performance scores for teamwork and cognition. We demonstrate the approach with a case study of real-world ECR drills, providing actionable, domain specific metrics that capture individual and team performance. We also discuss how these insights can support After Action Reviews with interactive dashboards within Gamemaster and the Generalized Intelligent Framework for Tutoring (GIFT), providing intuitive and understandable feedback. We conclude by addressing limitations, including tracking difficulties, ground-truth validation, and the broader applicability of our approach. Future work includes expanding analysis to 3D video data and leveraging video analysis to enable scalable evaluation within STEs.
Designing Gaze Analytics for ELA Instruction: A User-Centered Dashboard with Conversational AI Support
Sep 03, 2025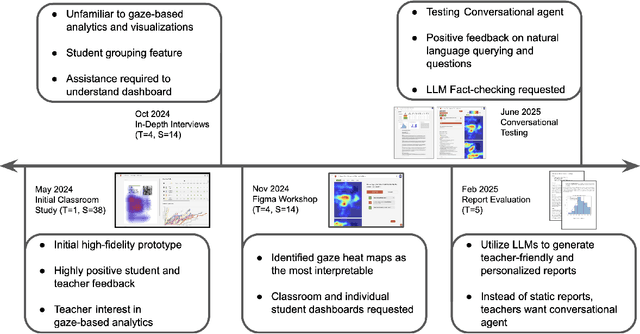
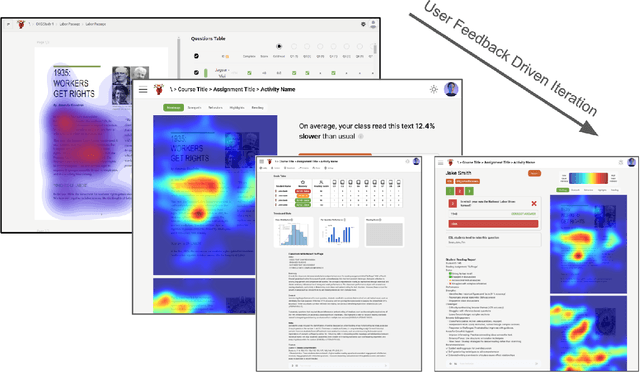
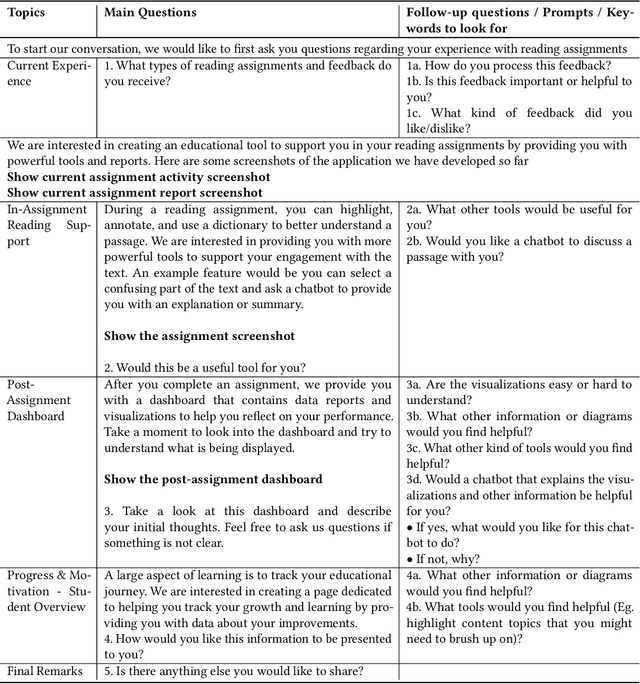
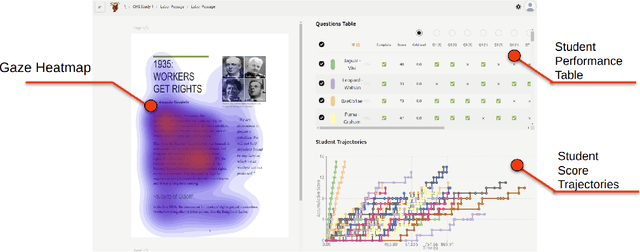
Eye-tracking offers rich insights into student cognition and engagement, but remains underutilized in classroom-facing educational technology due to challenges in data interpretation and accessibility. In this paper, we present the iterative design and evaluation of a gaze-based learning analytics dashboard for English Language Arts (ELA), developed through five studies involving teachers and students. Guided by user-centered design and data storytelling principles, we explored how gaze data can support reflection, formative assessment, and instructional decision-making. Our findings demonstrate that gaze analytics can be approachable and pedagogically valuable when supported by familiar visualizations, layered explanations, and narrative scaffolds. We further show how a conversational agent, powered by a large language model (LLM), can lower cognitive barriers to interpreting gaze data by enabling natural language interactions with multimodal learning analytics. We conclude with design implications for future EdTech systems that aim to integrate novel data modalities in classroom contexts.
WEBEYETRACK: Scalable Eye-Tracking for the Browser via On-Device Few-Shot Personalization
Aug 27, 2025With advancements in AI, new gaze estimation methods are exceeding state-of-the-art (SOTA) benchmarks, but their real-world application reveals a gap with commercial eye-tracking solutions. Factors like model size, inference time, and privacy often go unaddressed. Meanwhile, webcam-based eye-tracking methods lack sufficient accuracy, in particular due to head movement. To tackle these issues, we introduce We bEyeTrack, a framework that integrates lightweight SOTA gaze estimation models directly in the browser. It incorporates model-based head pose estimation and on-device few-shot learning with as few as nine calibration samples (k < 9). WebEyeTrack adapts to new users, achieving SOTA performance with an error margin of 2.32 cm on GazeCapture and real-time inference speeds of 2.4 milliseconds on an iPhone 14. Our open-source code is available at https://github.com/RedForestAi/WebEyeTrack.
Personalizing Student-Agent Interactions Using Log-Contextualized Retrieval Augmented Generation (RAG)
May 22, 2025Collaborative dialogue offers rich insights into students' learning and critical thinking. This is essential for adapting pedagogical agents to students' learning and problem-solving skills in STEM+C settings. While large language models (LLMs) facilitate dynamic pedagogical interactions, potential hallucinations can undermine confidence, trust, and instructional value. Retrieval-augmented generation (RAG) grounds LLM outputs in curated knowledge, but its effectiveness depends on clear semantic links between user input and a knowledge base, which are often weak in student dialogue. We propose log-contextualized RAG (LC-RAG), which enhances RAG retrieval by incorporating environment logs to contextualize collaborative discourse. Our findings show that LC-RAG improves retrieval over a discourse-only baseline and allows our collaborative peer agent, Copa, to deliver relevant, personalized guidance that supports students' critical thinking and epistemic decision-making in a collaborative computational modeling environment, XYZ.
CoTAL: Human-in-the-Loop Prompt Engineering, Chain-of-Thought Reasoning, and Active Learning for Generalizable Formative Assessment Scoring
Apr 03, 2025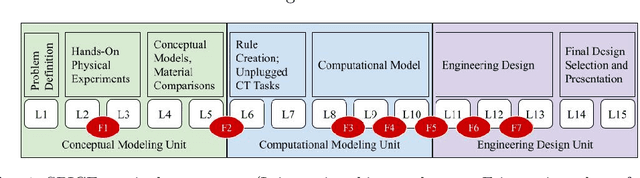

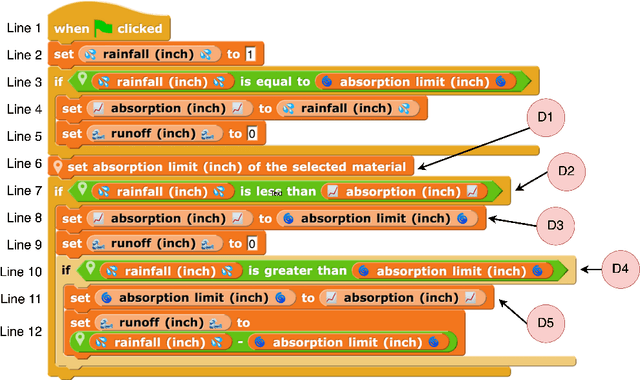

Large language models (LLMs) have created new opportunities to assist teachers and support student learning. Methods such as chain-of-thought (CoT) prompting enable LLMs to grade formative assessments in science, providing scores and relevant feedback to students. However, the extent to which these methods generalize across curricula in multiple domains (such as science, computing, and engineering) remains largely untested. In this paper, we introduce Chain-of-Thought Prompting + Active Learning (CoTAL), an LLM-based approach to formative assessment scoring that (1) leverages Evidence-Centered Design (ECD) principles to develop curriculum-aligned formative assessments and rubrics, (2) applies human-in-the-loop prompt engineering to automate response scoring, and (3) incorporates teacher and student feedback to iteratively refine assessment questions, grading rubrics, and LLM prompts for automated grading. Our findings demonstrate that CoTAL improves GPT-4's scoring performance, achieving gains of up to 24.5% over a non-prompt-engineered baseline. Both teachers and students view CoTAL as effective in scoring and explaining student responses, each providing valuable refinements to enhance grading accuracy and explanation quality.
LLMs as Educational Analysts: Transforming Multimodal Data Traces into Actionable Reading Assessment Reports
Mar 03, 2025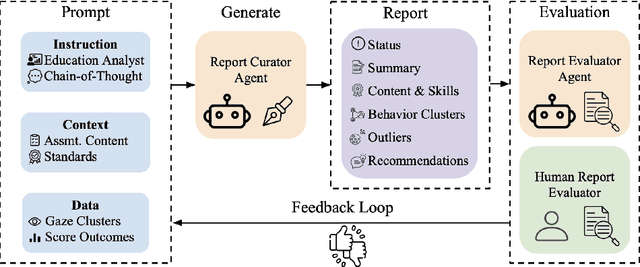
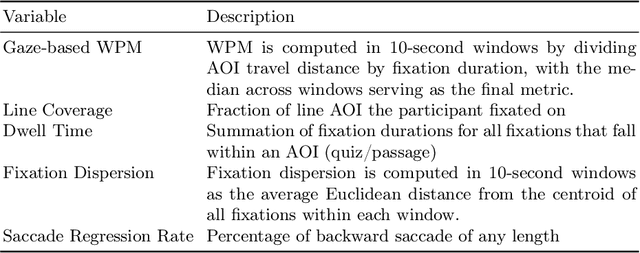

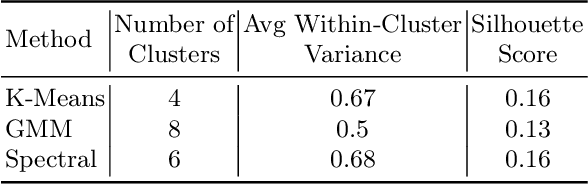
Reading assessments are essential for enhancing students' comprehension, yet many EdTech applications focus mainly on outcome-based metrics, providing limited insights into student behavior and cognition. This study investigates the use of multimodal data sources -- including eye-tracking data, learning outcomes, assessment content, and teaching standards -- to derive meaningful reading insights. We employ unsupervised learning techniques to identify distinct reading behavior patterns, and then a large language model (LLM) synthesizes the derived information into actionable reports for educators, streamlining the interpretation process. LLM experts and human educators evaluate these reports for clarity, accuracy, relevance, and pedagogical usefulness. Our findings indicate that LLMs can effectively function as educational analysts, turning diverse data into teacher-friendly insights that are well-received by educators. While promising for automating insight generation, human oversight remains crucial to ensure reliability and fairness. This research advances human-centered AI in education, connecting data-driven analytics with practical classroom applications.
On the Design of Safe Continual RL Methods for Control of Nonlinear Systems
Feb 21, 2025



Reinforcement learning (RL) algorithms have been successfully applied to control tasks associated with unmanned aerial vehicles and robotics. In recent years, safe RL has been proposed to allow the safe execution of RL algorithms in industrial and mission-critical systems that operate in closed loops. However, if the system operating conditions change, such as when an unknown fault occurs in the system, typical safe RL algorithms are unable to adapt while retaining past knowledge. Continual reinforcement learning algorithms have been proposed to address this issue. However, the impact of continual adaptation on the system's safety is an understudied problem. In this paper, we study the intersection of safe and continual RL. First, we empirically demonstrate that a popular continual RL algorithm, online elastic weight consolidation, is unable to satisfy safety constraints in non-linear systems subject to varying operating conditions. Specifically, we study the MuJoCo HalfCheetah and Ant environments with velocity constraints and sudden joint loss non-stationarity. Then, we show that an agent trained using constrained policy optimization, a safe RL algorithm, experiences catastrophic forgetting in continual learning settings. With this in mind, we explore a simple reward-shaping method to ensure that elastic weight consolidation prioritizes remembering both safety and task performance for safety-constrained, non-linear, and non-stationary dynamical systems.
Beyond Instructed Tasks: Recognizing In-the-Wild Reading Behaviors in the Classroom Using Eye Tracking
Jan 30, 2025



Understanding reader behaviors such as skimming, deep reading, and scanning is essential for improving educational instruction. While prior eye-tracking studies have trained models to recognize reading behaviors, they often rely on instructed reading tasks, which can alter natural behaviors and limit the applicability of these findings to in-the-wild settings. Additionally, there is a lack of clear definitions for reading behavior archetypes in the literature. We conducted a classroom study to address these issues by collecting instructed and in-the-wild reading data. We developed a mixed-method framework, including a human-driven theoretical model, statistical analyses, and an AI classifier, to differentiate reading behaviors based on their velocity, density, and sequentiality. Our lightweight 2D CNN achieved an F1 score of 0.8 for behavior recognition, providing a robust approach for understanding in-the-wild reading. This work advances our ability to provide detailed behavioral insights to educators, supporting more targeted and effective assessment and instruction.