 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAGLE: Behavior-Enforced Agent for Grounded Learner Emulation
Feb 06, 2026Simulating student learning behaviors in open-ended problem-solving environments holds potential for education research, from training adaptive tutoring systems to stress-testing pedagogical interventions. However, collecting authentic data is challenging due to privacy concerns and the high cost of longitudinal studies. While Large Language Models (LLMs) offer a promising path to student simulation, they suffer from competency bias, optimizing for efficient correctness rather than the erratic, iterative struggle characteristic of novice learners. We present BEAGLE, a neuro-symbolic framework that addresses this bias by incorporating Self-Regulated Learning (SRL) theory into a novel architecture. BEAGLE integrates three key technical innovations: (1) a semi-Markov model that governs the timing and transitions of cognitive behaviors and metacognitive behaviors; (2) Bayesian Knowledge Tracing with explicit flaw injection to enforce realistic knowledge gaps and "unknown unknowns"; and (3) a decoupled agent design that separates high-level strategy use from code generation actions to prevent the model from silently correcting its own intentional errors. In evaluations on Python programming tasks, BEAGLE significantly outperforms state-of-the-art baselines in reproducing authentic trajectories. In a human Turing test, users were unable to distinguish synthetic traces from real student data, achieving an accuracy indistinguishable from random guessing (52.8%).
Using Large Language Models to Detect Socially Shared Regulation of Collaborative Learning
Jan 08, 2026The field of learning analytics has made notable strides in automating the detection of complex learning processes in multimodal data. However, most advancements have focused on individualized problem-solving instead of collaborative, open-ended problem-solving, which may offer both affordances (richer data) and challenges (low cohesion) to behavioral prediction. Here, we extend predictive models to automatically detect socially shared regulation of learning (SSRL) behaviors in collaborative computational modeling environments using embedding-based approaches. We leverage large language models (LLMs) as summarization tools to generate task-aware representations of student dialogue aligned with system logs. These summaries, combined with text-only embeddings, context-enriched embeddings, and log-derived features, were used to train predictive models. Results show that text-only embeddings often achieve stronger performance in detecting SSRL behaviors related to enactment or group dynamics (e.g., off-task behavior or requesting assistance). In contrast, contextual and multimodal features provide complementary benefits for constructs such as planning and reflection. Overall, our findings highlight the promise of embedding-based models for extending learning analytics by enabling scalable detection of SSRL behaviors, ultimately supporting real-time feedback and adaptive scaffolding in collaborative learning environments that teachers value.
Personalizing Student-Agent Interactions Using Log-Contextualized Retrieval Augmented Generation (RAG)
May 22, 2025Collaborative dialogue offers rich insights into students' learning and critical thinking. This is essential for adapting pedagogical agents to students' learning and problem-solving skills in STEM+C settings. While large language models (LLMs) facilitate dynamic pedagogical interactions, potential hallucinations can undermine confidence, trust, and instructional value. Retrieval-augmented generation (RAG) grounds LLM outputs in curated knowledge, but its effectiveness depends on clear semantic links between user input and a knowledge base, which are often weak in student dialogue. We propose log-contextualized RAG (LC-RAG), which enhances RAG retrieval by incorporating environment logs to contextualize collaborative discourse. Our findings show that LC-RAG improves retrieval over a discourse-only baseline and allows our collaborative peer agent, Copa, to deliver relevant, personalized guidance that supports students' critical thinking and epistemic decision-making in a collaborative computational modeling environment, XYZ.
CoTAL: Human-in-the-Loop Prompt Engineering, Chain-of-Thought Reasoning, and Active Learning for Generalizable Formative Assessment Scoring
Apr 03, 2025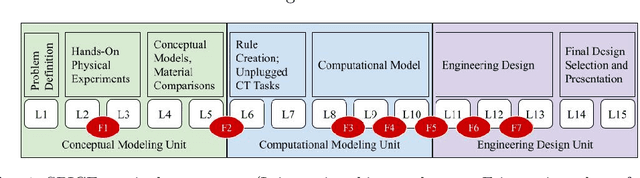

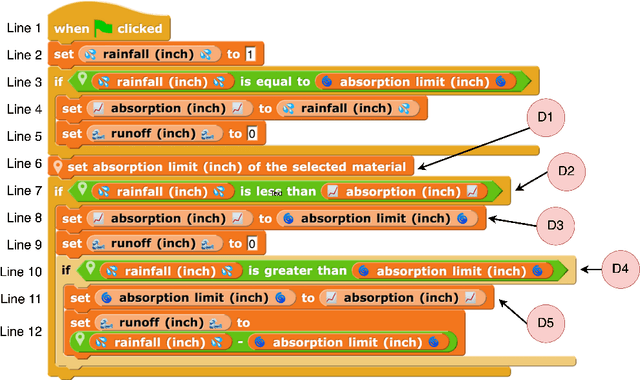

Large language models (LLMs) have created new opportunities to assist teachers and support student learning. Methods such as chain-of-thought (CoT) prompting enable LLMs to grade formative assessments in science, providing scores and relevant feedback to students. However, the extent to which these methods generalize across curricula in multiple domains (such as science, computing, and engineering) remains largely untested. In this paper, we introduce Chain-of-Thought Prompting + Active Learning (CoTAL), an LLM-based approach to formative assessment scoring that (1) leverages Evidence-Centered Design (ECD) principles to develop curriculum-aligned formative assessments and rubrics, (2) applies human-in-the-loop prompt engineering to automate response scoring, and (3) incorporates teacher and student feedback to iteratively refine assessment questions, grading rubrics, and LLM prompts for automated grading. Our findings demonstrate that CoTAL improves GPT-4's scoring performance, achieving gains of up to 24.5% over a non-prompt-engineered baseline. Both teachers and students view CoTAL as effective in scoring and explaining student responses, each providing valuable refinements to enhance grading accuracy and explanation quality.
Multimodal Methods for Analyzing Learning and Training Environments: A Systematic Literature Review
Aug 22, 2024



Recent technological advancements have enhanced our ability to collect and analyze rich multimodal data (e.g., speech, video, and eye gaze) to better inform learning and training experiences. While previous reviews have focused on parts of the multimodal pipeline (e.g., conceptual models and data fusion), a comprehensive literature review on the methods informing multimodal learning and training environments has not been conducted. This literature review provides an in-depth analysis of research methods in these environments, proposing a taxonomy and framework that encapsulates recent methodological advances in this field and characterizes the multimodal domain in terms of five modality groups: Natural Language, Video, Sensors, Human-Centered, and Environment Logs. We introduce a novel data fusion category -- mid fusion -- and a graph-based technique for refining literature reviews, termed citation graph pruning. Our analysis reveals that leveraging multiple modalities offers a more holistic understanding of the behaviors and outcomes of learners and trainees. Even when multimodality does not enhance predictive accuracy, it often uncovers patterns that contextualize and elucidate unimodal data, revealing subtleties that a single modality may miss. However, there remains a need for further research to bridge the divide between multimodal learning and training studies and foundational AI research.
Towards A Human-in-the-Loop LLM Approach to Collaborative Discourse Analysis
May 06, 2024LLMs have demonstrated proficiency in contextualizing their outputs using human input, often matching or beating human-level performance on a variety of tasks. However, LLMs have not yet been used to characterize synergistic learning in students' collaborative discourse. In this exploratory work, we take a first step towards adopting a human-in-the-loop prompt engineering approach with GPT-4-Turbo to summarize and categorize students' synergistic learning during collaborative discourse. Our preliminary findings suggest GPT-4-Turbo may be able to characterize students' synergistic learning in a manner comparable to humans and that our approach warrants further investigation.
A Chain-of-Thought Prompting Approach with LLMs for Evaluating Students' Formative Assessment Responses in Science
Mar 21, 2024



This paper explores the use of large language models (LLMs) to score and explain short-answer assessments in K-12 science. While existing methods can score more structured math and computer science assessments, they often do not provide explanations for the scores. Our study focuses on employing GPT-4 for automated assessment in middle school Earth Science, combining few-shot and active learning with chain-of-thought reasoning. Using a human-in-the-loop approach, we successfully score and provide meaningful explanations for formative assessment responses. A systematic analysis of our method's pros and cons sheds light on the potential for human-in-the-loop techniques to enhance automated grading for open-ended science assessments.