 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetPO: In-Context Learning with Multi-Modal LLMs for Few-Shot Object Detection
Mar 24, 2026Multi-Modal LLMs (MLLMs) demonstrate strong visual grounding capabilities on popular object detection benchmarks like OdinW-13 and RefCOCO. However, state-of-the-art models still struggle to generalize to out-of-distribution classes, tasks and imaging modalities not typically found in their pre-training. While in-context prompting is a common strategy to improve performance across diverse tasks, we find that it often yields lower detection accuracy than prompting with class names alone. This suggests that current MLLMs cannot yet effectively leverage few-shot visual examples and rich textual descriptions for object detection. Since frontier MLLMs are typically only accessible via APIs, and state-of-the-art open-weights models are prohibitively expensive to fine-tune on consumer-grade hardware, we instead explore black-box prompt optimization for few-shot object detection. To this end, we propose Detection Prompt Optimization (DetPO), a gradient-free test-time optimization approach that refines text-only prompts by maximizing detection accuracy on few-shot visual training examples while calibrating prediction confidence. Our proposed approach yields consistent improvements across generalist MLLMs on Roboflow20-VL and LVIS, outperforming prior black-box approaches by up to 9.7%. Our code is available at https://github.com/ggare-cmu/DetPO
Designing Gaze Analytics for ELA Instruction: A User-Centered Dashboard with Conversational AI Support
Sep 03, 2025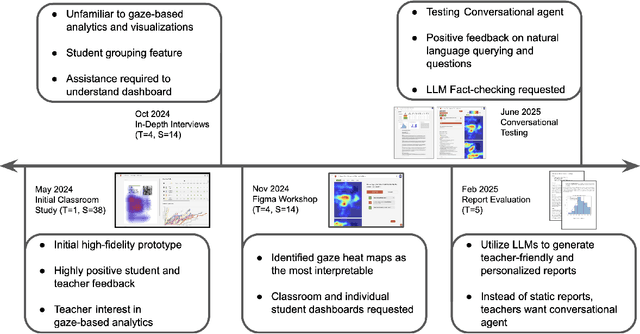
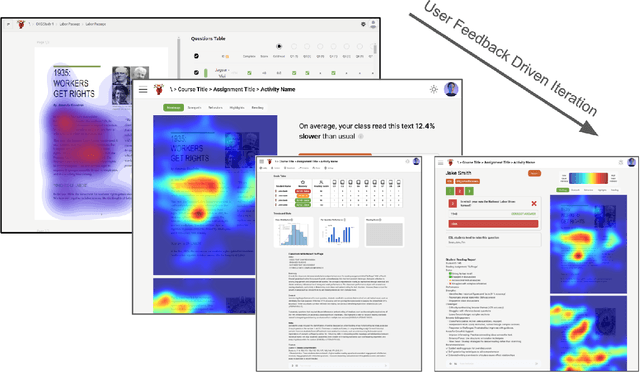
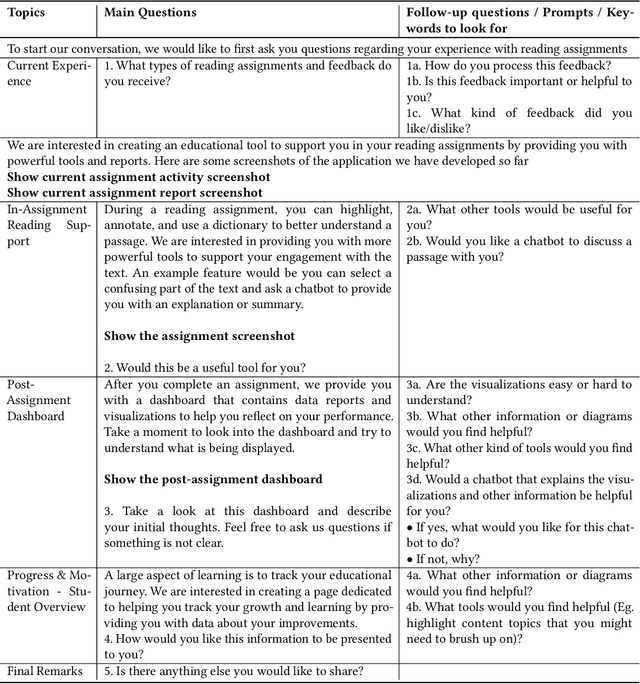
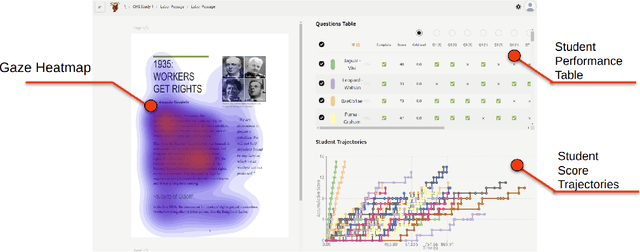
Eye-tracking offers rich insights into student cognition and engagement, but remains underutilized in classroom-facing educational technology due to challenges in data interpretation and accessibility. In this paper, we present the iterative design and evaluation of a gaze-based learning analytics dashboard for English Language Arts (ELA), developed through five studies involving teachers and students. Guided by user-centered design and data storytelling principles, we explored how gaze data can support reflection, formative assessment, and instructional decision-making. Our findings demonstrate that gaze analytics can be approachable and pedagogically valuable when supported by familiar visualizations, layered explanations, and narrative scaffolds. We further show how a conversational agent, powered by a large language model (LLM), can lower cognitive barriers to interpreting gaze data by enabling natural language interactions with multimodal learning analytics. We conclude with design implications for future EdTech systems that aim to integrate novel data modalities in classroom contexts.
Personalizing Student-Agent Interactions Using Log-Contextualized Retrieval Augmented Generation (RAG)
May 22, 2025Collaborative dialogue offers rich insights into students' learning and critical thinking. This is essential for adapting pedagogical agents to students' learning and problem-solving skills in STEM+C settings. While large language models (LLMs) facilitate dynamic pedagogical interactions, potential hallucinations can undermine confidence, trust, and instructional value. Retrieval-augmented generation (RAG) grounds LLM outputs in curated knowledge, but its effectiveness depends on clear semantic links between user input and a knowledge base, which are often weak in student dialogue. We propose log-contextualized RAG (LC-RAG), which enhances RAG retrieval by incorporating environment logs to contextualize collaborative discourse. Our findings show that LC-RAG improves retrieval over a discourse-only baseline and allows our collaborative peer agent, Copa, to deliver relevant, personalized guidance that supports students' critical thinking and epistemic decision-making in a collaborative computational modeling environment, XYZ.
DiffPrompter: Differentiable Implicit Visual Prompts for Semantic-Segmentation in Adverse Conditions
Oct 06, 2023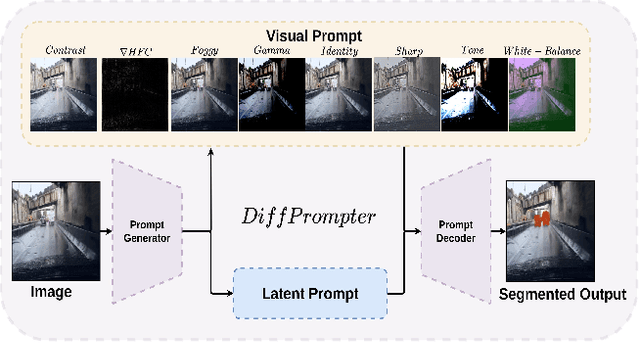



Semantic segmentation in adverse weather scenarios is a critical task for autonomous driving systems. While foundation models have shown promise, the need for specialized adaptors becomes evident for handling more challenging scenarios. We introduce DiffPrompter, a novel differentiable visual and latent prompting mechanism aimed at expanding the learning capabilities of existing adaptors in foundation models. Our proposed $\nabla$HFC image processing block excels particularly in adverse weather conditions, where conventional methods often fall short. Furthermore, we investigate the advantages of jointly training visual and latent prompts, demonstrating that this combined approach significantly enhances performance in out-of-distribution scenarios. Our differentiable visual prompts leverage parallel and series architectures to generate prompts, effectively improving object segmentation tasks in adverse conditions. Through a comprehensive series of experiments and evaluations, we provide empirical evidence to support the efficacy of our approach. Project page at https://diffprompter.github.io.
Light Weight Character and Shape Recognition for Autonomous Drones
Aug 14, 2022


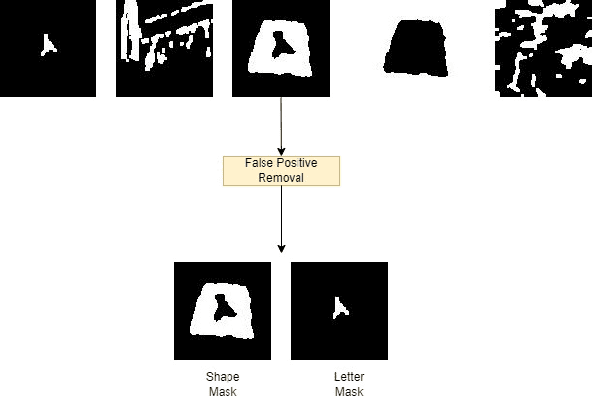
There has been an extensive use of Unmanned Aerial Vehicles in search and rescue missions to distribute first aid kits and food packets. It is important that these UAVs are able to identify and distinguish the markers from one another for effective distribution. One of the common ways to mark the locations is via the use of characters superimposed on shapes of various colors which gives rise to wide variety of markers based on combination of different shapes, characters, and their respective colors. In this paper, we propose an object detection and classification pipeline which prevents false positives and minimizes misclassification of alphanumeric characters and shapes in aerial images. Our method makes use of traditional computer vision techniques and unsupervised machine learning methods for identifying region proposals, segmenting the image targets and removing false positives. We make use of a computationally light model for classification, making it easy to be deployed on any aerial vehicle.
A Studious Approach to Semi-Supervised Learning
Sep 18, 2021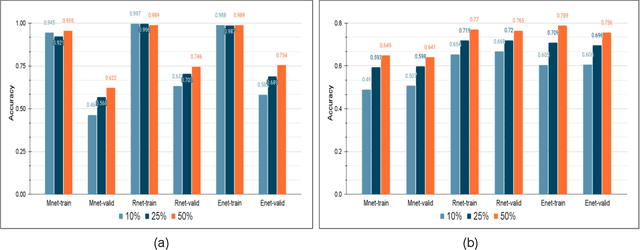
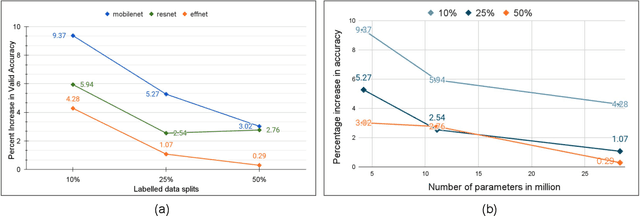
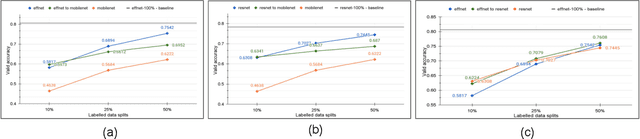
The problem of learning from few labeled examples while using large amounts of unlabeled data has been approached by various semi-supervised methods. Although these methods can achieve superior performance, the models are often not deployable due to the large number of parameters. This paper is an ablation study of distillation in a semi-supervised setting, which not just reduces the number of parameters of the model but can achieve this while improving the performance over the baseline supervised model and making it better at generalizing. After the supervised pretraining, the network is used as a teacher model, and a student network is trained over the soft labels that the teacher model generates over the entire unlabeled data. We find that the fewer the labels, the more this approach benefits from a smaller student network. This brings forward the potential of distillation as an effective solution to enhance performance in semi-supervised computer vision tasks while maintaining deployability.