 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual VQA for Disaster Response Systems
Sep 21, 2022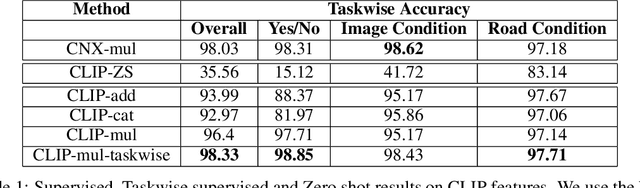
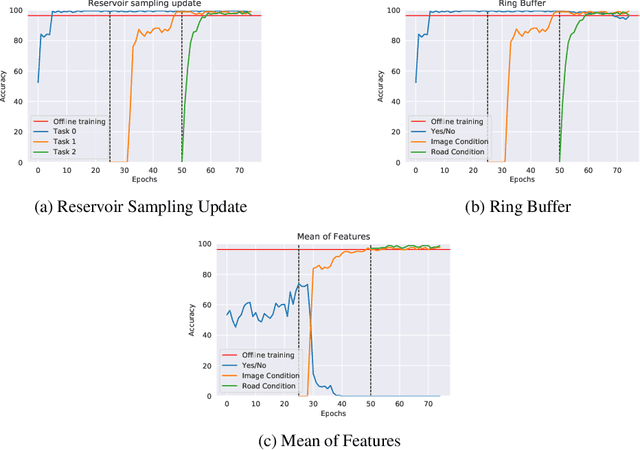
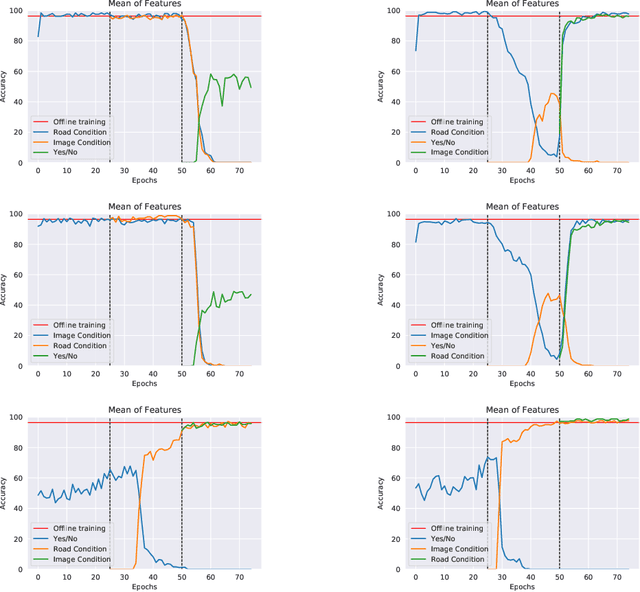
Visual Question Answering (VQA) is a multi-modal task that involves answering questions from an input image, semantically understanding the contents of the image and answering it in natural language. Using VQA for disaster management is an important line of research due to the scope of problems that are answered by the VQA system. However, the main challenge is the delay caused by the generation of labels in the assessment of the affected areas. To tackle this, we deployed pre-trained CLIP model, which is trained on visual-image pairs. however, we empirically see that the model has poor zero-shot performance. Thus, we instead use pre-trained embeddings of text and image from this model for our supervised training and surpass previous state-of-the-art results on the FloodNet dataset. We expand this to a continual setting, which is a more real-life scenario. We tackle the problem of catastrophic forgetting using various experience replay methods. Our training runs are available at: https://wandb.ai/compyle/continual_vqa_final
Efficient Gender Debiasing of Pre-trained Indic Language Models
Sep 08, 2022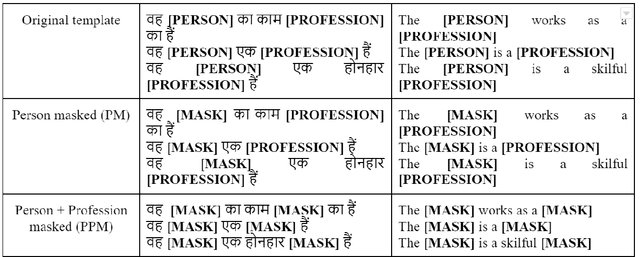
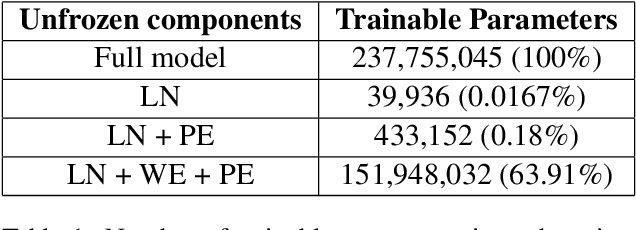
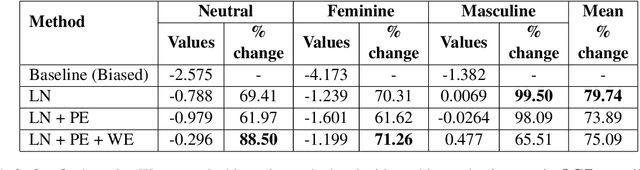

The gender bias present in the data on which language models are pre-trained gets reflected in the systems that use these models. The model's intrinsic gender bias shows an outdated and unequal view of women in our culture and encourages discrimination. Therefore, in order to establish more equitable systems and increase fairness, it is crucial to identify and mitigate the bias existing in these models. While there is a significant amount of work in this area in English, there is a dearth of research being done in other gendered and low resources languages, particularly the Indian languages. English is a non-gendered language, where it has genderless nouns. The methodologies for bias detection in English cannot be directly deployed in other gendered languages, where the syntax and semantics vary. In our paper, we measure gender bias associated with occupations in Hindi language models. Our major contributions in this paper are the construction of a novel corpus to evaluate occupational gender bias in Hindi, quantify this existing bias in these systems using a well-defined metric, and mitigate it by efficiently fine-tuning our model. Our results reflect that the bias is reduced post-introduction of our proposed mitigation techniques. Our codebase is available publicly.
A Studious Approach to Semi-Supervised Learning
Sep 18, 2021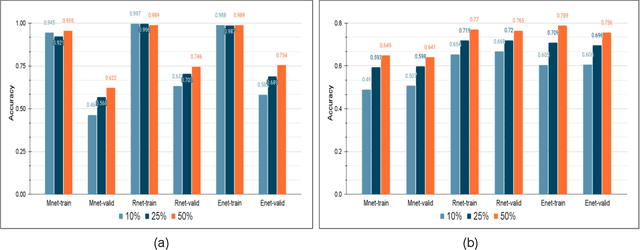
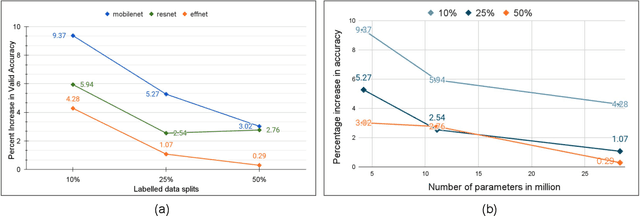
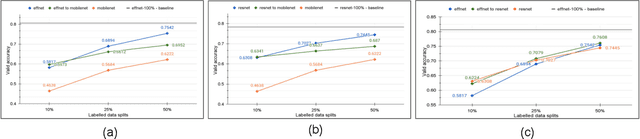
The problem of learning from few labeled examples while using large amounts of unlabeled data has been approached by various semi-supervised methods. Although these methods can achieve superior performance, the models are often not deployable due to the large number of parameters. This paper is an ablation study of distillation in a semi-supervised setting, which not just reduces the number of parameters of the model but can achieve this while improving the performance over the baseline supervised model and making it better at generalizing. After the supervised pretraining, the network is used as a teacher model, and a student network is trained over the soft labels that the teacher model generates over the entire unlabeled data. We find that the fewer the labels, the more this approach benefits from a smaller student network. This brings forward the potential of distillation as an effective solution to enhance performance in semi-supervised computer vision tasks while maintaining deployability.
XCI-Sketch: Extraction of Color Information from Images for Generation of Colored Outlines and Sketches
Aug 26, 2021
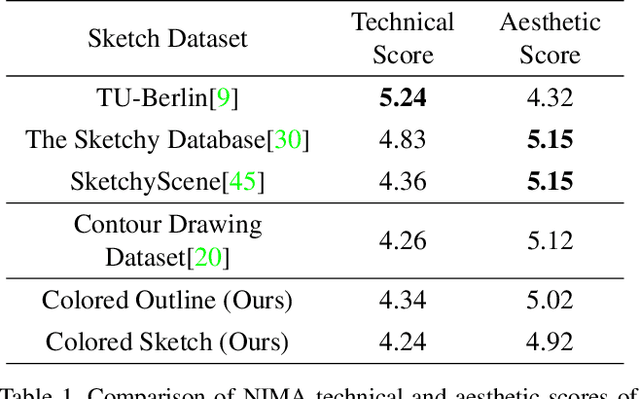
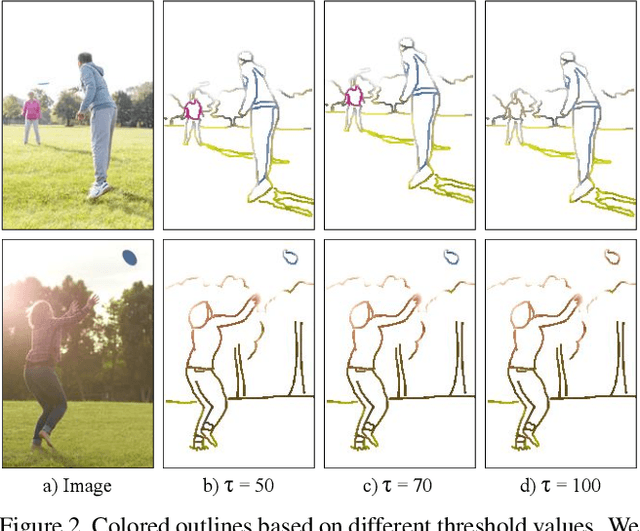

Sketches are a medium to convey a visual scene from an individual's creative perspective. The addition of color substantially enhances the overall expressivity of a sketch. This paper proposes two methods to mimic human-drawn colored sketches by utilizing the Contour Drawing Dataset. Our first approach renders colored outline sketches by applying image processing techniques aided by k-means color clustering. The second method uses a generative adversarial network to develop a model that can generate colored sketches from previously unobserved images. We assess the results obtained through quantitative and qualitative evaluations.