 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosis of Human Object Interaction Detectors for Real World Educational Applications
Jun 01, 2026Human-object interaction (HOI) recognition is critical for automatically analyzing student behavior in complex educational environments. Although state-of-the-art (SOTA) HOI detectors perform well on benchmark datasets, their performance often degrades when deployed in real-world training environments due to domain-specific objects, occlusions, and complex visual conditions. In this paper, we introduce a diagnosis-driven framework that integrates a triplet-level HOI error taxonomy with error-factor attribution analysis for real-world educational video data. We study this problem in the context of Critical Care Air Transport Team (CCATT) mixed-reality medical training. Based on an analysis of HOI failure modes and their causes, we develop a diagnosis-informed refinement strategy for adapting pretrained HOI models to the target domain. Experiments on the CCATT dataset show that this approach improves the macro-F1 score of a pretrained CDN model from 48.6 to 90.2 through targeted refinement guided by diagnosed error factors. These results highlight the value of detailed diagnostic analysis for informing targeted adaptation of HOI models in real-world educational environments.
Safe Continual Reinforcement Learning in Non-stationary Environments
Apr 21, 2026Reinforcement learning (RL) offers a compelling data-driven paradigm for synthesizing controllers for complex systems when accurate physical models are unavailable; however, most existing control-oriented RL methods assume stationarity and, therefore, struggle in real-world non-stationary deployments where system dynamics and operating conditions can change unexpectedly. Moreover, RL controllers acting in physical environments must satisfy safety constraints throughout their learning and execution phases, rendering transient violations during adaptation unacceptable. Although continual RL and safe RL have each addressed non-stationarity and safety, respectively, their intersection remains comparatively unexplored, motivating the study of safe continual RL algorithms that can adapt over the system's lifetime while preserving safety. In this work, we systematically investigate safe continual reinforcement learning by introducing three benchmark environments that capture safety-critical continual adaptation and by evaluating representative approaches from safe RL, continual RL, and their combinations. Our empirical results reveal a fundamental tension between maintaining safety constraints and preventing catastrophic forgetting under non-stationary dynamics, with existing methods generally failing to achieve both objectives simultaneously. To address this shortcoming, we examine regularization-based strategies that partially mitigate this trade-off and characterize their benefits and limitations. Finally, we outline key open challenges and research directions toward developing safe, resilient learning-based controllers capable of sustained autonomous operation in changing environments.
Video-Based Performance Evaluation for ECR Drills in Synthetic Training Environments
Dec 29, 2025Effective urban warfare training requires situational awareness and muscle memory, developed through repeated practice in realistic yet controlled environments. A key drill, Enter and Clear the Room (ECR), demands threat assessment, coordination, and securing confined spaces. The military uses Synthetic Training Environments that offer scalable, controlled settings for repeated exercises. However, automatic performance assessment remains challenging, particularly when aiming for objective evaluation of cognitive, psychomotor, and teamwork skills. Traditional methods often rely on costly, intrusive sensors or subjective human observation, limiting scalability and accuracy. This paper introduces a video-based assessment pipeline that derives performance analytics from training videos without requiring additional hardware. By utilizing computer vision models, the system extracts 2D skeletons, gaze vectors, and movement trajectories. From these data, we develop task-specific metrics that measure psychomotor fluency, situational awareness, and team coordination. These metrics feed into an extended Cognitive Task Analysis (CTA) hierarchy, which employs a weighted combination to generate overall performance scores for teamwork and cognition. We demonstrate the approach with a case study of real-world ECR drills, providing actionable, domain specific metrics that capture individual and team performance. We also discuss how these insights can support After Action Reviews with interactive dashboards within Gamemaster and the Generalized Intelligent Framework for Tutoring (GIFT), providing intuitive and understandable feedback. We conclude by addressing limitations, including tracking difficulties, ground-truth validation, and the broader applicability of our approach. Future work includes expanding analysis to 3D video data and leveraging video analysis to enable scalable evaluation within STEs.
On the Design of Safe Continual RL Methods for Control of Nonlinear Systems
Feb 21, 2025



Reinforcement learning (RL) algorithms have been successfully applied to control tasks associated with unmanned aerial vehicles and robotics. In recent years, safe RL has been proposed to allow the safe execution of RL algorithms in industrial and mission-critical systems that operate in closed loops. However, if the system operating conditions change, such as when an unknown fault occurs in the system, typical safe RL algorithms are unable to adapt while retaining past knowledge. Continual reinforcement learning algorithms have been proposed to address this issue. However, the impact of continual adaptation on the system's safety is an understudied problem. In this paper, we study the intersection of safe and continual RL. First, we empirically demonstrate that a popular continual RL algorithm, online elastic weight consolidation, is unable to satisfy safety constraints in non-linear systems subject to varying operating conditions. Specifically, we study the MuJoCo HalfCheetah and Ant environments with velocity constraints and sudden joint loss non-stationarity. Then, we show that an agent trained using constrained policy optimization, a safe RL algorithm, experiences catastrophic forgetting in continual learning settings. With this in mind, we explore a simple reward-shaping method to ensure that elastic weight consolidation prioritizes remembering both safety and task performance for safety-constrained, non-linear, and non-stationary dynamical systems.
FT-AED: Benchmark Dataset for Early Freeway Traffic Anomalous Event Detection
Jun 24, 2024



Early and accurate detection of anomalous events on the freeway, such as accidents, can improve emergency response and clearance. However, existing delays and errors in event identification and reporting make it a difficult problem to solve. Current large-scale freeway traffic datasets are not designed for anomaly detection and ignore these challenges. In this paper, we introduce the first large-scale lane-level freeway traffic dataset for anomaly detection. Our dataset consists of a month of weekday radar detection sensor data collected in 4 lanes along an 18-mile stretch of Interstate 24 heading toward Nashville, TN, comprising over 3.7 million sensor measurements. We also collect official crash reports from the Nashville Traffic Management Center and manually label all other potential anomalies in the dataset. To show the potential for our dataset to be used in future machine learning and traffic research, we benchmark numerous deep learning anomaly detection models on our dataset. We find that unsupervised graph neural network autoencoders are a promising solution for this problem and that ignoring spatial relationships leads to decreased performance. We demonstrate that our methods can reduce reporting delays by over 10 minutes on average while detecting 75% of crashes. Our dataset and all preprocessing code needed to get started are publicly released at https://vu.edu/ft-aed/ to facilitate future research.
MARVEL: Multi-Agent Reinforcement-Learning for Large-Scale Variable Speed Limits
Oct 18, 2023



Variable speed limit (VSL) control is a promising traffic management strategy for enhancing safety and mobility. This work introduces MARVEL, a multi-agent reinforcement learning (MARL) framework for implementing large-scale VSL control on freeway corridors using only commonly available data. The agents learn through a reward structure that incorporates adaptability to traffic conditions, safety, and mobility; enabling coordination among the agents. The proposed framework scales to cover corridors with many gantries thanks to a parameter sharing among all VSL agents. The agents are trained in a microsimulation environment based on a short freeway stretch with 8 gantries spanning 7 miles and tested with 34 gantries spanning 17 miles of I-24 near Nashville, TN. MARVEL improves traffic safety by 63.4% compared to the no control scenario and enhances traffic mobility by 14.6% compared to a state-of-the-practice algorithm that has been deployed on I-24. An explainability analysis is undertaken to explore the learned policy under different traffic conditions and the results provide insights into the decision-making process of agents. Finally, we test the policy learned from the simulation-based experiments on real input data from I-24 to illustrate the potential deployment capability of the learned policy.
A Reinforcement Learning Approach for Robust Supervisory Control of UAVs Under Disturbances
May 21, 2023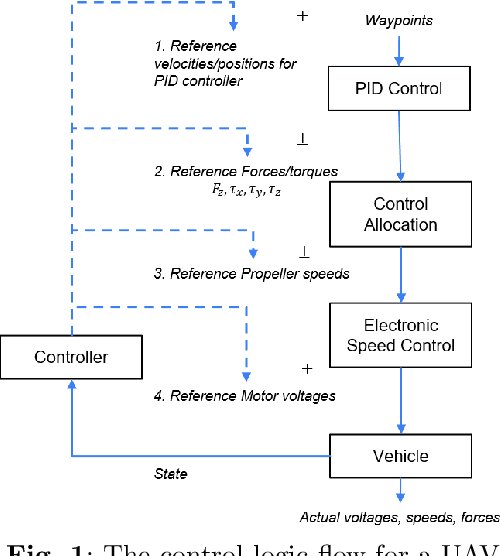
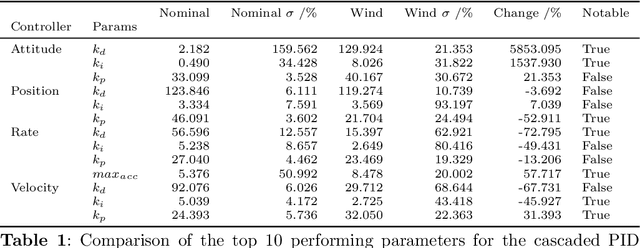
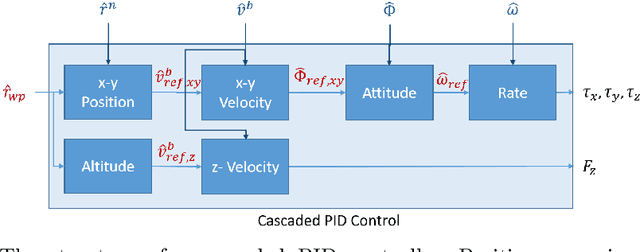
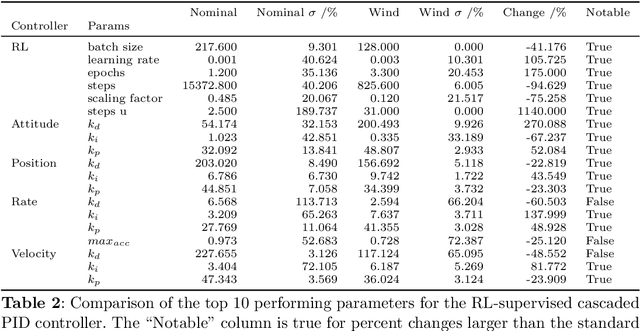
In this work, we present an approach to supervisory reinforcement learning control for unmanned aerial vehicles (UAVs). UAVs are dynamic systems where control decisions in response to disturbances in the environment have to be made in the order of milliseconds. We formulate a supervisory control architecture that interleaves with extant embedded control and demonstrates robustness to environmental disturbances in the form of adverse wind conditions. We run case studies with a Tarot T-18 Octorotor to demonstrate the effectiveness of our approach and compare it against a classic cascade control architecture used in most vehicles. While the results show the performance difference is marginal for nominal operations, substantial performance improvement is obtained with the supervisory RL approach under unseen wind conditions.
Model-based adaptation for sample efficient transfer in reinforcement learning control of parameter-varying systems
May 20, 2023In this paper, we leverage ideas from model-based control to address the sample efficiency problem of reinforcement learning (RL) algorithms. Accelerating learning is an active field of RL highly relevant in the context of time-varying systems. Traditional transfer learning methods propose to use prior knowledge of the system behavior to devise a gradual or immediate data-driven transformation of the control policy obtained through RL. Such transformation is usually computed by estimating the performance of previous control policies based on measurements recently collected from the system. However, such retrospective measures have debatable utility with no guarantees of positive transfer in most cases. Instead, we propose a model-based transformation, such that when actions from a control policy are applied to the target system, a positive transfer is achieved. The transformation can be used as an initialization for the reinforcement learning process to converge to a new optimum. We validate the performance of our approach through four benchmark examples. We demonstrate that our approach is more sample-efficient than fine-tuning with reinforcement learning alone and achieves comparable performance to linear-quadratic-regulators and model-predictive control when an accurate linear model is known in the three cases. If an accurate model is not known, we empirically show that the proposed approach still guarantees positive transfer with jump-start improvement.
Concurrent Policy Blending and System Identification for Generalized Assistive Control
May 19, 2022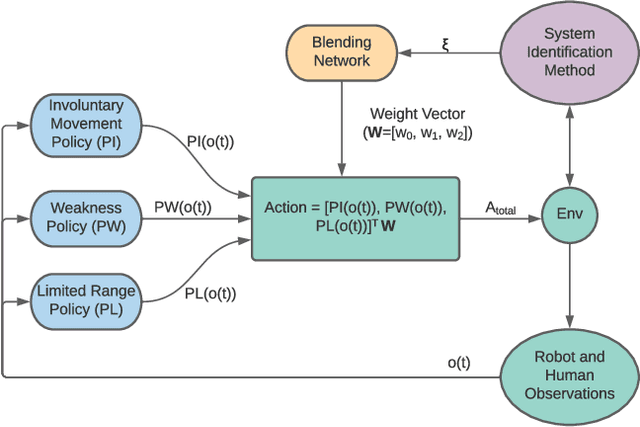

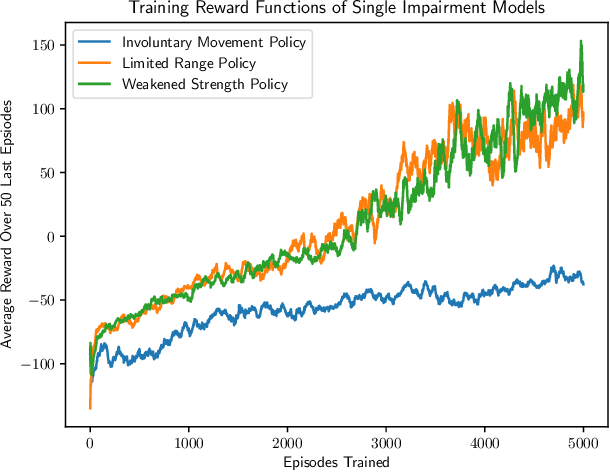
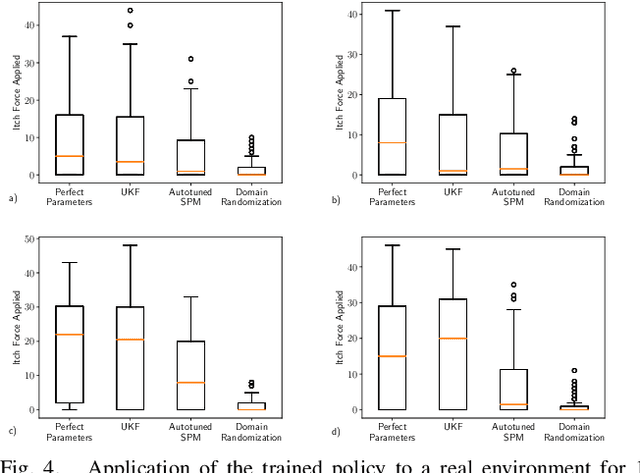
In this work, we address the problem of solving complex collaborative robotic tasks subject to multiple varying parameters. Our approach combines simultaneous policy blending with system identification to create generalized policies that are robust to changes in system parameters. We employ a blending network whose state space relies solely on parameter estimates from a system identification technique. As a result, this blending network learns how to handle parameter changes instead of trying to learn how to solve the task for a generalized parameter set simultaneously. We demonstrate our scheme's ability on a collaborative robot and human itching task in which the human has motor impairments. We then showcase our approach's efficiency with a variety of system identification techniques when compared to standard domain randomization.
Performance-Weighed Policy Sampling for Meta-Reinforcement Learning
Dec 10, 2020
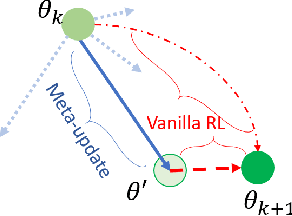
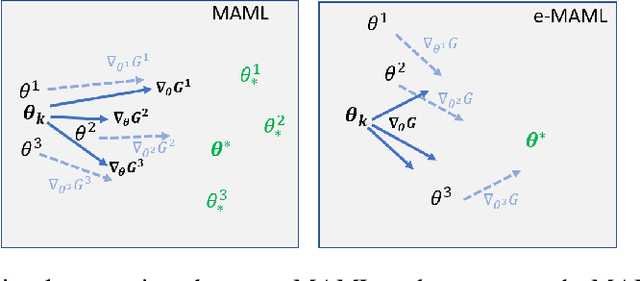
This paper discusses an Enhanced Model-Agnostic Meta-Learning (E-MAML) algorithm that generates fast convergence of the policy function from a small number of training examples when applied to new learning tasks. Built on top of Model-Agnostic Meta-Learning (MAML), E-MAML maintains a set of policy parameters learned in the environment for previous tasks. We apply E-MAML to developing reinforcement learning (RL)-based online fault tolerant control schemes for dynamic systems. The enhancement is applied when a new fault occurs, to re-initialize the parameters of a new RL policy that achieves faster adaption with a small number of samples of system behavior with the new fault. This replaces the random task sampling step in MAML. Instead, it exploits the extant previously generated experiences of the controller. The enhancement is sampled to maximally span the parameter space to facilitate adaption to the new fault. We demonstrate the performance of our approach combining E-MAML with proximal policy optimization (PPO) on the well-known cart pole example, and then on the fuel transfer system of an aircraft.