 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reinforcement Learning Approach for Robust Supervisory Control of UAVs Under Disturbances
May 21, 2023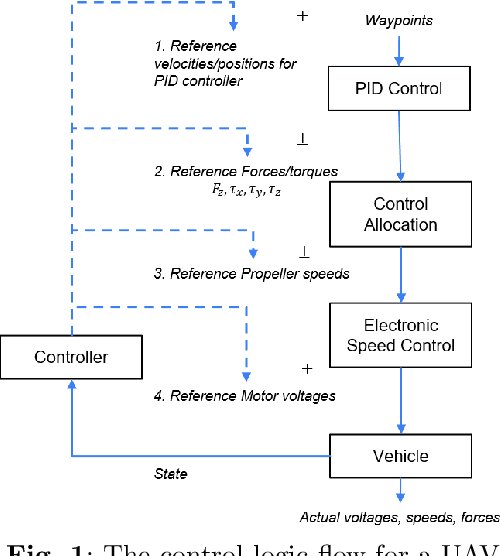
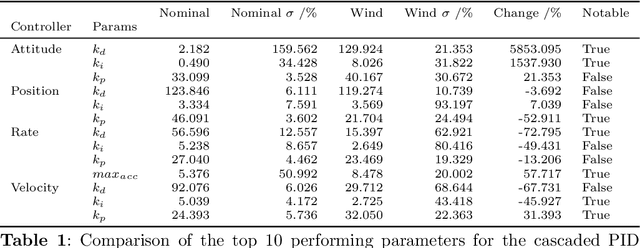
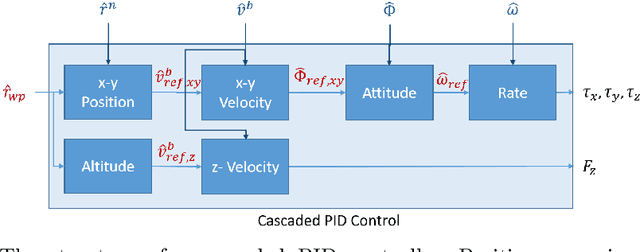
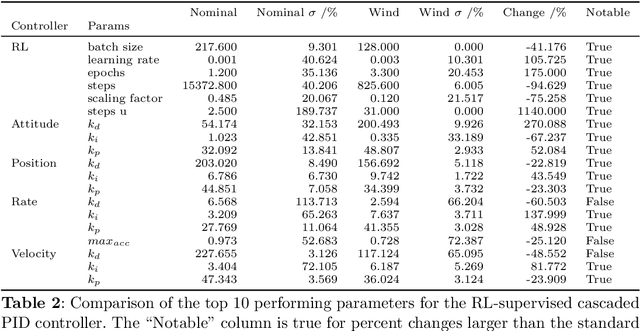
In this work, we present an approach to supervisory reinforcement learning control for unmanned aerial vehicles (UAVs). UAVs are dynamic systems where control decisions in response to disturbances in the environment have to be made in the order of milliseconds. We formulate a supervisory control architecture that interleaves with extant embedded control and demonstrates robustness to environmental disturbances in the form of adverse wind conditions. We run case studies with a Tarot T-18 Octorotor to demonstrate the effectiveness of our approach and compare it against a classic cascade control architecture used in most vehicles. While the results show the performance difference is marginal for nominal operations, substantial performance improvement is obtained with the supervisory RL approach under unseen wind conditions.
Model-based adaptation for sample efficient transfer in reinforcement learning control of parameter-varying systems
May 20, 2023In this paper, we leverage ideas from model-based control to address the sample efficiency problem of reinforcement learning (RL) algorithms. Accelerating learning is an active field of RL highly relevant in the context of time-varying systems. Traditional transfer learning methods propose to use prior knowledge of the system behavior to devise a gradual or immediate data-driven transformation of the control policy obtained through RL. Such transformation is usually computed by estimating the performance of previous control policies based on measurements recently collected from the system. However, such retrospective measures have debatable utility with no guarantees of positive transfer in most cases. Instead, we propose a model-based transformation, such that when actions from a control policy are applied to the target system, a positive transfer is achieved. The transformation can be used as an initialization for the reinforcement learning process to converge to a new optimum. We validate the performance of our approach through four benchmark examples. We demonstrate that our approach is more sample-efficient than fine-tuning with reinforcement learning alone and achieves comparable performance to linear-quadratic-regulators and model-predictive control when an accurate linear model is known in the three cases. If an accurate model is not known, we empirically show that the proposed approach still guarantees positive transfer with jump-start improvement.
Answer Fast: Accelerating BERT on the Tensor Streaming Processor
Jun 22, 2022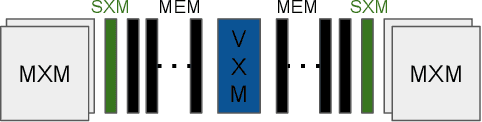
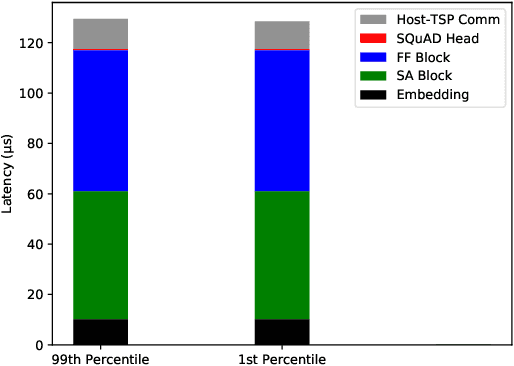
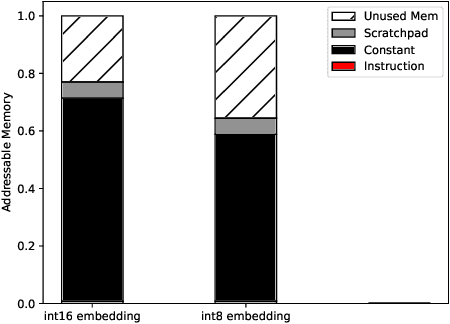

Transformers have become a predominant machine learning workload, they are not only the de-facto standard for natural language processing tasks, but they are also being deployed in other domains such as vision and speech recognition. Many of the transformer-based applications are real-time systems such as machine translation and web search. These real time systems often come with strict end-to-end inference latency requirements. Unfortunately, while the majority of the transformer computation comes from matrix multiplications, transformers also include several non-linear components that tend to become the bottleneck during an inference. In this work, we accelerate the inference of BERT models on the tensor streaming processor. By carefully fusing all the nonlinear components with the matrix multiplication components, we are able to efficiently utilize the on-chip matrix multiplication units resulting in a deterministic tail latency of 130 $\mu$s for a batch-1 inference through BERT-base, which is 6X faster than the current state-of-the-art.
Performance-Weighed Policy Sampling for Meta-Reinforcement Learning
Dec 10, 2020
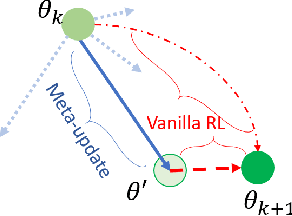
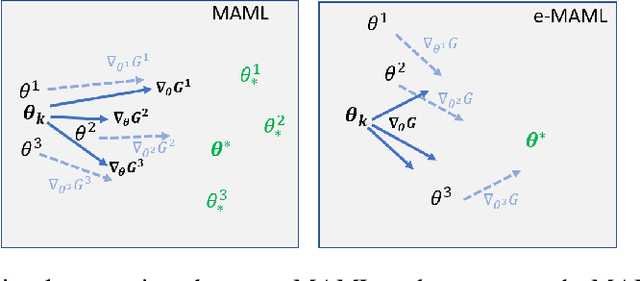
This paper discusses an Enhanced Model-Agnostic Meta-Learning (E-MAML) algorithm that generates fast convergence of the policy function from a small number of training examples when applied to new learning tasks. Built on top of Model-Agnostic Meta-Learning (MAML), E-MAML maintains a set of policy parameters learned in the environment for previous tasks. We apply E-MAML to developing reinforcement learning (RL)-based online fault tolerant control schemes for dynamic systems. The enhancement is applied when a new fault occurs, to re-initialize the parameters of a new RL policy that achieves faster adaption with a small number of samples of system behavior with the new fault. This replaces the random task sampling step in MAML. Instead, it exploits the extant previously generated experiences of the controller. The enhancement is sampled to maximally span the parameter space to facilitate adaption to the new fault. We demonstrate the performance of our approach combining E-MAML with proximal policy optimization (PPO) on the well-known cart pole example, and then on the fuel transfer system of an aircraft.
Complementary Meta-Reinforcement Learning for Fault-Adaptive Control
Sep 26, 2020
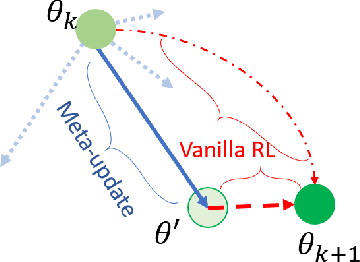

Faults are endemic to all systems. Adaptive fault-tolerant control maintains degraded performance when faults occur as opposed to unsafe conditions or catastrophic events. In systems with abrupt faults and strict time constraints, it is imperative for control to adapt quickly to system changes to maintain system operations. We present a meta-reinforcement learning approach that quickly adapts its control policy to changing conditions. The approach builds upon model-agnostic meta learning (MAML). The controller maintains a complement of prior policies learned under system faults. This "library" is evaluated on a system after a new fault to initialize the new policy. This contrasts with MAML, where the controller derives intermediate policies anew, sampled from a distribution of similar systems, to initialize a new policy. Our approach improves sample efficiency of the reinforcement learning process. We evaluate our approach on an aircraft fuel transfer system under abrupt faults.
Fault-Tolerant Control of Degrading Systems with On-Policy Reinforcement Learning
Aug 10, 2020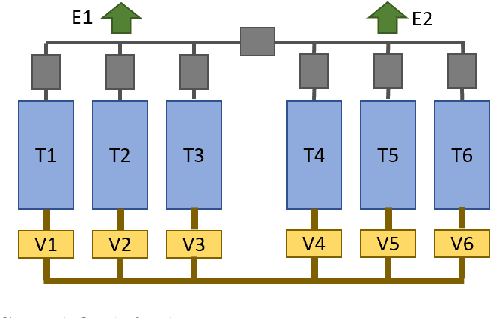

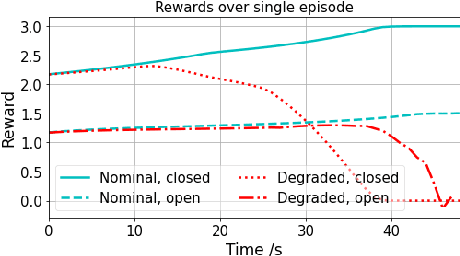
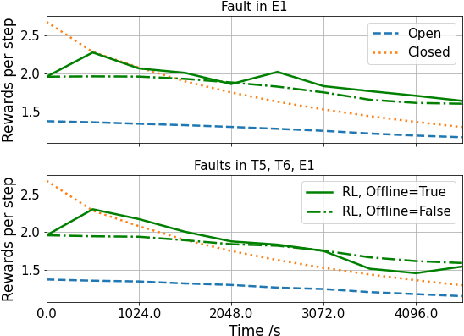
We propose a novel adaptive reinforcement learning control approach for fault tolerant control of degrading systems that is not preceded by a fault detection and diagnosis step. Therefore, \textit{a priori} knowledge of faults that may occur in the system is not required. The adaptive scheme combines online and offline learning of the on-policy control method to improve exploration and sample efficiency, while guaranteeing stable learning. The offline learning phase is performed using a data-driven model of the system, which is frequently updated to track the system's operating conditions. We conduct experiments on an aircraft fuel transfer system to demonstrate the effectiveness of our approach.
Comparison of Model Predictive and Reinforcement Learning Methods for Fault Tolerant Control
Aug 10, 2020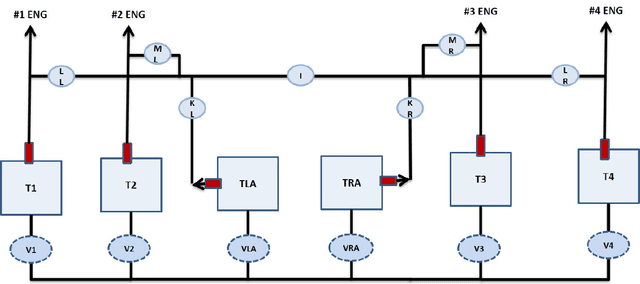

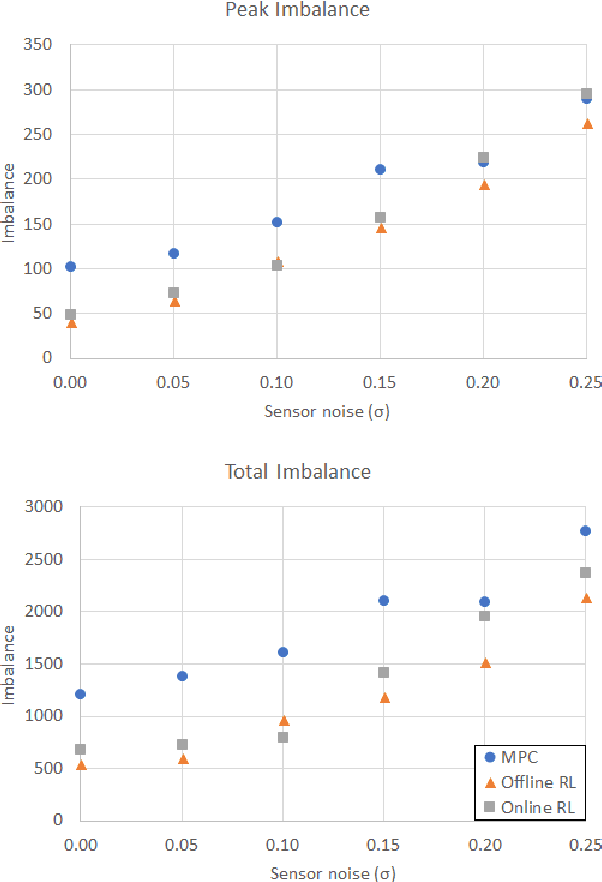

A desirable property in fault-tolerant controllers is adaptability to system changes as they evolve during systems operations. An adaptive controller does not require optimal control policies to be enumerated for possible faults. Instead it can approximate one in real-time. We present two adaptive fault-tolerant control schemes for a discrete time system based on hierarchical reinforcement learning. We compare their performance against a model predictive controller in presence of sensor noise and persistent faults. The controllers are tested on a fuel tank model of a C-130 plane. Our experiments demonstrate that reinforcement learning-based controllers perform more robustly than model predictive controllers under faults, partially observable system models, and varying sensor noise levels.
Quantum-Secure Authentication via Abstract Multi-Agent Interaction
Jul 18, 2020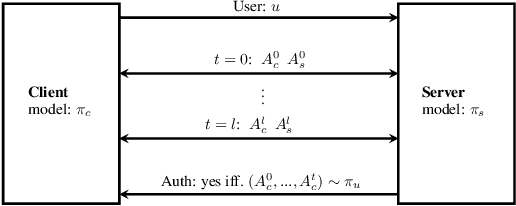
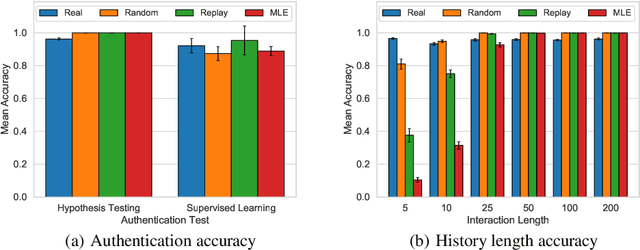
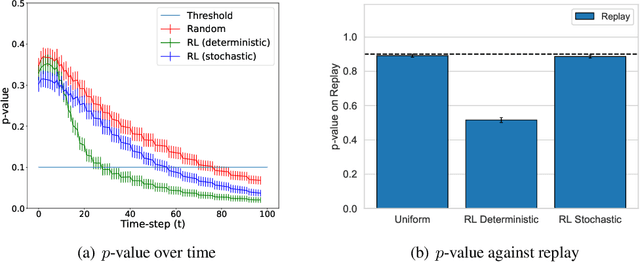
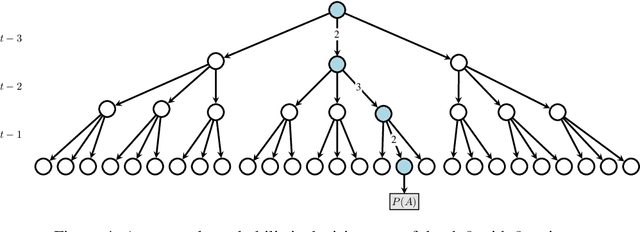
Current methods for authentication based on public-key cryptography are vulnerable to quantum computing. We propose a novel approach to authentication in which communicating parties are viewed as autonomous agents which interact repeatedly using their private decision models. The security of this approach rests upon the difficulty of learning the model parameters of interacting agents, a problem which we conjecture is also hard for quantum computing. We develop methods which enable a server agent to classify a client agent as either legitimate or adversarial based on their past interactions. Moreover, we use reinforcement learning techniques to train server policies which effectively probe the client's decisions to achieve more sample-efficient authentication, while making modelling attacks as difficult as possible via entropy-maximization principles. We empirically validate our methods for authenticating legitimate users while detecting different types of adversarial attacks.