 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Multi-Task Reinforcement Learning via Adaptive Task Sampling
May 14, 2026Multi-task reinforcement learning (MTRL) aims to train a single agent to efficiently optimize performance across multiple tasks simultaneously. However, jointly optimizing all tasks often yields imbalanced learning: agents quickly solve easy tasks but learn slowly on harder ones. While prior work primarily attributes this imbalance to conflicting task gradients and proposes gradient manipulation or specialized architectures to address it, we instead focus on a distinct and under-explored challenge: imbalanced data allocation. Standard MTRL allocates an equal number of environment interactions to each task, which over-allocates data to easy tasks that require relatively few interactions to solve and under-allocates data to hard tasks that require substantially more experience to solve. To address this challenge, we introduce Distributionally Robust Adaptive Task Sampling (DRATS), an algorithm that adaptively prioritizes sampling tasks furthest from being solved. We derive DRATS by formalizing MTRL as a feasibility problem from which we derive a minimax objective for minimizing the worst-case return gap, the difference between a desired target return and the agent's return on a task. In benchmarks like MetaWorld-MT10 and MT50, DRATS improves data efficiency and increases worst-task performance compared to existing task sampling algorithms.
Abstract Sim2Real through Approximate Information States
Apr 16, 2026In recent years, reinforcement learning (RL) has shown remarkable success in robotics when a fast and accurate simulator is available for a given task. When using RL and simulation, more simulator realism is generally beneficial but becomes harder to obtain as robots are deployed in increasingly complex and widescale domains. In such settings, simulators will likely fail to model all relevant details of a given target task and this observation motivates the study of sim2real with simulators that leave out key task details. In this paper, we formalize and study the abstract sim2real problem: given an abstract simulator that models a target task at a coarse level of abstraction, how can we train a policy with RL in the abstract simulator and successfully transfer it to the real-world? Our first contribution is to formalize this problem using the language of state abstraction from the RL literature. This framing shows that an abstract simulator can be grounded to match the target task if the grounded abstract dynamics take the history of states into account. Based on the formalism, we then introduce a method that uses real-world task data to correct the dynamics of the abstract simulator. We then show that this method enables successful policy transfer both in sim2sim and sim2real evaluation.
Demystifying the Paradox of Importance Sampling with an Estimated History-Dependent Behavior Policy in Off-Policy Evaluation
May 28, 2025This paper studies off-policy evaluation (OPE) in reinforcement learning with a focus on behavior policy estimation for importance sampling. Prior work has shown empirically that estimating a history-dependent behavior policy can lead to lower mean squared error (MSE) even when the true behavior policy is Markovian. However, the question of why the use of history should lower MSE remains open. In this paper, we theoretically demystify this paradox by deriving a bias-variance decomposition of the MSE of ordinary importance sampling (IS) estimators, demonstrating that history-dependent behavior policy estimation decreases their asymptotic variances while increasing their finite-sample biases. Additionally, as the estimated behavior policy conditions on a longer history, we show a consistent decrease in variance. We extend these findings to a range of other OPE estimators, including the sequential IS estimator, the doubly robust estimator and the marginalized IS estimator, with the behavior policy estimated either parametrically or non-parametrically.
Multi-Robot Collaboration through Reinforcement Learning and Abstract Simulation
Mar 07, 2025



Teams of people coordinate to perform complex tasks by forming abstract mental models of world and agent dynamics. The use of abstract models contrasts with much recent work in robot learning that uses a high-fidelity simulator and reinforcement learning (RL) to obtain policies for physical robots. Motivated by this difference, we investigate the extent to which so-called abstract simulators can be used for multi-agent reinforcement learning (MARL) and the resulting policies successfully deployed on teams of physical robots. An abstract simulator models the robot's target task at a high-level of abstraction and discards many details of the world that could impact optimal decision-making. Policies are trained in an abstract simulator then transferred to the physical robot by making use of separately-obtained low-level perception and motion control modules. We identify three key categories of modifications to the abstract simulator that enable policy transfer to physical robots: simulation fidelity enhancements, training optimizations and simulation stochasticity. We then run an empirical study with extensive ablations to determine the value of each modification category for enabling policy transfer in cooperative robot soccer tasks. We also compare the performance of policies produced by our method with a well-tuned non-learning-based behavior architecture from the annual RoboCup competition and find that our approach leads to a similar level of performance. Broadly we show that MARL can be use to train cooperative physical robot behaviors using highly abstract models of the world.
Reinforcement Learning Within the Classical Robotics Stack: A Case Study in Robot Soccer
Dec 12, 2024



Robot decision-making in partially observable, real-time, dynamic, and multi-agent environments remains a difficult and unsolved challenge. Model-free reinforcement learning (RL) is a promising approach to learning decision-making in such domains, however, end-to-end RL in complex environments is often intractable. To address this challenge in the RoboCup Standard Platform League (SPL) domain, we developed a novel architecture integrating RL within a classical robotics stack, while employing a multi-fidelity sim2real approach and decomposing behavior into learned sub-behaviors with heuristic selection. Our architecture led to victory in the 2024 RoboCup SPL Challenge Shield Division. In this work, we fully describe our system's architecture and empirically analyze key design decisions that contributed to its success. Our approach demonstrates how RL-based behaviors can be integrated into complete robot behavior architectures.
Stable Offline Value Function Learning with Bisimulation-based Representations
Oct 02, 2024



In reinforcement learning, offline value function learning is the procedure of using an offline dataset to estimate the expected discounted return from each state when taking actions according to a fixed target policy. The stability of this procedure, i.e., whether it converges to its fixed-point, critically depends on the representations of the state-action pairs. Poorly learned representations can make value function learning unstable, or even divergent. Therefore, it is critical to stabilize value function learning by explicitly shaping the state-action representations. Recently, the class of bisimulation-based algorithms have shown promise in shaping representations for control. However, it is still unclear if this class of methods can stabilize value function learning. In this work, we investigate this question and answer it affirmatively. We introduce a bisimulation-based algorithm called kernel representations for offline policy evaluation (KROPE). KROPE uses a kernel to shape state-action representations such that state-action pairs that have similar immediate rewards and lead to similar next state-action pairs under the target policy also have similar representations. We show that KROPE: 1) learns stable representations and 2) leads to lower value error than baselines. Our analysis provides new theoretical insight into the stability properties of bisimulation-based methods and suggests that practitioners can use these methods for stable and accurate evaluation of offline reinforcement learning agents.
Reinforcement Learning via Auxiliary Task Distillation
Jun 24, 2024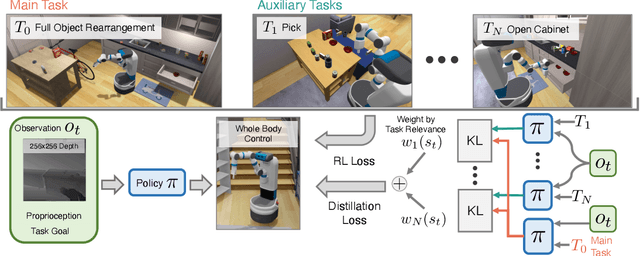
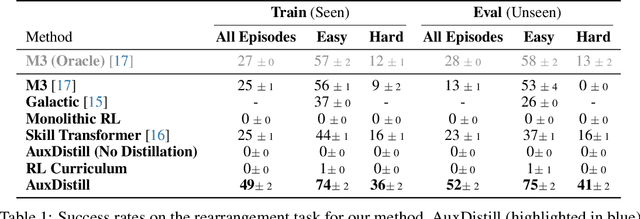
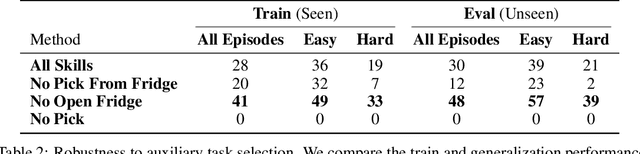
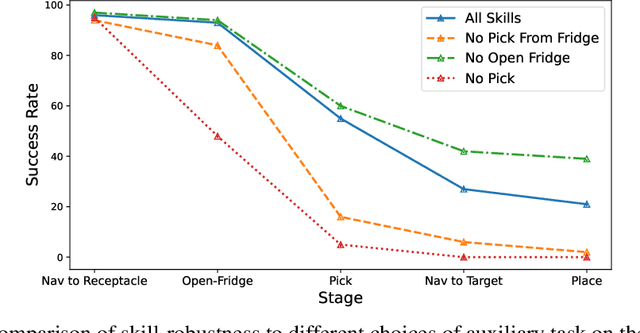
We present Reinforcement Learning via Auxiliary Task Distillation (AuxDistill), a new method that enables reinforcement learning (RL) to perform long-horizon robot control problems by distilling behaviors from auxiliary RL tasks. AuxDistill achieves this by concurrently carrying out multi-task RL with auxiliary tasks, which are easier to learn and relevant to the main task. A weighted distillation loss transfers behaviors from these auxiliary tasks to solve the main task. We demonstrate that AuxDistill can learn a pixels-to-actions policy for a challenging multi-stage embodied object rearrangement task from the environment reward without demonstrations, a learning curriculum, or pre-trained skills. AuxDistill achieves $2.3 \times$ higher success than the previous state-of-the-art baseline in the Habitat Object Rearrangement benchmark and outperforms methods that use pre-trained skills and expert demonstrations.
Pretraining Decision Transformers with Reward Prediction for In-Context Multi-task Structured Bandit Learning
Jun 07, 2024



In this paper, we study multi-task structured bandit problem where the goal is to learn a near-optimal algorithm that minimizes cumulative regret. The tasks share a common structure and the algorithm exploits the shared structure to minimize the cumulative regret for an unseen but related test task. We use a transformer as a decision-making algorithm to learn this shared structure so as to generalize to the test task. The prior work of pretrained decision transformers like DPT requires access to the optimal action during training which may be hard in several scenarios. Diverging from these works, our learning algorithm does not need the knowledge of optimal action per task during training but predicts a reward vector for each of the actions using only the observed offline data from the diverse training tasks. Finally, during inference time, it selects action using the reward predictions employing various exploration strategies in-context for an unseen test task. Our model outperforms other SOTA methods like DPT, and Algorithmic Distillation over a series of experiments on several structured bandit problems (linear, bilinear, latent, non-linear). Interestingly, we show that our algorithm, without the knowledge of the underlying problem structure, can learn a near-optimal policy in-context by leveraging the shared structure across diverse tasks. We further extend the field of pre-trained decision transformers by showing that they can leverage unseen tasks with new actions and still learn the underlying latent structure to derive a near-optimal policy. We validate this over several experiments to show that our proposed solution is very general and has wide applications to potentially emergent online and offline strategies at test time. Finally, we theoretically analyze the performance of our algorithm and obtain generalization bounds in the in-context multi-task learning setting.
SaVeR: Optimal Data Collection Strategy for Safe Policy Evaluation in Tabular MDP
Jun 04, 2024



In this paper, we study safe data collection for the purpose of policy evaluation in tabular Markov decision processes (MDPs). In policy evaluation, we are given a \textit{target} policy and asked to estimate the expected cumulative reward it will obtain. Policy evaluation requires data and we are interested in the question of what \textit{behavior} policy should collect the data for the most accurate evaluation of the target policy. While prior work has considered behavior policy selection, in this paper, we additionally consider a safety constraint on the behavior policy. Namely, we assume there exists a known default policy that incurs a particular expected cost when run and we enforce that the cumulative cost of all behavior policies ran is better than a constant factor of the cost that would be incurred had we always run the default policy. We first show that there exists a class of intractable MDPs where no safe oracle algorithm with knowledge about problem parameters can efficiently collect data and satisfy the safety constraints. We then define the tractability condition for an MDP such that a safe oracle algorithm can efficiently collect data and using that we prove the first lower bound for this setting. We then introduce an algorithm SaVeR for this problem that approximates the safe oracle algorithm and bound the finite-sample mean squared error of the algorithm while ensuring it satisfies the safety constraint. Finally, we show in simulations that SaVeR produces low MSE policy evaluation while satisfying the safety constraint.
Adaptive Exploration for Data-Efficient General Value Function Evaluations
May 13, 2024General Value Functions (GVFs) (Sutton et al, 2011) are an established way to represent predictive knowledge in reinforcement learning. Each GVF computes the expected return for a given policy, based on a unique pseudo-reward. Multiple GVFs can be estimated in parallel using off-policy learning from a single stream of data, often sourced from a fixed behavior policy or pre-collected dataset. This leaves an open question: how can behavior policy be chosen for data-efficient GVF learning? To address this gap, we propose GVFExplorer, which aims at learning a behavior policy that efficiently gathers data for evaluating multiple GVFs in parallel. This behavior policy selects actions in proportion to the total variance in the return across all GVFs, reducing the number of environmental interactions. To enable accurate variance estimation, we use a recently proposed temporal-difference-style variance estimator. We prove that each behavior policy update reduces the mean squared error in the summed predictions over all GVFs. We empirically demonstrate our method's performance in both tabular representations and nonlinear function approximation.