 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Offline Value Function Learning with Bisimulation-based Representations
Oct 02, 2024



In reinforcement learning, offline value function learning is the procedure of using an offline dataset to estimate the expected discounted return from each state when taking actions according to a fixed target policy. The stability of this procedure, i.e., whether it converges to its fixed-point, critically depends on the representations of the state-action pairs. Poorly learned representations can make value function learning unstable, or even divergent. Therefore, it is critical to stabilize value function learning by explicitly shaping the state-action representations. Recently, the class of bisimulation-based algorithms have shown promise in shaping representations for control. However, it is still unclear if this class of methods can stabilize value function learning. In this work, we investigate this question and answer it affirmatively. We introduce a bisimulation-based algorithm called kernel representations for offline policy evaluation (KROPE). KROPE uses a kernel to shape state-action representations such that state-action pairs that have similar immediate rewards and lead to similar next state-action pairs under the target policy also have similar representations. We show that KROPE: 1) learns stable representations and 2) leads to lower value error than baselines. Our analysis provides new theoretical insight into the stability properties of bisimulation-based methods and suggests that practitioners can use these methods for stable and accurate evaluation of offline reinforcement learning agents.
State-Action Similarity-Based Representations for Off-Policy Evaluation
Oct 27, 2023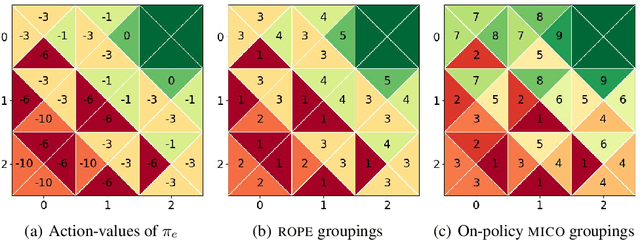
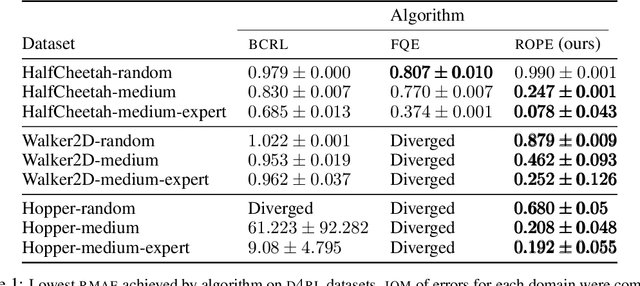
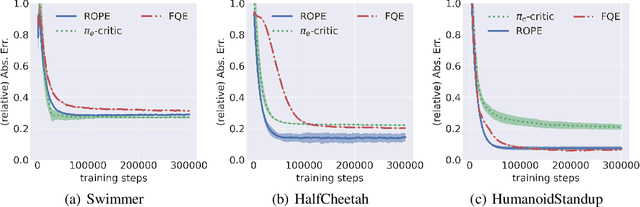
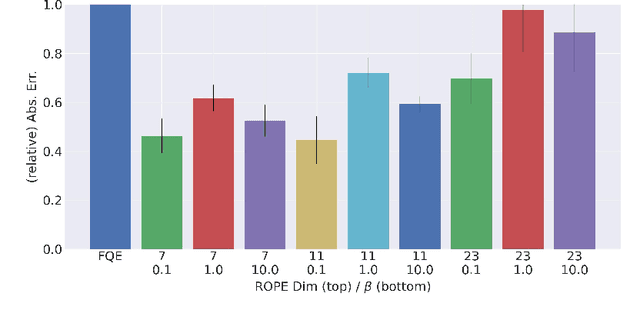
In reinforcement learning, off-policy evaluation (OPE) is the problem of estimating the expected return of an evaluation policy given a fixed dataset that was collected by running one or more different policies. One of the more empirically successful algorithms for OPE has been the fitted q-evaluation (FQE) algorithm that uses temporal difference updates to learn an action-value function, which is then used to estimate the expected return of the evaluation policy. Typically, the original fixed dataset is fed directly into FQE to learn the action-value function of the evaluation policy. Instead, in this paper, we seek to enhance the data-efficiency of FQE by first transforming the fixed dataset using a learned encoder, and then feeding the transformed dataset into FQE. To learn such an encoder, we introduce an OPE-tailored state-action behavioral similarity metric, and use this metric and the fixed dataset to learn an encoder that models this metric. Theoretically, we show that this metric allows us to bound the error in the resulting OPE estimate. Empirically, we show that other state-action similarity metrics lead to representations that cannot represent the action-value function of the evaluation policy, and that our state-action representation method boosts the data-efficiency of FQE and lowers OPE error relative to other OPE-based representation learning methods on challenging OPE tasks. We also empirically show that the learned representations significantly mitigate divergence of FQE under varying distribution shifts. Our code is available here: https://github.com/Badger-RL/ROPE.
Tackling Unbounded State Spaces in Continuing Task Reinforcement Learning
Jun 02, 2023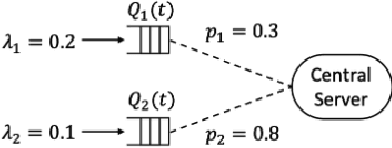
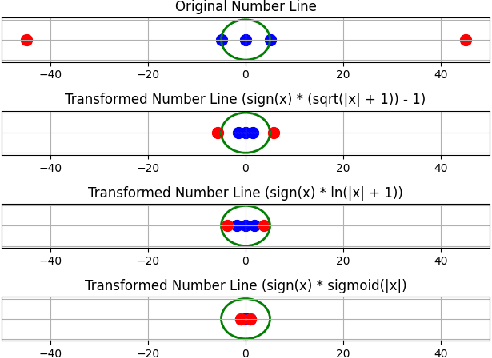
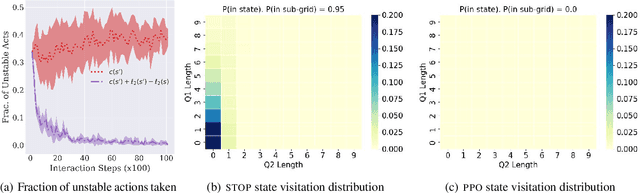
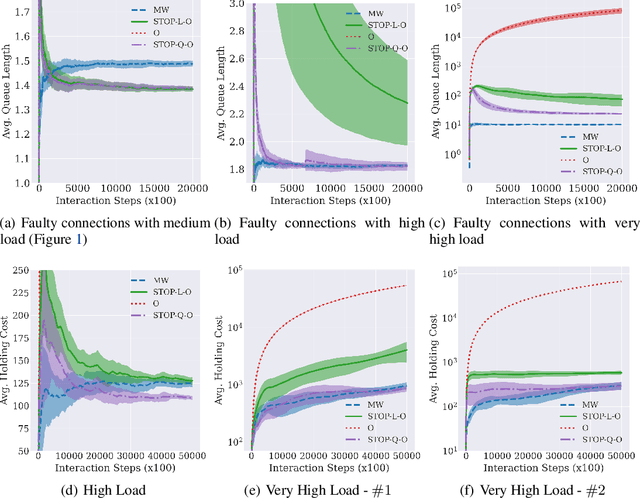
While deep reinforcement learning (RL) algorithms have been successfully applied to many tasks, their inability to extrapolate and strong reliance on episodic resets inhibits their applicability to many real-world settings. For instance, in stochastic queueing problems, the state space can be unbounded and the agent may have to learn online without the system ever being reset to states the agent has seen before. In such settings, we show that deep RL agents can diverge into unseen states from which they can never recover due to the lack of resets, especially in highly stochastic environments. Towards overcoming this divergence, we introduce a Lyapunov-inspired reward shaping approach that encourages the agent to first learn to be stable (i.e. to achieve bounded cost) and then to learn to be optimal. We theoretically show that our reward shaping technique reduces the rate of divergence of the agent and empirically find that it prevents it. We further combine our reward shaping approach with a weight annealing scheme that gradually introduces optimality and log-transform of state inputs, and find that these techniques enable deep RL algorithms to learn high performing policies when learning online in unbounded state space domains.
Scaling Marginalized Importance Sampling to High-Dimensional State-Spaces via State Abstraction
Dec 14, 2022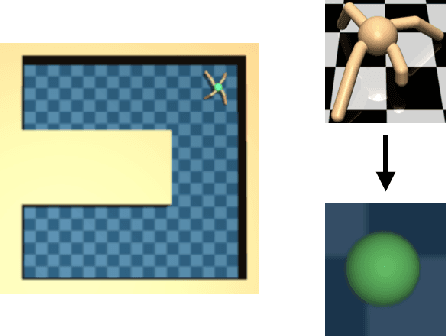
We consider the problem of off-policy evaluation (OPE) in reinforcement learning (RL), where the goal is to estimate the performance of an evaluation policy, $\pi_e$, using a fixed dataset, $\mathcal{D}$, collected by one or more policies that may be different from $\pi_e$. Current OPE algorithms may produce poor OPE estimates under policy distribution shift i.e., when the probability of a particular state-action pair occurring under $\pi_e$ is very different from the probability of that same pair occurring in $\mathcal{D}$ (Voloshin et al. 2021, Fu et al. 2021). In this work, we propose to improve the accuracy of OPE estimators by projecting the high-dimensional state-space into a low-dimensional state-space using concepts from the state abstraction literature. Specifically, we consider marginalized importance sampling (MIS) OPE algorithms which compute state-action distribution correction ratios to produce their OPE estimate. In the original ground state-space, these ratios may have high variance which may lead to high variance OPE. However, we prove that in the lower-dimensional abstract state-space the ratios can have lower variance resulting in lower variance OPE. We then highlight the challenges that arise when estimating the abstract ratios from data, identify sufficient conditions to overcome these issues, and present a minimax optimization problem whose solution yields these abstract ratios. Finally, our empirical evaluation on difficult, high-dimensional state-space OPE tasks shows that the abstract ratios can make MIS OPE estimators achieve lower mean-squared error and more robust to hyperparameter tuning than the ground ratios.
RIDM: Reinforced Inverse Dynamics Modeling for Learning from a Single Observed Demonstration
Jul 01, 2019
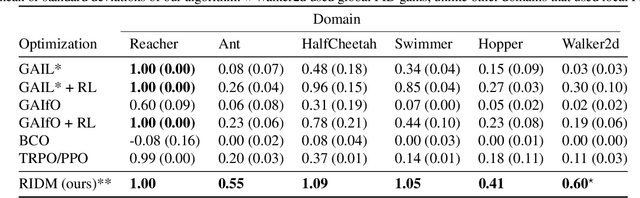

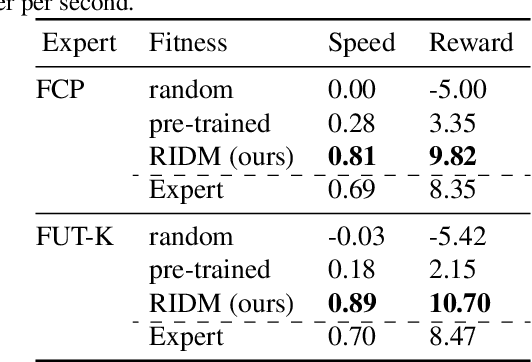
Imitation learning has long been an approach to alleviate the tractability issues that arise in reinforcement learning. However, most literature makes several assumptions such as access to the expert's actions, availability of many expert demonstrations, and injection of task-specific domain knowledge into the learning process. We propose reinforced inverse dynamics modeling (RIDM), a method of combining reinforcement learning and imitation from observation (IfO) to perform imitation using a single expert demonstration, with no access to the expert's actions, and with little task-specific domain knowledge. Given only a single set of the expert's raw states, such as joint angles in a robot control task, at each time-step, we learn an inverse dynamics model to produce the necessary low-level actions, such as torques, to transition from one state to the next such that the reward from the environment is maximized. We demonstrate that RIDM outperforms other techniques when we apply the same constraints on the other methods on six domains of the MuJoCo simulator and for two different robot soccer tasks for two experts from the RoboCup 3D simulation league on the SimSpark simulator.