 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEV-Patch-PF: Particle Filtering with BEV-Aerial Feature Matching for Off-Road Geo-Localization
Dec 17, 2025We propose BEV-Patch-PF, a GPS-free sequential geo-localization system that integrates a particle filter with learned bird's-eye-view (BEV) and aerial feature maps. From onboard RGB and depth images, we construct a BEV feature map. For each 3-DoF particle pose hypothesis, we crop the corresponding patch from an aerial feature map computed from a local aerial image queried around the approximate location. BEV-Patch-PF computes a per-particle log-likelihood by matching the BEV feature to the aerial patch feature. On two real-world off-road datasets, our method achieves 7.5x lower absolute trajectory error (ATE) on seen routes and 7.0x lower ATE on unseen routes than a retrieval-based baseline, while maintaining accuracy under dense canopy and shadow. The system runs in real time at 10 Hz on an NVIDIA Tesla T4, enabling practical robot deployment.
SocialNav-SUB: Benchmarking VLMs for Scene Understanding in Social Robot Navigation
Sep 10, 2025Robot navigation in dynamic, human-centered environments requires socially-compliant decisions grounded in robust scene understanding. Recent Vision-Language Models (VLMs) exhibit promising capabilities such as object recognition, common-sense reasoning, and contextual understanding-capabilities that align with the nuanced requirements of social robot navigation. However, it remains unclear whether VLMs can accurately understand complex social navigation scenes (e.g., inferring the spatial-temporal relations among agents and human intentions), which is essential for safe and socially compliant robot navigation. While some recent works have explored the use of VLMs in social robot navigation, no existing work systematically evaluates their ability to meet these necessary conditions. In this paper, we introduce the Social Navigation Scene Understanding Benchmark (SocialNav-SUB), a Visual Question Answering (VQA) dataset and benchmark designed to evaluate VLMs for scene understanding in real-world social robot navigation scenarios. SocialNav-SUB provides a unified framework for evaluating VLMs against human and rule-based baselines across VQA tasks requiring spatial, spatiotemporal, and social reasoning in social robot navigation. Through experiments with state-of-the-art VLMs, we find that while the best-performing VLM achieves an encouraging probability of agreeing with human answers, it still underperforms simpler rule-based approach and human consensus baselines, indicating critical gaps in social scene understanding of current VLMs. Our benchmark sets the stage for further research on foundation models for social robot navigation, offering a framework to explore how VLMs can be tailored to meet real-world social robot navigation needs. An overview of this paper along with the code and data can be found at https://larg.github.io/socialnav-sub .
PACER: Preference-conditioned All-terrain Costmap Generation
Oct 30, 2024



In autonomous robot navigation, terrain cost assignment is typically performed using a semantics-based paradigm in which terrain is first labeled using a pre-trained semantic classifier and costs are then assigned according to a user-defined mapping between label and cost. While this approach is rapidly adaptable to changing user preferences, only preferences over the types of terrain that are already known by the semantic classifier can be expressed. In this paper, we hypothesize that a machine-learning-based alternative to the semantics-based paradigm above will allow for rapid cost assignment adaptation to preferences expressed over new terrains at deployment time without the need for additional training. To investigate this hypothesis, we introduce and study PACER, a novel approach to costmap generation that accepts as input a single birds-eye view (BEV) image of the surrounding area along with a user-specified preference context and generates a corresponding BEV costmap that aligns with the preference context. Using both real and synthetic data along with a combination of proposed training tasks, we find that PACER is able to adapt quickly to new user preferences while also exhibiting better generalization to novel terrains compared to both semantics-based and representation-learning approaches.
VertiEncoder: Self-Supervised Kinodynamic Representation Learning on Vertically Challenging Terrain
Sep 17, 2024



We present VertiEncoder, a self-supervised representation learning approach for robot mobility on vertically challenging terrain. Using the same pre-training process, VertiEncoder can handle four different downstream tasks, including forward kinodynamics learning, inverse kinodynamics learning, behavior cloning, and patch reconstruction with a single representation. VertiEncoder uses a TransformerEncoder to learn the local context of its surroundings by random masking and next patch reconstruction. We show that VertiEncoder achieves better performance across all four different tasks compared to specialized End-to-End models with 77% fewer parameters. We also show VertiEncoder's comparable performance against state-of-the-art kinodynamic modeling and planning approaches in real-world robot deployment. These results underscore the efficacy of VertiEncoder in mitigating overfitting and fostering more robust generalization across diverse environmental contexts and downstream vehicle kinodynamic tasks.
Self-Supervised Terrain Representation Learning from Unconstrained Robot Experience
Sep 26, 2023Terrain awareness, i.e., the ability to identify and distinguish different types of terrain, is a critical ability that robots must have to succeed at autonomous off-road navigation. Current approaches that provide robots with this awareness either rely on labeled data which is expensive to collect, engineered features and cost functions that may not generalize, or expert human demonstrations which may not be available. Towards endowing robots with terrain awareness without these limitations, we introduce Self-supervised TErrain Representation LearnING (STERLING), a novel approach for learning terrain representations that relies solely on easy-to-collect, unconstrained (e.g., non-expert), and unlabelled robot experience, with no additional constraints on data collection. STERLING employs a novel multi-modal self-supervision objective through non-contrastive representation learning to learn relevant terrain representations for terrain-aware navigation. Through physical robot experiments in off-road environments, we evaluate STERLING features on the task of preference-aligned visual navigation and find that STERLING features perform on par with fully supervised approaches and outperform other state-of-the-art methods with respect to preference alignment. Additionally, we perform a large-scale experiment of autonomously hiking a 3-mile long trail which STERLING completes successfully with only two manual interventions, demonstrating its robustness to real-world off-road conditions.
Wait, That Feels Familiar: Learning to Extrapolate Human Preferences for Preference Aligned Path Planning
Sep 18, 2023Autonomous mobility tasks such as lastmile delivery require reasoning about operator indicated preferences over terrains on which the robot should navigate to ensure both robot safety and mission success. However, coping with out of distribution data from novel terrains or appearance changes due to lighting variations remains a fundamental problem in visual terrain adaptive navigation. Existing solutions either require labor intensive manual data recollection and labeling or use handcoded reward functions that may not align with operator preferences. In this work, we posit that operator preferences for visually novel terrains, which the robot should adhere to, can often be extrapolated from established terrain references within the inertial, proprioceptive, and tactile domain. Leveraging this insight, we introduce Preference extrApolation for Terrain awarE Robot Navigation, PATERN, a novel framework for extrapolating operator terrain preferences for visual navigation. PATERN learns to map inertial, proprioceptive, tactile measurements from the robots observations to a representation space and performs nearest neighbor search in this space to estimate operator preferences over novel terrains. Through physical robot experiments in outdoor environments, we assess PATERNs capability to extrapolate preferences and generalize to novel terrains and challenging lighting conditions. Compared to baseline approaches, our findings indicate that PATERN robustly generalizes to diverse terrains and varied lighting conditions, while navigating in a preference aligned manner.
Autonomous Ground Navigation in Highly Constrained Spaces: Lessons learned from The 2nd BARN Challenge at ICRA 2023
Aug 06, 2023The 2nd BARN (Benchmark Autonomous Robot Navigation) Challenge took place at the 2023 IEEE International Conference on Robotics and Automation (ICRA 2023) in London, UK and continued to evaluate the performance of state-of-the-art autonomous ground navigation systems in highly constrained environments. Compared to The 1st BARN Challenge at ICRA 2022 in Philadelphia, the competition has grown significantly in size, doubling the numbers of participants in both the simulation qualifier and physical finals: Ten teams from all over the world participated in the qualifying simulation competition, six of which were invited to compete with each other in three physical obstacle courses at the conference center in London, and three teams won the challenge by navigating a Clearpath Jackal robot from a predefined start to a goal with the shortest amount of time without colliding with any obstacle. The competition results, compared to last year, suggest that the teams are making progress toward more robust and efficient ground navigation systems that work out-of-the-box in many obstacle environments. However, a significant amount of fine-tuning is still needed onsite to cater to different difficult navigation scenarios. Furthermore, challenges still remain for many teams when facing extremely cluttered obstacles and increasing navigation speed. In this article, we discuss the challenge, the approaches used by the three winning teams, and lessons learned to direct future research.
ABC: Adversarial Behavioral Cloning for Offline Mode-Seeking Imitation Learning
Nov 08, 2022Given a dataset of expert agent interactions with an environment of interest, a viable method to extract an effective agent policy is to estimate the maximum likelihood policy indicated by this data. This approach is commonly referred to as behavioral cloning (BC). In this work, we describe a key disadvantage of BC that arises due to the maximum likelihood objective function; namely that BC is mean-seeking with respect to the state-conditional expert action distribution when the learner's policy is represented with a Gaussian. To address this issue, we introduce a modified version of BC, Adversarial Behavioral Cloning (ABC), that exhibits mode-seeking behavior by incorporating elements of GAN (generative adversarial network) training. We evaluate ABC on toy domains and a domain based on Hopper from the DeepMind Control suite, and show that it outperforms standard BC by being mode-seeking in nature.
D-Shape: Demonstration-Shaped Reinforcement Learning via Goal Conditioning
Oct 26, 2022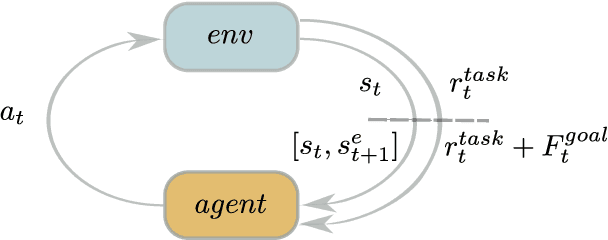
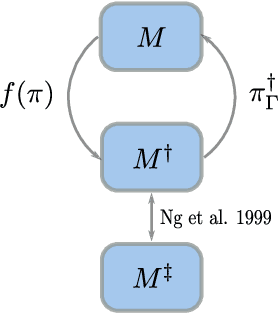
While combining imitation learning (IL) and reinforcement learning (RL) is a promising way to address poor sample efficiency in autonomous behavior acquisition, methods that do so typically assume that the requisite behavior demonstrations are provided by an expert that behaves optimally with respect to a task reward. If, however, suboptimal demonstrations are provided, a fundamental challenge appears in that the demonstration-matching objective of IL conflicts with the return-maximization objective of RL. This paper introduces D-Shape, a new method for combining IL and RL that uses ideas from reward shaping and goal-conditioned RL to resolve the above conflict. D-Shape allows learning from suboptimal demonstrations while retaining the ability to find the optimal policy with respect to the task reward. We experimentally validate D-Shape in sparse-reward gridworld domains, showing that it both improves over RL in terms of sample efficiency and converges consistently to the optimal policy in the presence of suboptimal demonstrations.
Learning Perceptual Hallucination for Multi-Robot Navigation in Narrow Hallways
Sep 27, 2022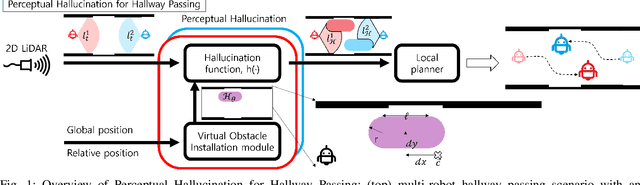
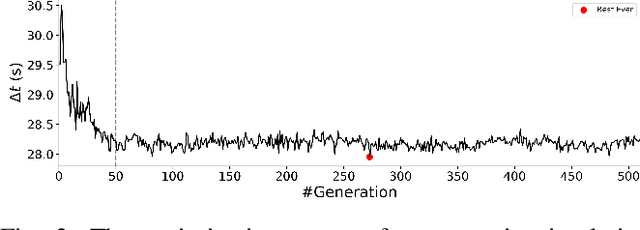
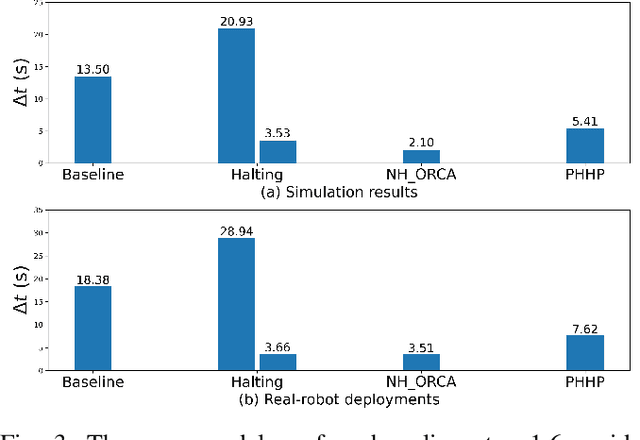
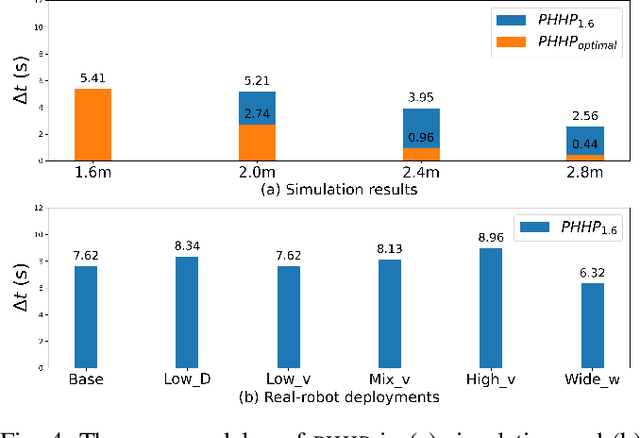
While current systems for autonomous robot navigation can produce safe and efficient motion plans in static environments, they usually generate suboptimal behaviors when multiple robots must navigate together in confined spaces. For example, when two robots meet each other in a narrow hallway, they may either turn around to find an alternative route or collide with each other. This paper presents a new approach to navigation that allows two robots to pass each other in a narrow hallway without colliding, stopping, or waiting. Our approach, Perceptual Hallucination for Hallway Passing (PHHP), learns to synthetically generate virtual obstacles (i.e., perceptual hallucination) to facilitate passing in narrow hallways by multiple robots that utilize otherwise standard autonomous navigation systems. Our experiments on physical robots in a variety of hallways show improved performance compared to multiple baselines.