 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrospective Perception for Mobile Robots
Jun 29, 2023Perception algorithms that provide estimates of their uncertainty are crucial to the development of autonomous robots that can operate in challenging and uncontrolled environments. Such perception algorithms provide the means for having risk-aware robots that reason about the probability of successfully completing a task when planning. There exist perception algorithms that come with models of their uncertainty; however, these models are often developed with assumptions, such as perfect data associations, that do not hold in the real world. Hence the resultant estimated uncertainty is a weak lower bound. To tackle this problem we present introspective perception - a novel approach for predicting accurate estimates of the uncertainty of perception algorithms deployed on mobile robots. By exploiting sensing redundancy and consistency constraints naturally present in the data collected by a mobile robot, introspective perception learns an empirical model of the error distribution of perception algorithms in the deployment environment and in an autonomously supervised manner. In this paper, we present the general theory of introspective perception and demonstrate successful implementations for two different perception tasks. We provide empirical results on challenging real-robot data for introspective stereo depth estimation and introspective visual simultaneous localization and mapping and show that they learn to predict their uncertainty with high accuracy and leverage this information to significantly reduce state estimation errors for an autonomous mobile robot.
High-Speed Accurate Robot Control using Learned Forward Kinodynamics and Non-linear Least Squares Optimization
Jun 16, 2022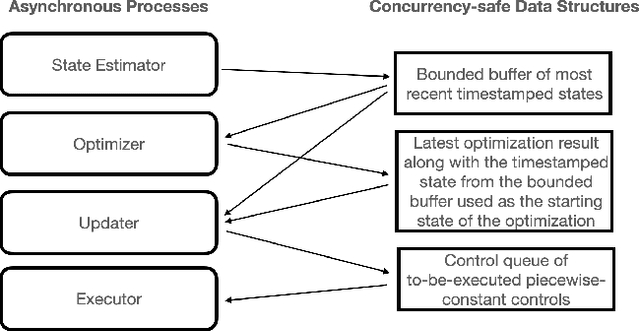
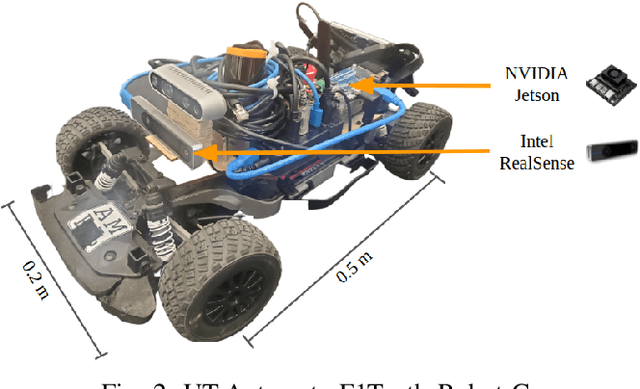
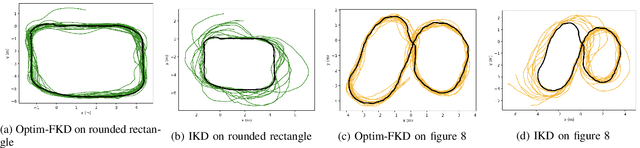
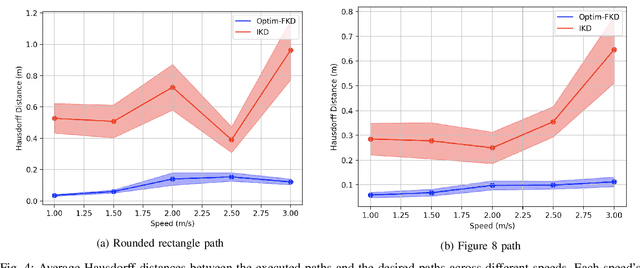
Accurate control of robots in the real world requires a control system that is capable of taking into account the kinodynamic interactions of the robot with its environment. At high speeds, the dependence of the movement of the robot on these kinodynamic interactions becomes more pronounced, making high-speed, accurate robot control a challenging problem. Previous work has shown that learning the inverse kinodynamics (IKD) of the robot can be helpful for high-speed robot control. However a learned inverse kinodynamic model can only be applied to a limited class of control problems, and different control problems require the learning of a new IKD model. In this work we present a new formulation for accurate, high-speed robot control that makes use of a learned forward kinodynamic (FKD) model and non-linear least squares optimization. By nature of the formulation, this approach is extensible to a wide array of control problems without requiring the retraining of a new model. We demonstrate the ability of this approach to accurately control a scale one-tenth robot car at high speeds, and show improved results over baselines.
VI-IKD: High-Speed Accurate Off-Road Navigation using Learned Visual-Inertial Inverse Kinodynamics
Mar 30, 2022
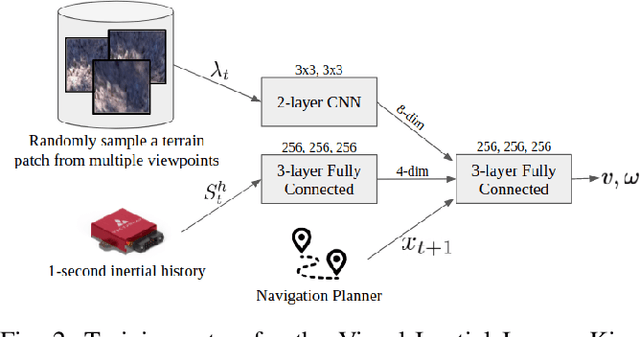


One of the key challenges in high speed off road navigation on ground vehicles is that the kinodynamics of the vehicle terrain interaction can differ dramatically depending on the terrain. Previous approaches to addressing this challenge have considered learning an inverse kinodynamics (IKD) model, conditioned on inertial information of the vehicle to sense the kinodynamic interactions. In this paper, we hypothesize that to enable accurate high-speed off-road navigation using a learned IKD model, in addition to inertial information from the past, one must also anticipate the kinodynamic interactions of the vehicle with the terrain in the future. To this end, we introduce Visual-Inertial Inverse Kinodynamics (VI-IKD), a novel learning based IKD model that is conditioned on visual information from a terrain patch ahead of the robot in addition to past inertial information, enabling it to anticipate kinodynamic interactions in the future. We validate the effectiveness of VI-IKD in accurate high-speed off-road navigation experimentally on a scale 1/5 UT-AlphaTruck off-road autonomous vehicle in both indoor and outdoor environments and show that compared to other state-of-the-art approaches, VI-IKD enables more accurate and robust off-road navigation on a variety of different terrains at speeds of up to 3.5 m/s.
Competence-Aware Path Planning via Introspective Perception
Sep 28, 2021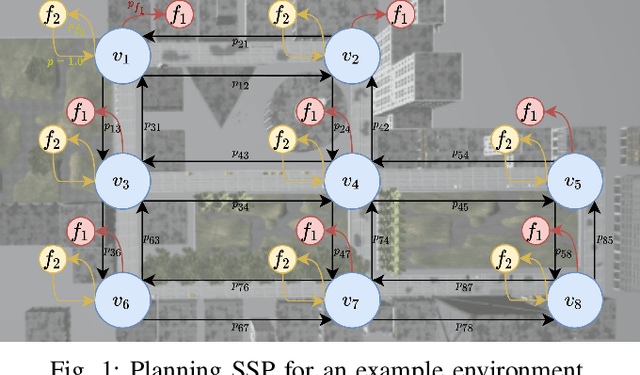
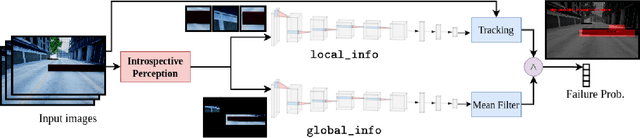

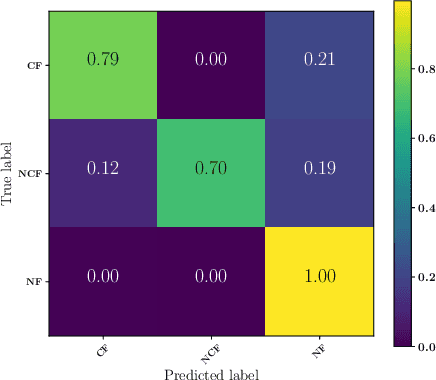
Robots deployed in the real world over extended periods of time need to reason about unexpected failures, learn to predict them, and to proactively take actions to avoid future failures. Existing approaches for competence-aware planning are either model-based, requiring explicit enumeration of known failure modes, or purely statistical, using state- and location-specific failure statistics to infer competence. We instead propose a structured model-free approach to competence-aware planning by reasoning about plan execution failures due to errors in perception, without requiring a-priori enumeration of failure modes or requiring location-specific failure statistics. We introduce competence-aware path planning via introspective perception (CPIP), a Bayesian framework to iteratively learn and exploit task-level competence in novel deployment environments. CPIP factorizes the competence-aware planning problem into two components. First, perception errors are learned in a model-free and location-agnostic setting via introspective perception prior to deployment in novel environments. Second, during actual deployments, the prediction of task-level failures is learned in a context-aware setting. Experiments in a simulation show that the proposed CPIP approach outperforms the frequentist baseline in multiple mobile robot tasks, and is further validated via real robot experiments in an environment with perceptually challenging obstacles and terrain.
Visual Representation Learning for Preference-Aware Path Planning
Sep 18, 2021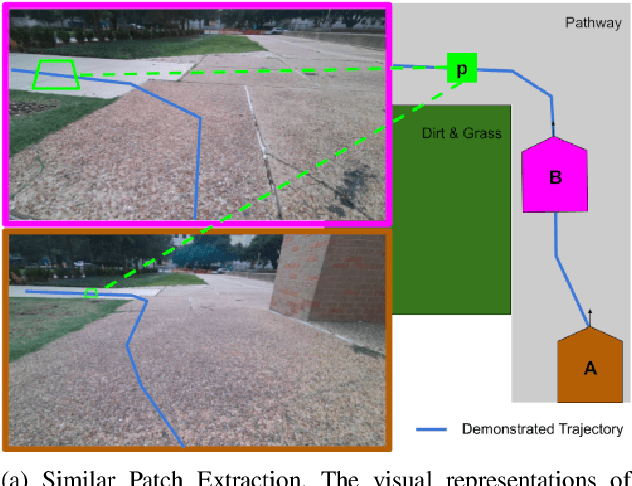

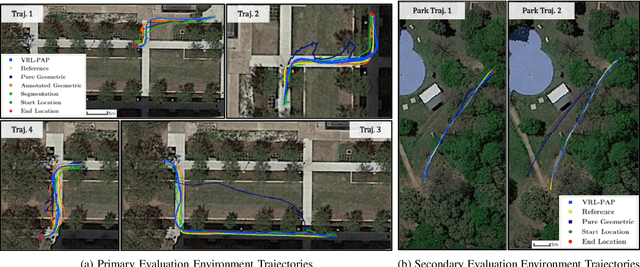
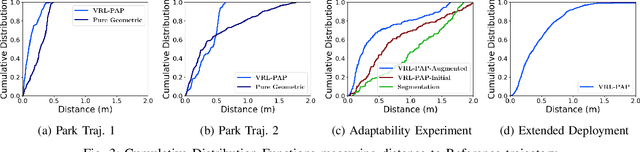
Autonomous mobile robots deployed in outdoor environments must reason about different types of terrain for both safety (e.g., prefer dirt over mud) and deployer preferences (e.g., prefer dirt path over flower beds). Most existing solutions to this preference-aware path planning problem use semantic segmentation to classify terrain types from camera images, and then ascribe costs to each type. Unfortunately, there are three key limitations of such approaches -- they 1) require pre-enumeration of the discrete terrain types, 2) are unable to handle hybrid terrain types (e.g., grassy dirt), and 3) require expensive labelled data to train visual semantic segmentation. We introduce Visual Representation Learning for Preference-Aware Path Planning (VRL-PAP), an alternative approach that overcomes all three limitations: VRL-PAP leverages unlabeled human demonstrations of navigation to autonomously generate triplets for learning visual representations of terrain that are viewpoint invariant and encode terrain types in a continuous representation space. The learned representations are then used along with the same unlabeled human navigation demonstrations to learn a mapping from the representation space to terrain costs. At run time, VRL-PAP maps from images to representations and then representations to costs to perform preference-aware path planning. We present empirical results from challenging outdoor settings that demonstrate VRL-PAP 1) is successfully able to pick paths that reflect demonstrated preferences, 2) is comparable in execution to geometric navigation with a highly detailed manually annotated map (without requiring such annotations), 3) is able to generalize to novel terrain types with minimal additional unlabeled demonstrations.
Robofleet: Secure Open Source Communication and Management for Fleets of Autonomous Robots
Mar 11, 2021
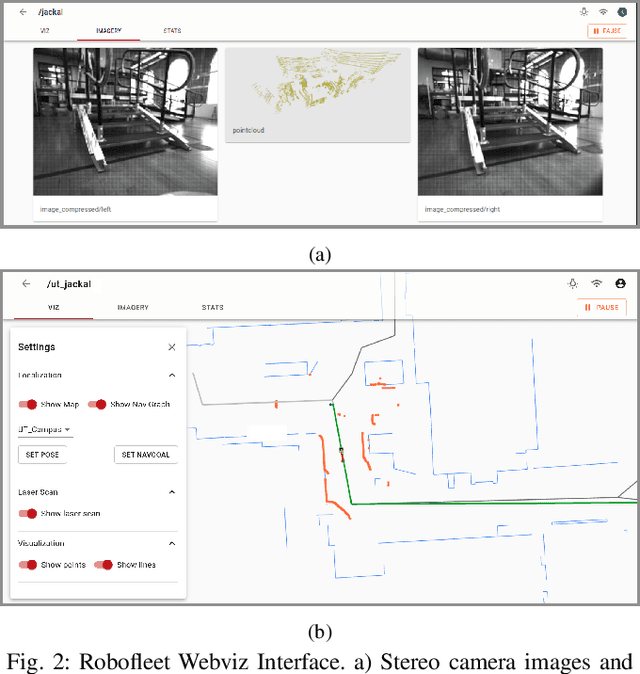
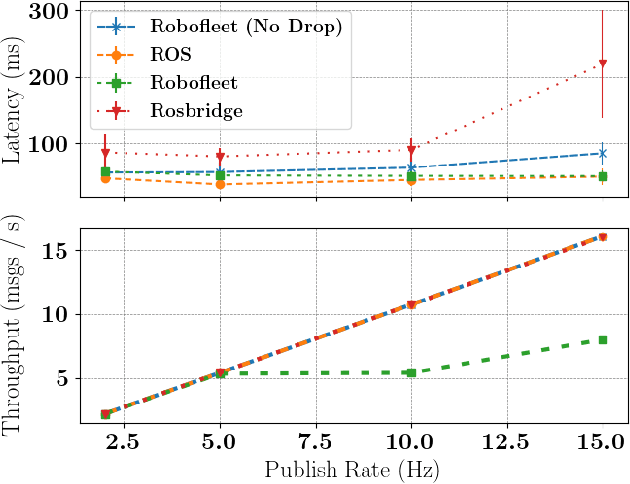
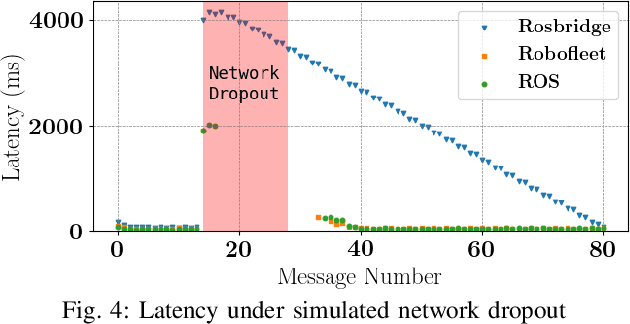
Safe long-term deployment of a fleet of mobile robots requires reliable and secure two-way communication channels between individual robots and remote human operators for supervision and tasking. Existing open-source solutions to this problem degrade in performance in challenging real-world situations such as intermittent and low-bandwidth connectivity, do not provide security control options, and can be computationally expensive on hardware-constrained mobile robot platforms. In this paper, we present Robofleet, a lightweight open-source system which provides inter-robot communication, remote monitoring, and remote tasking for a fleet of ROS-enabled service-mobile robots that is designed with the practical goals of resilience to network variance and security control in mind. Robofleet supports multi-user, multi-robot communication via a central server. This architecture deduplicates network traffic between robots, significantly reducing overall network load when compared with native ROS communication. This server also functions as a single entrypoint into the system, enabling security control and user authentication. Individual robots run the lightweight Robofleet client, which is responsible for exchanging messages with the Robofleet server. It automatically adapts to adverse network conditions through backpressure monitoring as well as topic-level priority control, ensuring that safety-critical messages are successfully transmitted. Finally, the system includes a web-based visualization tool that can be run on any internet-connected, browser-enabled device to monitor and control the fleet. We compare Robofleet to existing methods of robotic communication, and demonstrate that it provides superior resilience to network variance while maintaining performance that exceeds that of widely-used systems.
IV-SLAM: Introspective Vision for Simultaneous Localization and Mapping
Aug 06, 2020

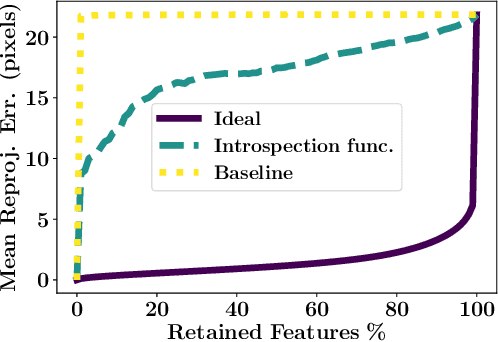
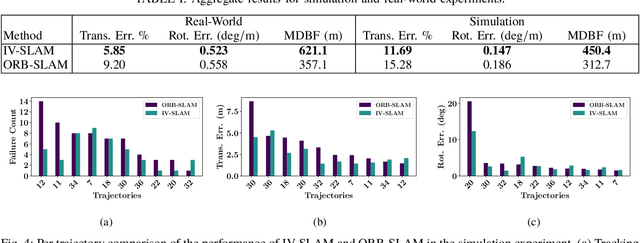
Existing solutions to visual simultaneous localization and mapping (V-SLAM) assume that errors in feature extraction and matching are independent and identically distributed (i.i.d), but this assumption is known to not be true -- features extracted from low-contrast regions of images exhibit wider error distributions than features from sharp corners. Furthermore, V-SLAM algorithms are prone to catastrophic tracking failures when sensed images include challenging conditions such as specular reflections, lens flare, or shadows of dynamic objects. To address such failures, previous work has focused on building more robust visual frontends, to filter out challenging features. In this paper, we present introspective vision for SLAM (IV-SLAM), a fundamentally different approach for addressing these challenges. IV-SLAM explicitly models the noise process of reprojection errors from visual features to be context-dependent, and hence non-i.i.d. We introduce an autonomously supervised approach for IV-SLAM to collect training data to learn such a context-aware noise model. Using this learned noise model, IV-SLAM guides feature extraction to select more features from parts of the image that are likely to result in lower noise, and further incorporate the learned noise model into the joint maximum likelihood estimation, thus making it robust to the aforementioned types of errors. We present empirical results to demonstrate that IV-SLAM 1) is able to accurately predict sources of error in input images, 2) reduces tracking error compared to V-SLAM, and 3) increases the mean distance between tracking failures by more than 70% on challenging real robot data compared to V-SLAM.
iVOA: Introspective Vision for Obstacle Avoidance
Mar 04, 2019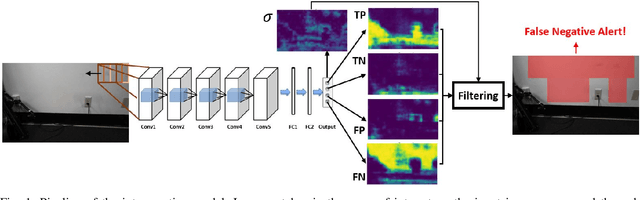

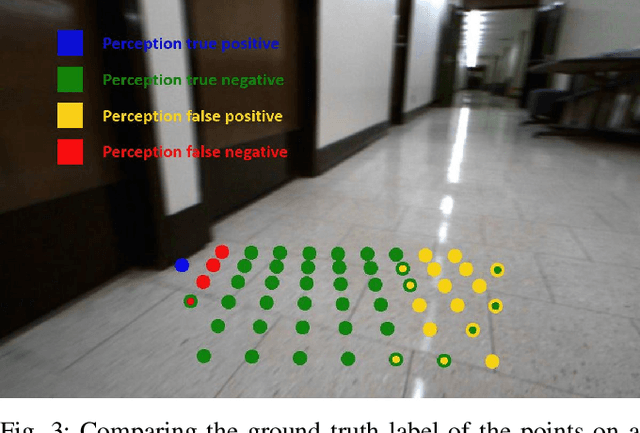
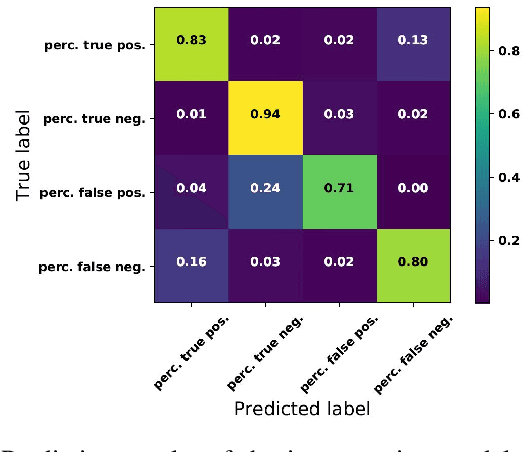
Vision, as an inexpensive yet information rich sensor, is commonly used for perception on autonomous mobile robots. Unfortunately, accurate vision-based perception requires a number of assumptions about the environment to hold -- some examples of such assumptions, depending on the perception algorithm at hand, include purely lambertian surfaces, texture-rich scenes, absence of aliasing features, and refractive surfaces. In this paper, we present an approach for introspective vision for obstacle avoidance (iVOA) -- by leveraging a supervisory sensor that is occasionally available, we detect failures of stereo vision-based perception from divergence in plans generated by vision and the supervisory sensor. By projecting the 3D coordinates where the plans agree and disagree onto the images used for vision-based perception, iVOA generates a training set of reliable and unreliable image patches for perception. We then use this training dataset to learn a model of which image patches are likely to cause failures of the vision-based perception algorithm. Using this model, iVOA is then able to predict whether the relevant image patches in the observed images are likely to cause failures due to vision (both false positives and false negatives). We empirically demonstrate with extensive real-world data from both indoor and outdoor environments, the ability of iVOA to accurately predict the failures of two distinct vision algorithms.