 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Representation Learning for Preference-Aware Path Planning
Paper and Code
Sep 18, 2021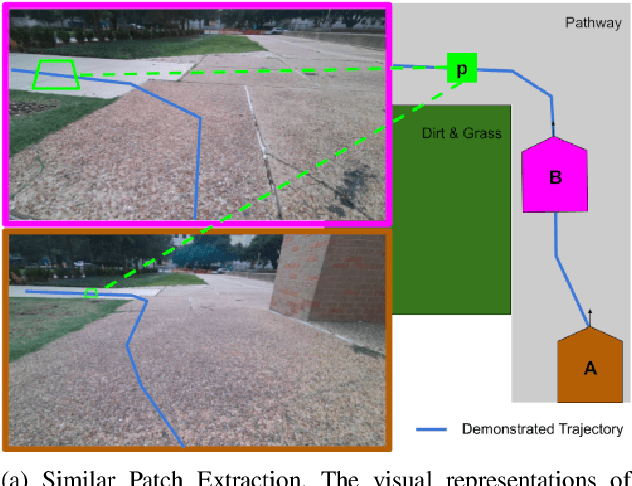

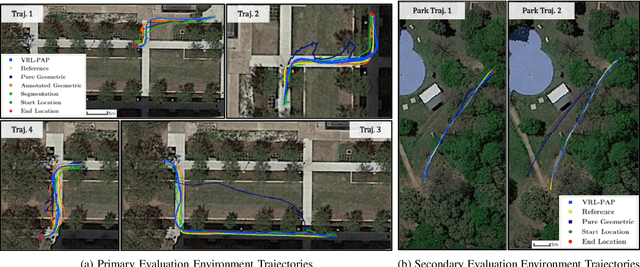
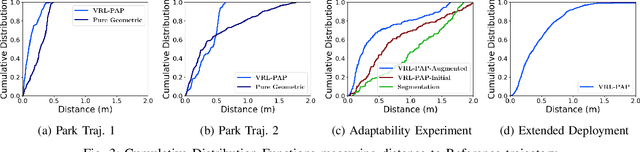
Autonomous mobile robots deployed in outdoor environments must reason about different types of terrain for both safety (e.g., prefer dirt over mud) and deployer preferences (e.g., prefer dirt path over flower beds). Most existing solutions to this preference-aware path planning problem use semantic segmentation to classify terrain types from camera images, and then ascribe costs to each type. Unfortunately, there are three key limitations of such approaches -- they 1) require pre-enumeration of the discrete terrain types, 2) are unable to handle hybrid terrain types (e.g., grassy dirt), and 3) require expensive labelled data to train visual semantic segmentation. We introduce Visual Representation Learning for Preference-Aware Path Planning (VRL-PAP), an alternative approach that overcomes all three limitations: VRL-PAP leverages unlabeled human demonstrations of navigation to autonomously generate triplets for learning visual representations of terrain that are viewpoint invariant and encode terrain types in a continuous representation space. The learned representations are then used along with the same unlabeled human navigation demonstrations to learn a mapping from the representation space to terrain costs. At run time, VRL-PAP maps from images to representations and then representations to costs to perform preference-aware path planning. We present empirical results from challenging outdoor settings that demonstrate VRL-PAP 1) is successfully able to pick paths that reflect demonstrated preferences, 2) is comparable in execution to geometric navigation with a highly detailed manually annotated map (without requiring such annotations), 3) is able to generalize to novel terrain types with minimal additional unlabeled demonstrations.