 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrate2Nav: Real-Time Visual Navigation with Implicit Language Reasoning in Human-Centric Environments
Jun 17, 2025Large Vision-Language Models (VLMs) have demonstrated potential in enhancing mobile robot navigation in human-centric environments by understanding contextual cues, human intentions, and social dynamics while exhibiting reasoning capabilities. However, their computational complexity and limited sensitivity to continuous numerical data impede real-time performance and precise motion control. To this end, we propose Narrate2Nav, a novel real-time vision-action model that leverages a novel self-supervised learning framework based on the Barlow Twins redundancy reduction loss to embed implicit natural language reasoning, social cues, and human intentions within a visual encoder-enabling reasoning in the model's latent space rather than token space. The model combines RGB inputs, motion commands, and textual signals of scene context during training to bridge from robot observations to low-level motion commands for short-horizon point-goal navigation during deployment. Extensive evaluation of Narrate2Nav across various challenging scenarios in both offline unseen dataset and real-world experiments demonstrates an overall improvement of 52.94 percent and 41.67 percent, respectively, over the next best baseline. Additionally, qualitative comparative analysis of Narrate2Nav's visual encoder attention map against four other baselines demonstrates enhanced attention to navigation-critical scene elements, underscoring its effectiveness in human-centric navigation tasks.
Dom, cars don't fly! -- Or do they? In-Air Vehicle Maneuver for High-Speed Off-Road Navigation
Mar 24, 2025
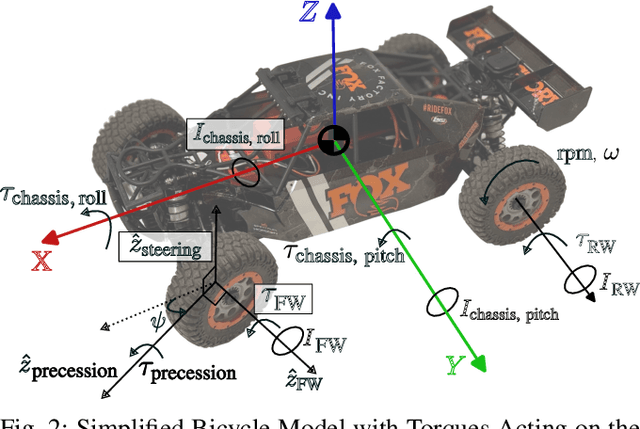

When pushing the speed limit for aggressive off-road navigation on uneven terrain, it is inevitable that vehicles may become airborne from time to time. During time-sensitive tasks, being able to fly over challenging terrain can also save time, instead of cautiously circumventing or slowly negotiating through. However, most off-road autonomy systems operate under the assumption that the vehicles are always on the ground and therefore limit operational speed. In this paper, we present a novel approach for in-air vehicle maneuver during high-speed off-road navigation. Based on a hybrid forward kinodynamic model using both physics principles and machine learning, our fixed-horizon, sampling-based motion planner ensures accurate vehicle landing poses and their derivatives within a short airborne time window using vehicle throttle and steering commands. We test our approach in extensive in-air experiments both indoors and outdoors, compare it against an error-driven control method, and demonstrate that precise and timely in-air vehicle maneuver is possible through existing ground vehicle controls.
Verti-Bench: A General and Scalable Off-Road Mobility Benchmark for Vertically Challenging Terrain
Feb 17, 2025



Recent advancement in off-road autonomy has shown promises in deploying autonomous mobile robots in outdoor off-road environments. Encouraging results have been reported from both simulated and real-world experiments. However, unlike evaluating off-road perception tasks on static datasets, benchmarking off-road mobility still faces significant challenges due to a variety of factors, including variations in vehicle platforms and terrain properties. Furthermore, different vehicle-terrain interactions need to be unfolded during mobility evaluation, which requires the mobility systems to interact with the environments instead of comparing against a pre-collected dataset. In this paper, we present Verti-Bench, a mobility benchmark that focuses on extremely rugged, vertically challenging off-road environments. 100 unique off-road environments and 1000 distinct navigation tasks with millions of off-road terrain properties, including a variety of geometry and semantics, rigid and deformable surfaces, and large natural obstacles, provide standardized and objective evaluation in high-fidelity multi-physics simulation. Verti-Bench is also scalable to various vehicle platforms with different scales and actuation mechanisms. We also provide datasets from expert demonstration, random exploration, failure cases (rolling over and getting stuck), as well as a gym-like interface for reinforcement learning. We use Verti-Bench to benchmark ten off-road mobility systems, present our findings, and identify future off-road mobility research directions.
M2P2: A Multi-Modal Passive Perception Dataset for Off-Road Mobility in Extreme Low-Light Conditions
Oct 01, 2024


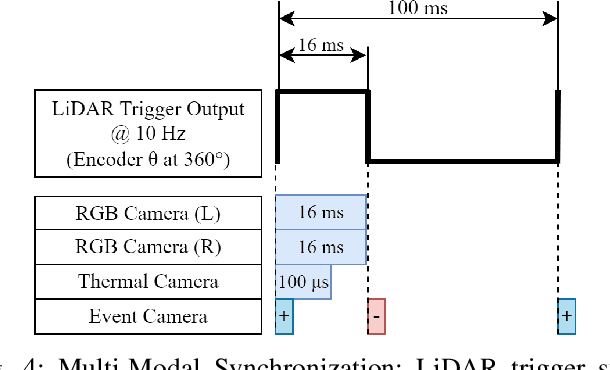
Long-duration, off-road, autonomous missions require robots to continuously perceive their surroundings regardless of the ambient lighting conditions. Most existing autonomy systems heavily rely on active sensing, e.g., LiDAR, RADAR, and Time-of-Flight sensors, or use (stereo) visible light imaging sensors, e.g., color cameras, to perceive environment geometry and semantics. In scenarios where fully passive perception is required and lighting conditions are degraded to an extent that visible light cameras fail to perceive, most downstream mobility tasks such as obstacle avoidance become impossible. To address such a challenge, this paper presents a Multi-Modal Passive Perception dataset, M2P2, to enable off-road mobility in low-light to no-light conditions. We design a multi-modal sensor suite including thermal, event, and stereo RGB cameras, GPS, two Inertia Measurement Units (IMUs), as well as a high-resolution LiDAR for ground truth, with a novel multi-sensor calibration procedure that can efficiently transform multi-modal perceptual streams into a common coordinate system. Our 10-hour, 32 km dataset also includes mobility data such as robot odometry and actions and covers well-lit, low-light, and no-light conditions, along with paved, on-trail, and off-trail terrain. Our results demonstrate that off-road mobility is possible through only passive perception in extreme low-light conditions using end-to-end learning and classical planning. The project website can be found at https://cs.gmu.edu/~xiao/Research/M2P2/
Traverse the Non-Traversable: Estimating Traversability for Wheeled Mobility on Vertically Challenging Terrain
Sep 26, 2024



Most traversability estimation techniques divide off-road terrain into traversable (e.g., pavement, gravel, and grass) and non-traversable (e.g., boulders, vegetation, and ditches) regions and then inform subsequent planners to produce trajectories on the traversable part. However, recent research demonstrated that wheeled robots can traverse vertically challenging terrain (e.g., extremely rugged boulders comparable in size to the vehicles themselves), which unfortunately would be deemed as non-traversable by existing techniques. Motivated by such limitations, this work aims at identifying the traversable from the seemingly non-traversable, vertically challenging terrain based on past kinodynamic vehicle-terrain interactions in a data-driven manner. Our new Traverse the Non-Traversable(TNT) traversability estimator can efficiently guide a down-stream sampling-based planner containing a high-precision 6-DoF kinodynamic model, which becomes deployable onboard a small-scale vehicle. Additionally, the estimated traversability can also be used as a costmap to plan global and local paths without sampling. Our experiment results show that TNT can improve planning performance, efficiency, and stability by 50%, 26.7%, and 9.2% respectively on a physical robot platform.
VertiEncoder: Self-Supervised Kinodynamic Representation Learning on Vertically Challenging Terrain
Sep 17, 2024We present VertiEncoder, a self-supervised representation learning approach for robot mobility on vertically challenging terrain. Using the same pre-training process, VertiEncoder can handle four different downstream tasks, including forward kinodynamics learning, inverse kinodynamics learning, behavior cloning, and patch reconstruction with a single representation. VertiEncoder uses a TransformerEncoder to learn the local context of its surroundings by random masking and next patch reconstruction. We show that VertiEncoder achieves better performance across all four different tasks compared to specialized End-to-End models with 77% fewer parameters. We also show VertiEncoder's comparable performance against state-of-the-art kinodynamic modeling and planning approaches in real-world robot deployment. These results underscore the efficacy of VertiEncoder in mitigating overfitting and fostering more robust generalization across diverse environmental contexts and downstream vehicle kinodynamic tasks.
Terrain-Attentive Learning for Efficient 6-DoF Kinodynamic Modeling on Vertically Challenging Terrain
Mar 25, 2024Wheeled robots have recently demonstrated superior mechanical capability to traverse vertically challenging terrain (e.g., extremely rugged boulders comparable in size to the vehicles themselves). Negotiating such terrain introduces significant variations of vehicle pose in all six Degrees-of-Freedom (DoFs), leading to imbalanced contact forces, varying momentum, and chassis deformation due to non-rigid tires and suspensions. To autonomously navigate on vertically challenging terrain, all these factors need to be efficiently reasoned within limited onboard computation and strict real-time constraints. In this paper, we propose a 6-DoF kinodynamics learning approach that is attentive only to the specific underlying terrain critical to the current vehicle-terrain interaction, so that it can be efficiently queried in real-time motion planners onboard small robots. Physical experiment results show our Terrain-Attentive Learning demonstrates on average 51.1% reduction in model prediction error among all 6 DoFs compared to a state-of-the-art model for vertically challenging terrain.
CAHSOR: Competence-Aware High-Speed Off-Road Ground Navigation in SE
Feb 10, 2024



While the workspace of traditional ground vehicles is usually assumed to be in a 2D plane, i.e., SE(2), such an assumption may not hold when they drive at high speeds on unstructured off-road terrain: High-speed sharp turns on high-friction surfaces may lead to vehicle rollover; Turning aggressively on loose gravel or grass may violate the non-holonomic constraint and cause significant lateral sliding; Driving quickly on rugged terrain will produce extensive vibration along the vertical axis. Therefore, most offroad vehicles are currently limited to drive only at low speeds to assure vehicle stability and safety. In this work, we aim at empowering high-speed off-road vehicles with competence awareness in SE(3) so that they can reason about the consequences of taking aggressive maneuvers on different terrain with a 6-DoF forward kinodynamic model. The model is learned from visual and inertial Terrain Representation for Off-road Navigation (TRON) using multimodal, self-supervised vehicle-terrain interactions. We demonstrate the efficacy of our Competence-Aware High-Speed Off-Road (CAHSOR) navigation approach on a physical ground robot in both an autonomous navigation and a human shared-control setup and show that CAHSOR can efficiently reduce vehicle instability by 62% while only compromising 8.6% average speed with the help of TRON.