 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Multi-Session Map Merging with Learned Local Descriptors
Dec 30, 2025Multi-session map merging is crucial for extended autonomous operations in large-scale environments. In this paper, we present GMLD, a learning-based local descriptor framework for large-scale multi-session point cloud map merging that systematically aligns maps collected across different sessions with overlapping regions. The proposed framework employs a keypoint-aware encoder and a plane-based geometric transformer to extract discriminative features for loop closure detection and relative pose estimation. To further improve global consistency, we include inter-session scan matching cost factors in the factor-graph optimization stage. We evaluate our framework on the public datasets, as well as self-collected data from diverse environments. The results show accurate and robust map merging with low error, and the learned features deliver strong performance in both loop closure detection and relative pose estimation.
OptMap: Geometric Map Distillation via Submodular Maximization
Dec 08, 2025

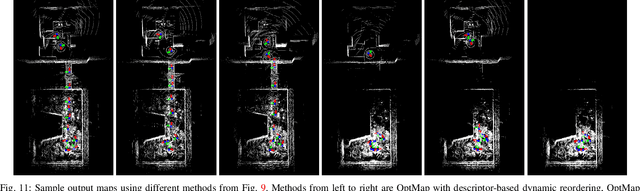

Autonomous robots rely on geometric maps to inform a diverse set of perception and decision-making algorithms. As autonomy requires reasoning and planning on multiple scales of the environment, each algorithm may require a different map for optimal performance. Light Detection And Ranging (LiDAR) sensors generate an abundance of geometric data to satisfy these diverse requirements, but selecting informative, size-constrained maps is computationally challenging as it requires solving an NP-hard combinatorial optimization. In this work we present OptMap: a geometric map distillation algorithm which achieves real-time, application-specific map generation via multiple theoretical and algorithmic innovations. A central feature is the maximization of set functions that exhibit diminishing returns, i.e., submodularity, using polynomial-time algorithms with provably near-optimal solutions. We formulate a novel submodular reward function which quantifies informativeness, reduces input set sizes, and minimizes bias in sequentially collected datasets. Further, we propose a dynamically reordered streaming submodular algorithm which improves empirical solution quality and addresses input order bias via an online approximation of the value of all scans. Testing was conducted on open-source and custom datasets with an emphasis on long-duration mapping sessions, highlighting OptMap's minimal computation requirements. Open-source ROS1 and ROS2 packages are available and can be used alongside any LiDAR SLAM algorithm.
Learning Smooth State-Dependent Traversability from Dense Point Clouds
Jun 04, 2025A key open challenge in off-road autonomy is that the traversability of terrain often depends on the vehicle's state. In particular, some obstacles are only traversable from some orientations. However, learning this interaction by encoding the angle of approach as a model input demands a large and diverse training dataset and is computationally inefficient during planning due to repeated model inference. To address these challenges, we present SPARTA, a method for estimating approach angle conditioned traversability from point clouds. Specifically, we impose geometric structure into our network by outputting a smooth analytical function over the 1-Sphere that predicts risk distribution for any angle of approach with minimal overhead and can be reused for subsequent queries. The function is composed of Fourier basis functions, which has important advantages for generalization due to their periodic nature and smoothness. We demonstrate SPARTA both in a high-fidelity simulation platform, where our model achieves a 91\% success rate crossing a 40m boulder field (compared to 73\% for the baseline), and on hardware, illustrating the generalization ability of the model to real-world settings.
Anomalies by Synthesis: Anomaly Detection using Generative Diffusion Models for Off-Road Navigation
May 28, 2025


In order to navigate safely and reliably in off-road and unstructured environments, robots must detect anomalies that are out-of-distribution (OOD) with respect to the training data. We present an analysis-by-synthesis approach for pixel-wise anomaly detection without making any assumptions about the nature of OOD data. Given an input image, we use a generative diffusion model to synthesize an edited image that removes anomalies while keeping the remaining image unchanged. Then, we formulate anomaly detection as analyzing which image segments were modified by the diffusion model. We propose a novel inference approach for guided diffusion by analyzing the ideal guidance gradient and deriving a principled approximation that bootstraps the diffusion model to predict guidance gradients. Our editing technique is purely test-time that can be integrated into existing workflows without the need for retraining or fine-tuning. Finally, we use a combination of vision-language foundation models to compare pixels in a learned feature space and detect semantically meaningful edits, enabling accurate anomaly detection for off-road navigation. Project website: https://siddancha.github.io/anomalies-by-diffusion-synthesis/
Submodular Optimization for Keyframe Selection & Usage in SLAM
Oct 08, 2024

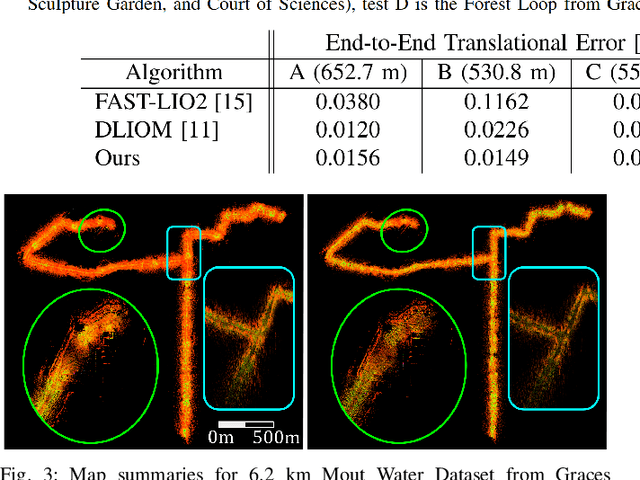
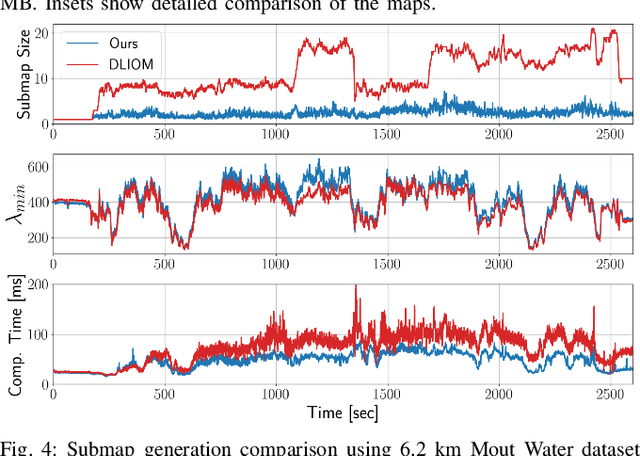
Keyframes are LiDAR scans saved for future reference in Simultaneous Localization And Mapping (SLAM), but despite their central importance most algorithms leave choices of which scans to save and how to use them to wasteful heuristics. This work proposes two novel keyframe selection strategies for localization and map summarization, as well as a novel approach to submap generation which selects keyframes that best constrain localization. Our results show that online keyframe selection and submap generation reduce the number of saved keyframes and improve per scan computation time without compromising localization performance. We also present a map summarization feature for quickly capturing environments under strict map size constraints.
LiDAR Inertial Odometry And Mapping Using Learned Registration-Relevant Features
Oct 03, 2024SLAM is an important capability for many autonomous systems, and modern LiDAR-based methods offer promising performance. However, for long duration missions, existing works that either operate directly the full pointclouds or on extracted features face key tradeoffs in accuracy and computational efficiency (e.g., memory consumption). To address these issues, this paper presents DFLIOM with several key innovations. Unlike previous methods that rely on handcrafted heuristics and hand-tuned parameters for feature extraction, we propose a learning-based approach that select points relevant to LiDAR SLAM pointcloud registration. Furthermore, we extend our prior work DLIOM with the learned feature extractor and observe our method enables similar or even better localization performance using only about 20\% of the points in the dense point clouds. We demonstrate that DFLIOM performs well on multiple public benchmarks, achieving a 2.4\% decrease in localization error and 57.5\% decrease in memory usage compared to state-of-the-art methods (DLIOM). Although extracting features with the proposed network requires extra time, it is offset by the faster processing time downstream, thus maintaining real-time performance using 20Hz LiDAR on our hardware setup. The effectiveness of our learning-based feature extraction module is further demonstrated through comparison with several handcrafted feature extractors.
M2P2: A Multi-Modal Passive Perception Dataset for Off-Road Mobility in Extreme Low-Light Conditions
Oct 01, 2024


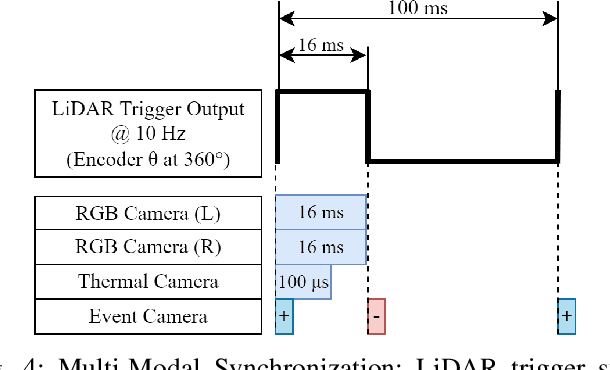
Long-duration, off-road, autonomous missions require robots to continuously perceive their surroundings regardless of the ambient lighting conditions. Most existing autonomy systems heavily rely on active sensing, e.g., LiDAR, RADAR, and Time-of-Flight sensors, or use (stereo) visible light imaging sensors, e.g., color cameras, to perceive environment geometry and semantics. In scenarios where fully passive perception is required and lighting conditions are degraded to an extent that visible light cameras fail to perceive, most downstream mobility tasks such as obstacle avoidance become impossible. To address such a challenge, this paper presents a Multi-Modal Passive Perception dataset, M2P2, to enable off-road mobility in low-light to no-light conditions. We design a multi-modal sensor suite including thermal, event, and stereo RGB cameras, GPS, two Inertia Measurement Units (IMUs), as well as a high-resolution LiDAR for ground truth, with a novel multi-sensor calibration procedure that can efficiently transform multi-modal perceptual streams into a common coordinate system. Our 10-hour, 32 km dataset also includes mobility data such as robot odometry and actions and covers well-lit, low-light, and no-light conditions, along with paved, on-trail, and off-trail terrain. Our results demonstrate that off-road mobility is possible through only passive perception in extreme low-light conditions using end-to-end learning and classical planning. The project website can be found at https://cs.gmu.edu/~xiao/Research/M2P2/
PIETRA: Physics-Informed Evidential Learning for Traversing Out-of-Distribution Terrain
Sep 04, 2024
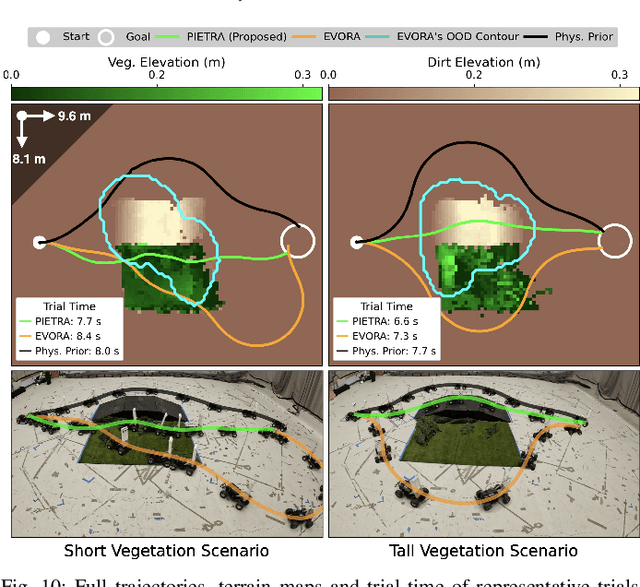
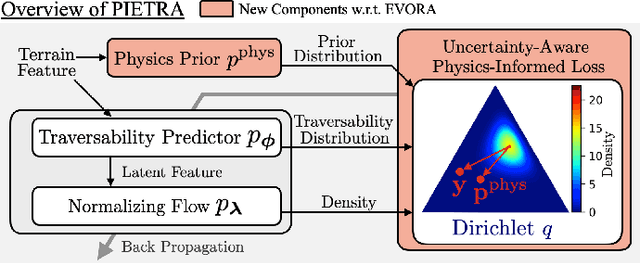
Self-supervised learning is a powerful approach for developing traversability models for off-road navigation, but these models often struggle with inputs unseen during training. Existing methods utilize techniques like evidential deep learning to quantify model uncertainty, helping to identify and avoid out-of-distribution terrain. However, always avoiding out-of-distribution terrain can be overly conservative, e.g., when novel terrain can be effectively analyzed using a physics-based model. To overcome this challenge, we introduce Physics-Informed Evidential Traversability (PIETRA), a self-supervised learning framework that integrates physics priors directly into the mathematical formulation of evidential neural networks and introduces physics knowledge implicitly through an uncertainty-aware, physics-informed training loss. Our evidential network seamlessly transitions between learned and physics-based predictions for out-of-distribution inputs. Additionally, the physics-informed loss regularizes the learned model, ensuring better alignment with the physics model. Extensive simulations and hardware experiments demonstrate that PIETRA improves both learning accuracy and navigation performance in environments with significant distribution shifts.
EVORA: Deep Evidential Traversability Learning for Risk-Aware Off-Road Autonomy
Nov 10, 2023

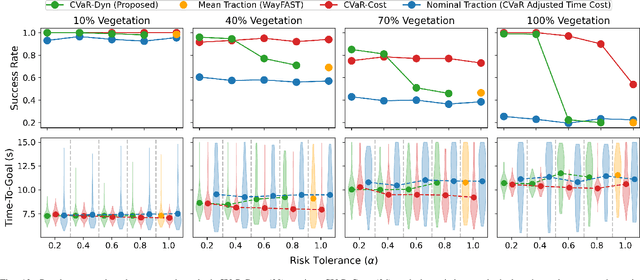

Traversing terrain with good traction is crucial for achieving fast off-road navigation. Instead of manually designing costs based on terrain features, existing methods learn terrain properties directly from data via self-supervision, but challenges remain to properly quantify and mitigate risks due to uncertainties in learned models. This work efficiently quantifies both aleatoric and epistemic uncertainties by learning discrete traction distributions and probability densities of the traction predictor's latent features. Leveraging evidential deep learning, we parameterize Dirichlet distributions with the network outputs and propose a novel uncertainty-aware squared Earth Mover's distance loss with a closed-form expression that improves learning accuracy and navigation performance. The proposed risk-aware planner simulates state trajectories with the worst-case expected traction to handle aleatoric uncertainty, and penalizes trajectories moving through terrain with high epistemic uncertainty. Our approach is extensively validated in simulation and on wheeled and quadruped robots, showing improved navigation performance compared to methods that assume no slip, assume the expected traction, or optimize for the worst-case expected cost.
Probabilistic Traversability Model for Risk-Aware Motion Planning in Off-Road Environments
Oct 01, 2022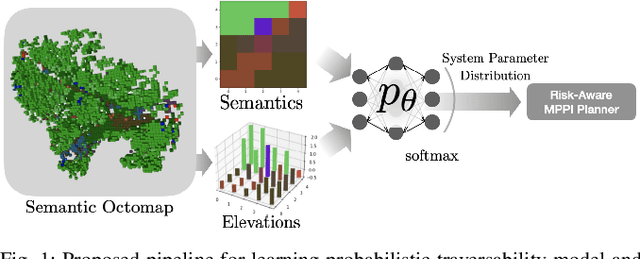
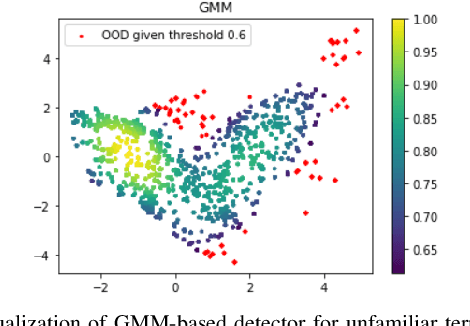
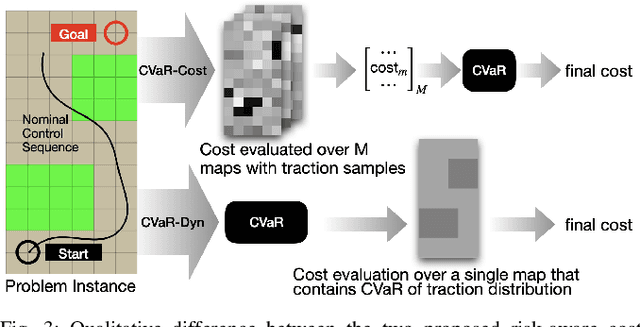
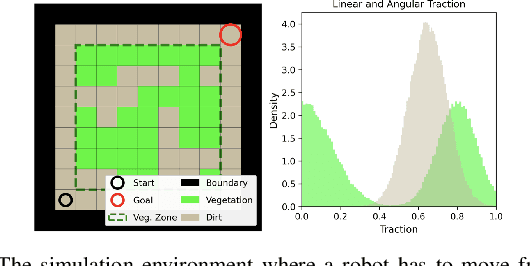
A key challenge in off-road navigation is that even visually similar or semantically identical terrain may have substantially different traction properties. Existing work typically assumes a nominal or expected robot dynamical model for planning, which can lead to degraded performance if the assumed models are not realizable given the terrain properties. In contrast, this work introduces a new probabilistic representation of traversability as a distribution of parameters in the robot's dynamical model that are conditioned on the terrain characteristics. This model is learned in a self-supervised manner by fitting a probability distribution over the parameters identified online, encoded as a neural network that takes terrain features as input. This work then presents two risk-aware planning algorithms that leverage the learned traversability model to plan risk-aware trajectories. Finally, a method for detecting unfamiliar terrain with respect to the training data is introduced based on a Gaussian Mixture Model fit to the latent space of the trained model. Experiments demonstrate that the proposed approach outperforms existing work that assumes nominal or expected robot dynamics in both success rate and completion time for representative navigation tasks. Furthermore, when the proposed approach is deployed in an unseen environment, excluding unfamiliar terrains during planning leads to improved success rate.