 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2P2: A Multi-Modal Passive Perception Dataset for Off-Road Mobility in Extreme Low-Light Conditions
Oct 01, 2024


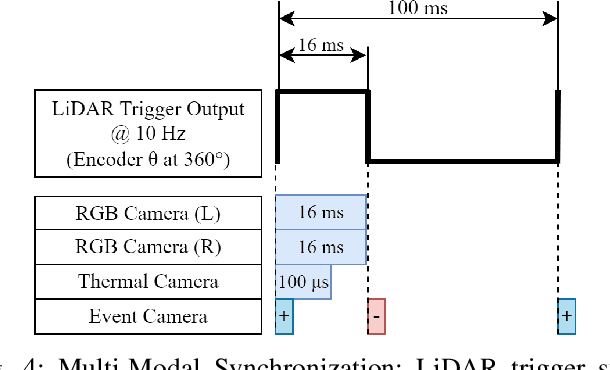
Long-duration, off-road, autonomous missions require robots to continuously perceive their surroundings regardless of the ambient lighting conditions. Most existing autonomy systems heavily rely on active sensing, e.g., LiDAR, RADAR, and Time-of-Flight sensors, or use (stereo) visible light imaging sensors, e.g., color cameras, to perceive environment geometry and semantics. In scenarios where fully passive perception is required and lighting conditions are degraded to an extent that visible light cameras fail to perceive, most downstream mobility tasks such as obstacle avoidance become impossible. To address such a challenge, this paper presents a Multi-Modal Passive Perception dataset, M2P2, to enable off-road mobility in low-light to no-light conditions. We design a multi-modal sensor suite including thermal, event, and stereo RGB cameras, GPS, two Inertia Measurement Units (IMUs), as well as a high-resolution LiDAR for ground truth, with a novel multi-sensor calibration procedure that can efficiently transform multi-modal perceptual streams into a common coordinate system. Our 10-hour, 32 km dataset also includes mobility data such as robot odometry and actions and covers well-lit, low-light, and no-light conditions, along with paved, on-trail, and off-trail terrain. Our results demonstrate that off-road mobility is possible through only passive perception in extreme low-light conditions using end-to-end learning and classical planning. The project website can be found at https://cs.gmu.edu/~xiao/Research/M2P2/
Turb-Seg-Res: A Segment-then-Restore Pipeline for Dynamic Videos with Atmospheric Turbulence
Apr 21, 2024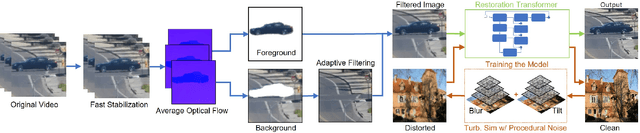
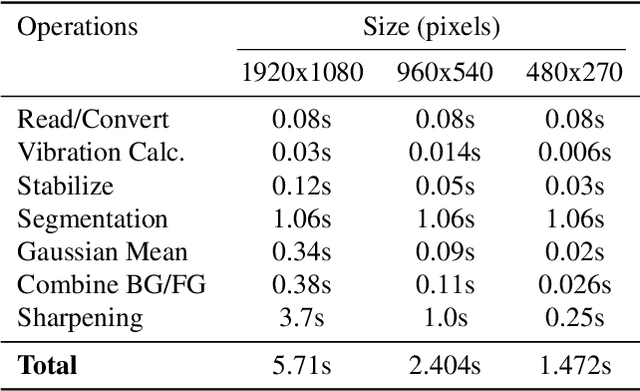

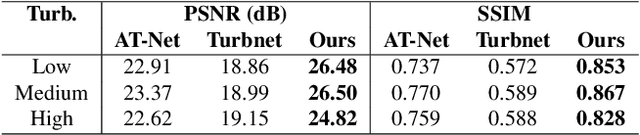
Tackling image degradation due to atmospheric turbulence, particularly in dynamic environment, remains a challenge for long-range imaging systems. Existing techniques have been primarily designed for static scenes or scenes with small motion. This paper presents the first segment-then-restore pipeline for restoring the videos of dynamic scenes in turbulent environment. We leverage mean optical flow with an unsupervised motion segmentation method to separate dynamic and static scene components prior to restoration. After camera shake compensation and segmentation, we introduce foreground/background enhancement leveraging the statistics of turbulence strength and a transformer model trained on a novel noise-based procedural turbulence generator for fast dataset augmentation. Benchmarked against existing restoration methods, our approach restores most of the geometric distortion and enhances sharpness for videos. We make our code, simulator, and data publicly available to advance the field of video restoration from turbulence: riponcs.github.io/TurbSegRes
Unsupervised Region-Growing Network for Object Segmentation in Atmospheric Turbulence
Nov 06, 2023

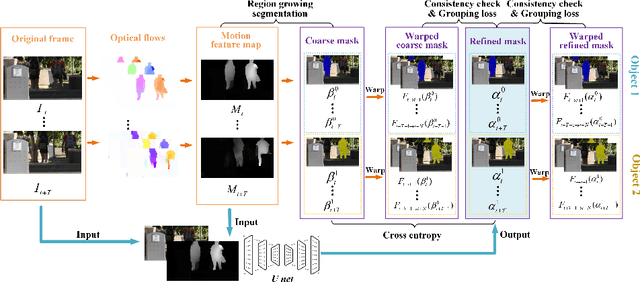
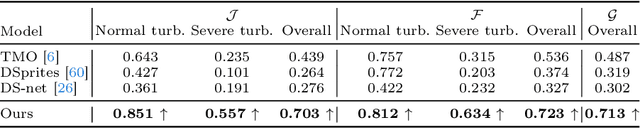
In this paper, we present a two-stage unsupervised foreground object segmentation network tailored for dynamic scenes affected by atmospheric turbulence. In the first stage, we utilize averaged optical flow from turbulence-distorted image sequences to feed a novel region-growing algorithm, crafting preliminary masks for each moving object in the video. In the second stage, we employ a U-Net architecture with consistency and grouping losses to further refine these masks optimizing their spatio-temporal alignment. Our approach does not require labeled training data and works across varied turbulence strengths for long-range video. Furthermore, we release the first moving object segmentation dataset of turbulence-affected videos, complete with manually annotated ground truth masks. Our method, evaluated on this new dataset, demonstrates superior segmentation accuracy and robustness as compared to current state-of-the-art unsupervised methods.
Textureless Deformable Surface Reconstruction with Invisible Markers
Aug 25, 2023Reconstructing and tracking deformable surface with little or no texture has posed long-standing challenges. Fundamentally, the challenges stem from textureless surfaces lacking features for establishing cross-image correspondences. In this work, we present a novel type of markers to proactively enrich the object's surface features, and thereby ease the 3D surface reconstruction and correspondence tracking. Our markers are made of fluorescent dyes, visible only under the ultraviolet (UV) light and invisible under regular lighting condition. Leveraging the markers, we design a multi-camera system that captures surface deformation under the UV light and the visible light in a time multiplexing fashion. Under the UV light, markers on the object emerge to enrich its surface texture, allowing high-quality 3D shape reconstruction and tracking. Under the visible light, markers become invisible, allowing us to capture the object's original untouched appearance. We perform experiments on various challenging scenes, including hand gestures, facial expressions, waving cloth, and hand-object interaction. In all these cases, we demonstrate that our system is able to produce robust, high-quality 3D reconstruction and tracking.
Underwater 3D Reconstruction Using Light Fields
Sep 05, 2021
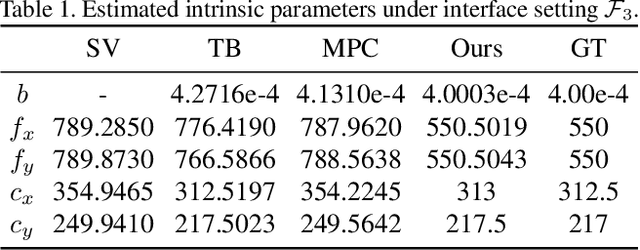
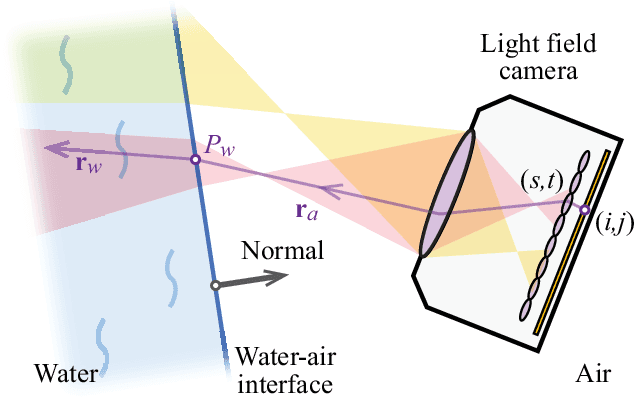
Underwater 3D reconstruction is challenging due to the refraction of light at the water-air interface (most electronic devices cannot be directly submerged in water). In this paper, we present an underwater 3D reconstruction solution using light field cameras. We first develop a light field camera calibration algorithm that simultaneously estimates the camera parameters and the geometry of the water-air interface. We then design a novel depth estimation algorithm for 3D reconstruction. Specifically, we match correspondences on curved epipolar lines caused by water refraction. We also observe that the view-dependent specular reflection is very weak in the underwater environment, resulting the angularly sampled rays in light field has uniform intensity. We therefore propose an angular uniformity constraint for depth optimization. We also develop a fast algorithm for locating the angular patches in presence of non-linear light paths. Extensive synthetic and real experiments demonstrate that our method can perform underwater 3D reconstruction with high accuracy.
Next-generation perception system for automated defects detection in composite laminates via polarized computational imaging
Aug 24, 2021

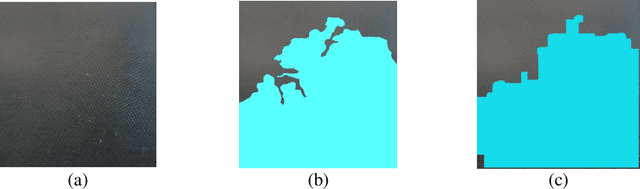

Finishing operations on large-scale composite components like wind turbine blades, including trimming and sanding, often require multiple workers and part repositioning. In the composites manufacturing industry, automation of such processes is challenging, as manufactured part geometry may be inconsistent and task completion is based on human judgment and experience. Implementing a mobile, collaborative robotic system capable of performing finishing tasks in dynamic and uncertain environments would improve quality and lower manufacturing costs. To complete the given tasks, the collaborative robotic team must properly understand the environment and detect irregularities in the manufactured parts. In this paper, we describe the initial implementation and demonstration of a polarized computational imaging system to identify defects in composite laminates. As the polarimetric images are highly relevant to the surface micro-geometry, they can be used to detect surface defects that are not visible in conventional color images. The proposed vision system successfully identifies defect types and surface characteristics (e.g., pinholes, voids, scratches, resin flash) for different glass fiber and carbon fiber laminates.
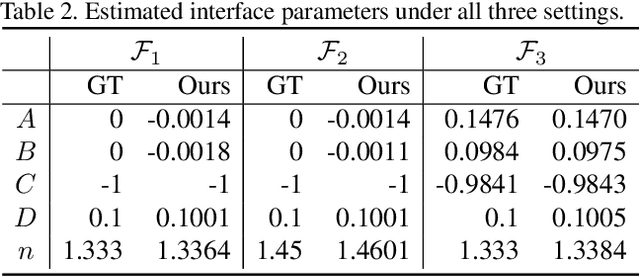
Non-Lambertian Surface Shape and Reflectance Reconstruction Using Concentric Multi-Spectral Light Field
Apr 19, 2019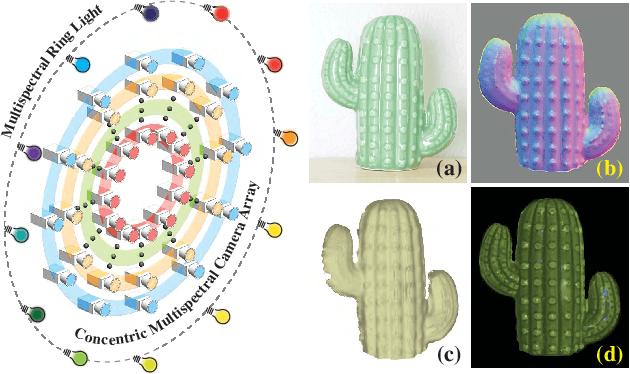
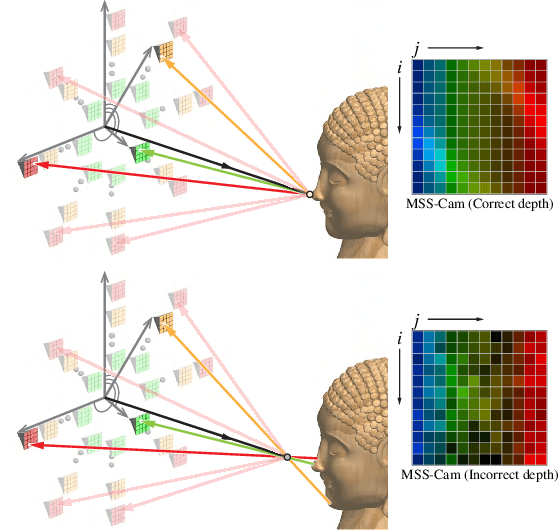
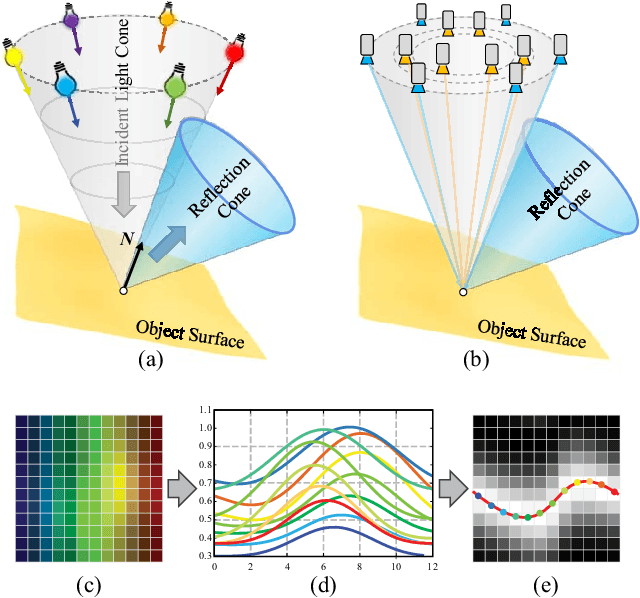
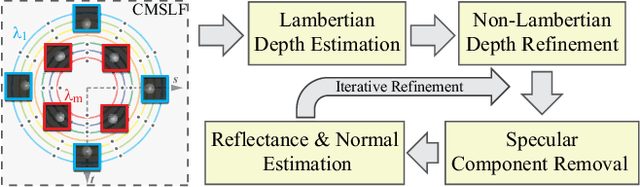
Recovering the shape and reflectance of non-Lambertian surfaces remains a challenging problem in computer vision since the view-dependent appearance invalidates traditional photo-consistency constraint. In this paper, we introduce a novel concentric multi-spectral light field (CMSLF) design that is able to recover the shape and reflectance of surfaces with arbitrary material in one shot. Our CMSLF system consists of an array of cameras arranged on concentric circles where each ring captures a specific spectrum. Coupled with a multi-spectral ring light, we are able to sample viewpoint and lighting variations in a single shot via spectral multiplexing. We further show that such concentric camera/light setting results in a unique pattern of specular changes across views that enables robust depth estimation. We formulate a physical-based reflectance model on CMSLF to estimate depth and multi-spectral reflectance map without imposing any surface prior. Extensive synthetic and real experiments show that our method outperforms state-of-the-art light field-based techniques, especially in non-Lambertian scenes.
PIV-Based 3D Fluid Flow Reconstruction Using Light Field Camera
Apr 15, 2019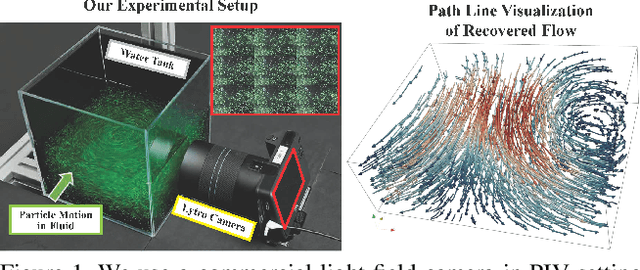

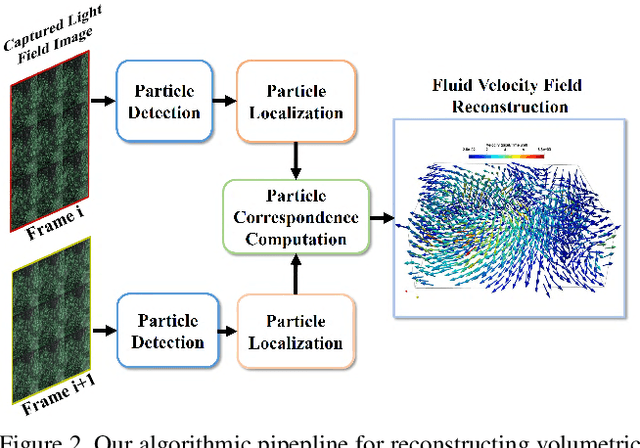
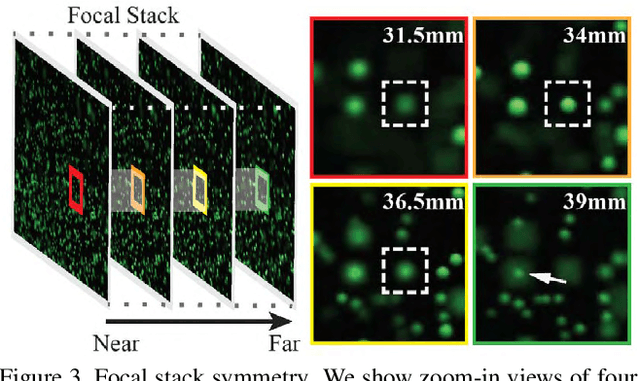
Particle Imaging Velocimetry (PIV) estimates the flow of fluid by analyzing the motion of injected particles. The problem is challenging as the particles lie at different depths but have similar appearance and tracking a large number of particles is particularly difficult. In this paper, we present a PIV solution that uses densely sampled light field to reconstruct and track 3D particles. We exploit the refocusing capability and focal symmetry constraint of the light field for reliable particle depth estimation. We further propose a new motion-constrained optical flow estimation scheme by enforcing local motion rigidity and the Navier-Stoke constraint. Comprehensive experiments on synthetic and real experiments show that using a single light field camera, our technique can recover dense and accurate 3D fluid flows in small to medium volumes.
Robust 3D Human Motion Reconstruction Via Dynamic Template Construction
Jan 31, 2018
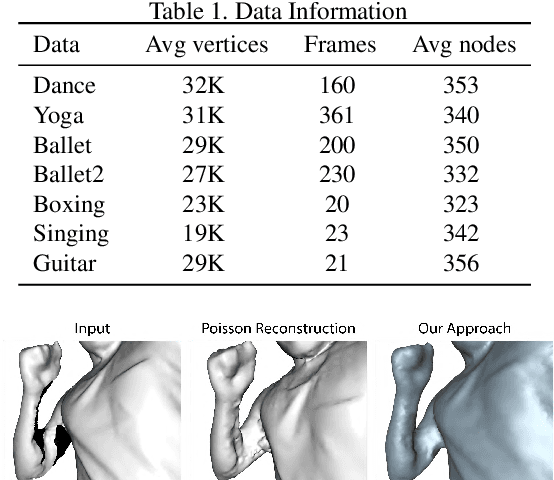

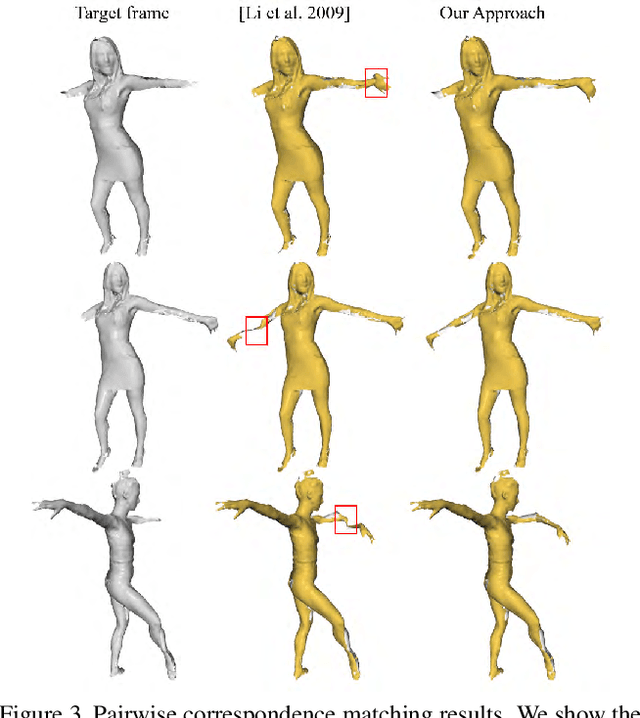
In multi-view human body capture systems, the recovered 3D geometry or even the acquired imagery data can be heavily corrupted due to occlusions, noise, limited field of- view, etc. Direct estimation of 3D pose, body shape or motion on these low-quality data has been traditionally challenging.In this paper, we present a graph-based non-rigid shape registration framework that can simultaneously recover 3D human body geometry and estimate pose/motion at high fidelity.Our approach first generates a global full-body template by registering all poses in the acquired motion sequence.We then construct a deformable graph by utilizing the rigid components in the global template. We directly warp the global template graph back to each motion frame in order to fill in missing geometry. Specifically, we combine local rigidity and temporal coherence constraints to maintain geometry and motion consistencies. Comprehensive experiments on various scenes show that our method is accurate and robust even in the presence of drastic motions.