 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable NGP-SR: Generalizable Neural Radiance Fields Super-Resolution via Neural Graph Primitives
Mar 20, 2026Neural Radiance Fields (NeRF) achieve photorealistic novel view synthesis but become costly when high-resolution (HR) rendering is required, as HR outputs demand dense sampling and higher-capacity models. Moreover, naively super-resolving per-view renderings in 2D often breaks multi-view consistency. We propose Generalizable NGP-SR, a 3D-aware super-resolution framework that reconstructs an HR radiance field directly from low-resolution (LR) posed images. Built on Neural Graphics Primitives (NGP), NGP-SR conditions radiance prediction on 3D coordinates and learned local texture tokens, enabling recovery of high-frequency details within the radiance field and producing view-consistent HR novel views without external HR references or post-hoc 2D upsampling. Importantly, our model is generalizable: once trained, it can be applied to unseen scenes and rendered from novel viewpoints without per-scene optimization. Experiments on multiple datasets show that NGP-SR consistently improves both reconstruction quality and runtime efficiency over prior NeRF-based super-resolution methods, offering a practical solution for scalable high-resolution novel view synthesis.
Implicit Neural Representation for Video Restoration
Jun 05, 2025High-resolution (HR) videos play a crucial role in many computer vision applications. Although existing video restoration (VR) methods can significantly enhance video quality by exploiting temporal information across video frames, they are typically trained for fixed upscaling factors and lack the flexibility to handle scales or degradations beyond their training distribution. In this paper, we introduce VR-INR, a novel video restoration approach based on Implicit Neural Representations (INRs) that is trained only on a single upscaling factor ($\times 4$) but generalizes effectively to arbitrary, unseen super-resolution scales at test time. Notably, VR-INR also performs zero-shot denoising on noisy input, despite never having seen noisy data during training. Our method employs a hierarchical spatial-temporal-texture encoding framework coupled with multi-resolution implicit hash encoding, enabling adaptive decoding of high-resolution and noise-suppressed frames from low-resolution inputs at any desired magnification. Experimental results show that VR-INR consistently maintains high-quality reconstructions at unseen scales and noise during training, significantly outperforming state-of-the-art approaches in sharpness, detail preservation, and denoising efficacy.
Implicit Neural Representation for Video and Image Super-Resolution
Mar 06, 2025
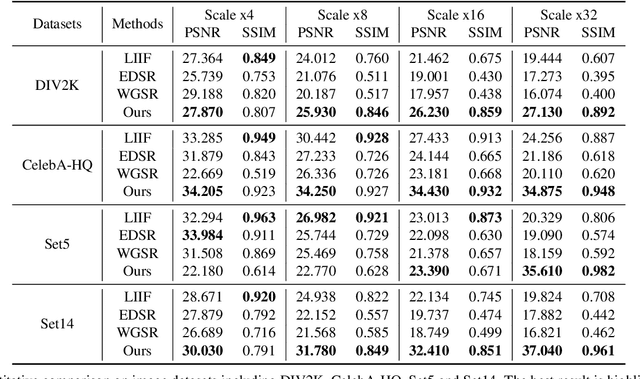
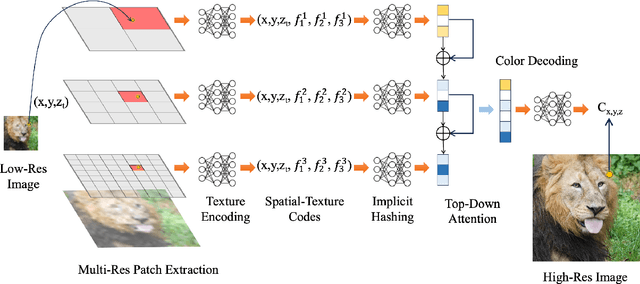
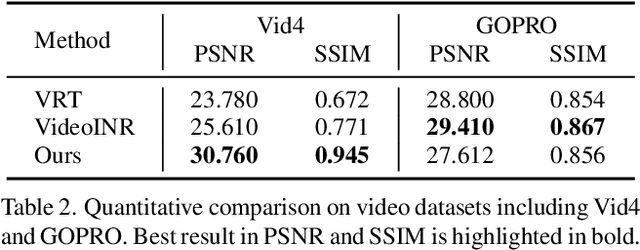
We present a novel approach for super-resolution that utilizes implicit neural representation (INR) to effectively reconstruct and enhance low-resolution videos and images. By leveraging the capacity of neural networks to implicitly encode spatial and temporal features, our method facilitates high-resolution reconstruction using only low-resolution inputs and a 3D high-resolution grid. This results in an efficient solution for both image and video super-resolution. Our proposed method, SR-INR, maintains consistent details across frames and images, achieving impressive temporal stability without relying on the computationally intensive optical flow or motion estimation typically used in other video super-resolution techniques. The simplicity of our approach contrasts with the complexity of many existing methods, making it both effective and efficient. Experimental evaluations show that SR-INR delivers results on par with or superior to state-of-the-art super-resolution methods, while maintaining a more straightforward structure and reduced computational demands. These findings highlight the potential of implicit neural representations as a powerful tool for reconstructing high-quality, temporally consistent video and image signals from low-resolution data.
Turb-Seg-Res: A Segment-then-Restore Pipeline for Dynamic Videos with Atmospheric Turbulence
Apr 21, 2024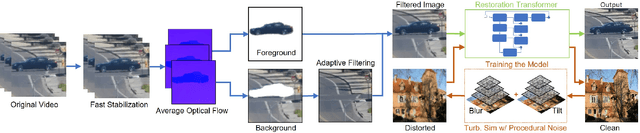
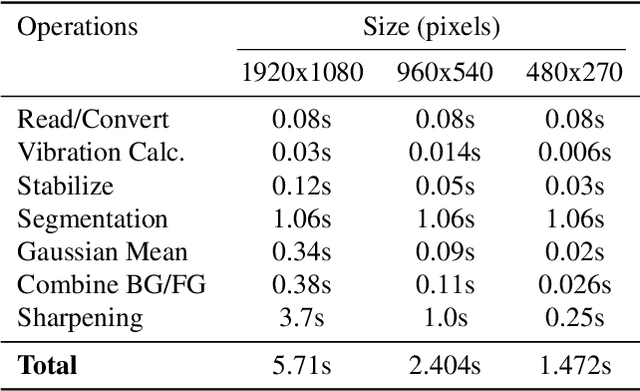

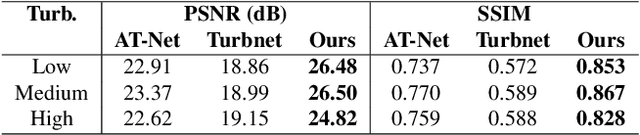
Tackling image degradation due to atmospheric turbulence, particularly in dynamic environment, remains a challenge for long-range imaging systems. Existing techniques have been primarily designed for static scenes or scenes with small motion. This paper presents the first segment-then-restore pipeline for restoring the videos of dynamic scenes in turbulent environment. We leverage mean optical flow with an unsupervised motion segmentation method to separate dynamic and static scene components prior to restoration. After camera shake compensation and segmentation, we introduce foreground/background enhancement leveraging the statistics of turbulence strength and a transformer model trained on a novel noise-based procedural turbulence generator for fast dataset augmentation. Benchmarked against existing restoration methods, our approach restores most of the geometric distortion and enhances sharpness for videos. We make our code, simulator, and data publicly available to advance the field of video restoration from turbulence: riponcs.github.io/TurbSegRes
Unsupervised Microscopy Video Denoising
Apr 17, 2024



In this paper, we introduce a novel unsupervised network to denoise microscopy videos featured by image sequences captured by a fixed location microscopy camera. Specifically, we propose a DeepTemporal Interpolation method, leveraging a temporal signal filter integrated into the bottom CNN layers, to restore microscopy videos corrupted by unknown noise types. Our unsupervised denoising architecture is distinguished by its ability to adapt to multiple noise conditions without the need for pre-existing noise distribution knowledge, addressing a significant challenge in real-world medical applications. Furthermore, we evaluate our denoising framework using both real microscopy recordings and simulated data, validating our outperforming video denoising performance across a broad spectrum of noise scenarios. Extensive experiments demonstrate that our unsupervised model consistently outperforms state-of-the-art supervised and unsupervised video denoising techniques, proving especially effective for microscopy videos.
Unsupervised Region-Growing Network for Object Segmentation in Atmospheric Turbulence
Nov 06, 2023

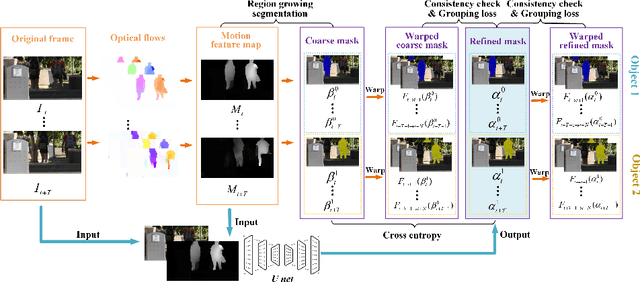
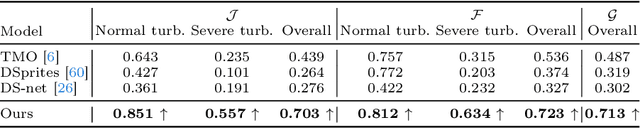
In this paper, we present a two-stage unsupervised foreground object segmentation network tailored for dynamic scenes affected by atmospheric turbulence. In the first stage, we utilize averaged optical flow from turbulence-distorted image sequences to feed a novel region-growing algorithm, crafting preliminary masks for each moving object in the video. In the second stage, we employ a U-Net architecture with consistency and grouping losses to further refine these masks optimizing their spatio-temporal alignment. Our approach does not require labeled training data and works across varied turbulence strengths for long-range video. Furthermore, we release the first moving object segmentation dataset of turbulence-affected videos, complete with manually annotated ground truth masks. Our method, evaluated on this new dataset, demonstrates superior segmentation accuracy and robustness as compared to current state-of-the-art unsupervised methods.
Unsupervised Coordinate-Based Video Denoising
Jul 01, 2023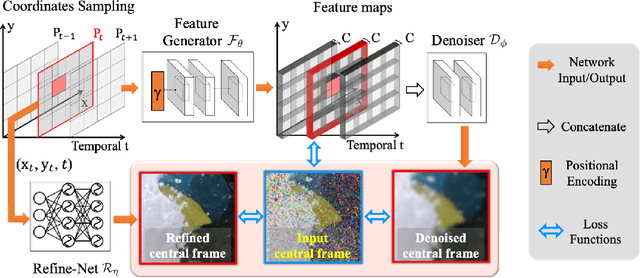
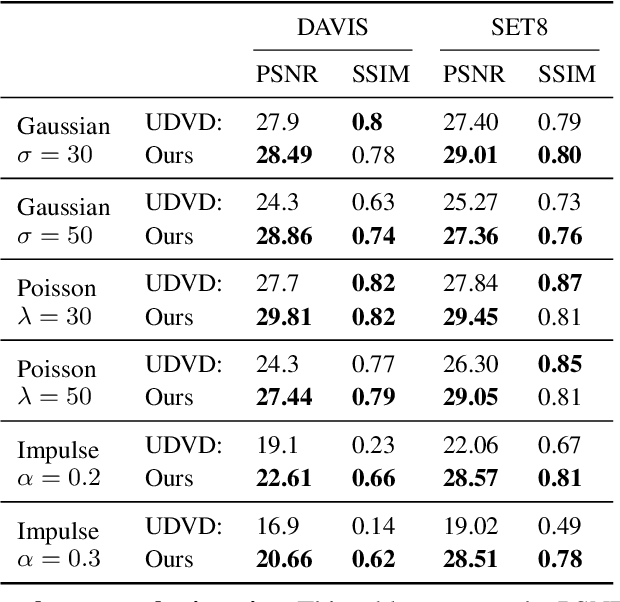


In this paper, we introduce a novel unsupervised video denoising deep learning approach that can help to mitigate data scarcity issues and shows robustness against different noise patterns, enhancing its broad applicability. Our method comprises three modules: a Feature generator creating features maps, a Denoise-Net generating denoised but slightly blurry reference frames, and a Refine-Net re-introducing high-frequency details. By leveraging the coordinate-based network, we can greatly simplify the network structure while preserving high-frequency details in the denoised video frames. Extensive experiments on both simulated and real-captured demonstrate that our method can effectively denoise real-world calcium imaging video sequences without prior knowledge of noise models and data augmentation during training.
Deep learning-based algorithm for assessment of knee osteoarthritis severity in radiographs matches performance of radiologists
Jul 25, 2022
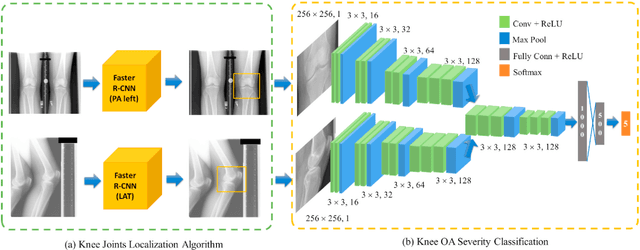
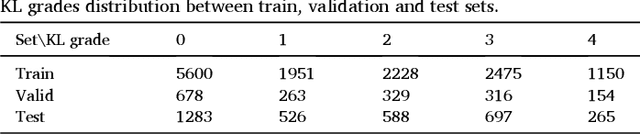
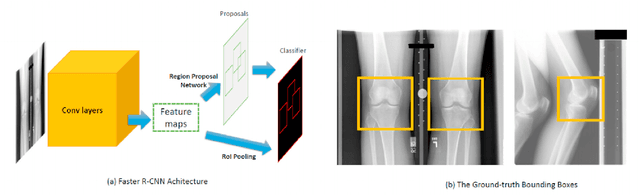
A fully-automated deep learning algorithm matched performance of radiologists in assessment of knee osteoarthritis severity in radiographs using the Kellgren-Lawrence grading system. To develop an automated deep learning-based algorithm that jointly uses Posterior-Anterior (PA) and Lateral (LAT) views of knee radiographs to assess knee osteoarthritis severity according to the Kellgren-Lawrence grading system. We used a dataset of 9739 exams from 2802 patients from Multicenter Osteoarthritis Study (MOST). The dataset was divided into a training set of 2040 patients, a validation set of 259 patients and a test set of 503 patients. A novel deep learning-based method was utilized for assessment of knee OA in two steps: (1) localization of knee joints in the images, (2) classification according to the KL grading system. Our method used both PA and LAT views as the input to the model. The scores generated by the algorithm were compared to the grades provided in the MOST dataset for the entire test set as well as grades provided by 5 radiologists at our institution for a subset of the test set. The model obtained a multi-class accuracy of 71.90% on the entire test set when compared to the ratings provided in the MOST dataset. The quadratic weighted Kappa coefficient for this set was 0.9066. The average quadratic weighted Kappa between all pairs of radiologists from our institution who took a part of study was 0.748. The average quadratic-weighted Kappa between the algorithm and the radiologists at our institution was 0.769. The proposed model performed demonstrated equivalency of KL classification to MSK radiologists, but clearly superior reproducibility. Our model also agreed with radiologists at our institution to the same extent as the radiologists with each other. The algorithm could be used to provide reproducible assessment of knee osteoarthritis severity.
NIMBLE: A Non-rigid Hand Model with Bones and Muscles
Feb 09, 2022
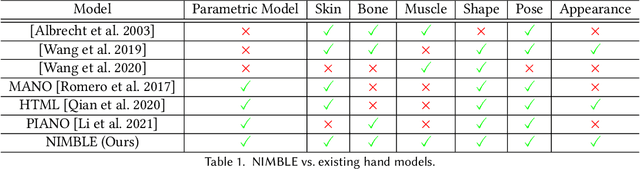

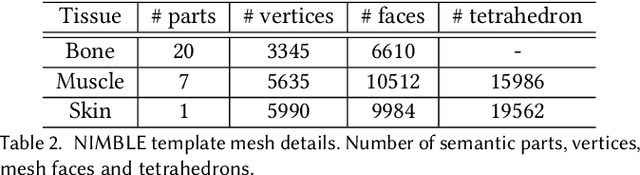
Emerging Metaverse applications demand reliable, accurate, and photorealistic reproductions of human hands to perform sophisticated operations as if in the physical world. While real human hand represents one of the most intricate coordination between bones, muscle, tendon, and skin, state-of-the-art techniques unanimously focus on modeling only the skeleton of the hand. In this paper, we present NIMBLE, a novel parametric hand model that includes the missing key components, bringing 3D hand model to a new level of realism. We first annotate muscles, bones and skins on the recent Magnetic Resonance Imaging hand (MRI-Hand) dataset and then register a volumetric template hand onto individual poses and subjects within the dataset. NIMBLE consists of 20 bones as triangular meshes, 7 muscle groups as tetrahedral meshes, and a skin mesh. Via iterative shape registration and parameter learning, it further produces shape blend shapes, pose blend shapes, and a joint regressor. We demonstrate applying NIMBLE to modeling, rendering, and visual inference tasks. By enforcing the inner bones and muscles to match anatomic and kinematic rules, NIMBLE can animate 3D hands to new poses at unprecedented realism. To model the appearance of skin, we further construct a photometric HandStage to acquire high-quality textures and normal maps to model wrinkles and palm print. Finally, NIMBLE also benefits learning-based hand pose and shape estimation by either synthesizing rich data or acting directly as a differentiable layer in the inference network.
Detection of masses and architectural distortions in digital breast tomosynthesis: a publicly available dataset of 5,060 patients and a deep learning model
Nov 13, 2020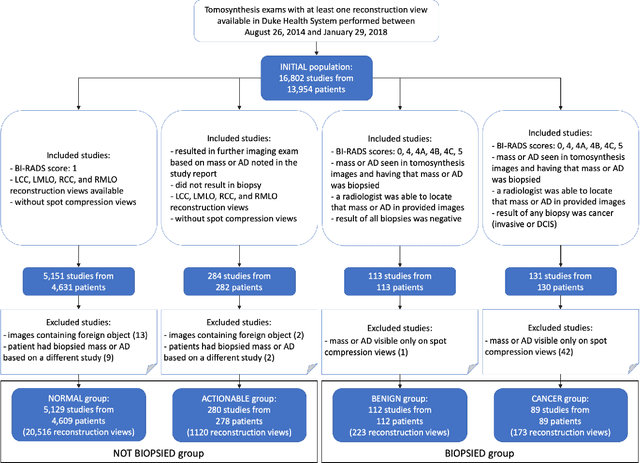
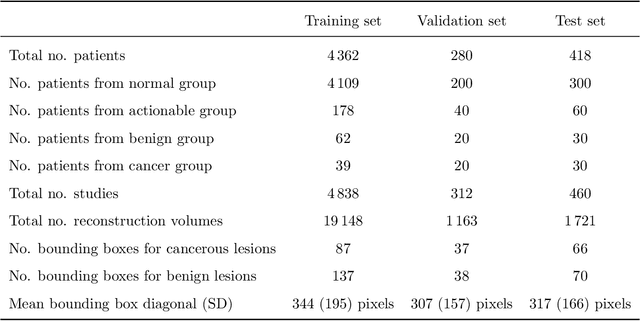
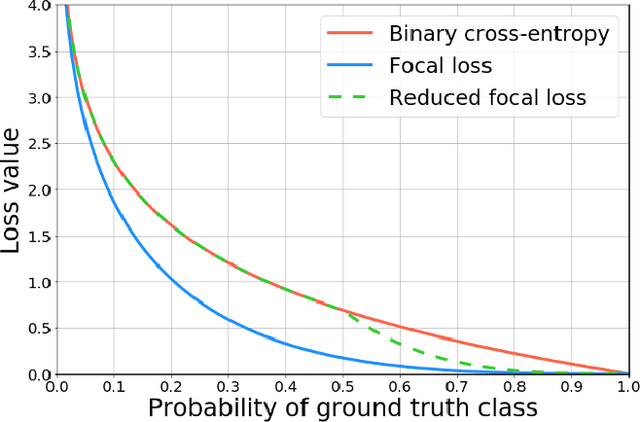
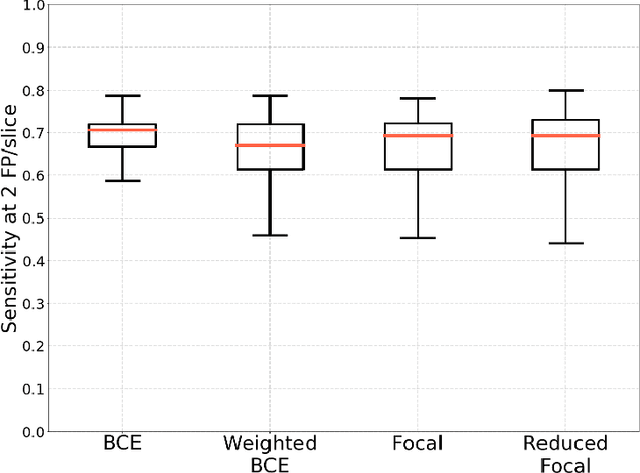
Breast cancer screening is one of the most common radiological tasks with over 39 million exams performed each year. While breast cancer screening has been one of the most studied medical imaging applications of artificial intelligence, the development and evaluation of the algorithms are hindered due to the lack of well-annotated large-scale publicly available datasets. This is particularly an issue for digital breast tomosynthesis (DBT) which is a relatively new breast cancer screening modality. We have curated and made publicly available a large-scale dataset of digital breast tomosynthesis images. It contains 22,032 reconstructed DBT volumes belonging to 5,610 studies from 5,060 patients. This included four groups: (1) 5,129 normal studies, (2) 280 studies where additional imaging was needed but no biopsy was performed, (3) 112 benign biopsied studies, and (4) 89 studies with cancer. Our dataset included masses and architectural distortions which were annotated by two experienced radiologists. Additionally, we developed a single-phase deep learning detection model and tested it using our dataset to serve as a baseline for future research. Our model reached a sensitivity of 65% at 2 false positives per breast. Our large, diverse, and highly-curated dataset will facilitate development and evaluation of AI algorithms for breast cancer screening through providing data for training as well as common set of cases for model validation. The performance of the model developed in our study shows that the task remains challenging and will serve as a baseline for future model development.