 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Neural Representation for Video and Image Super-Resolution
Paper and Code
Mar 06, 2025
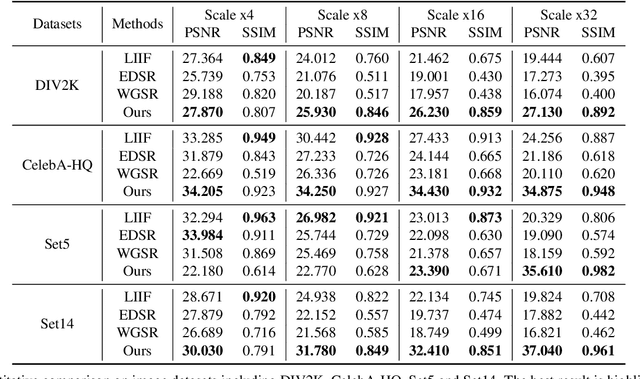
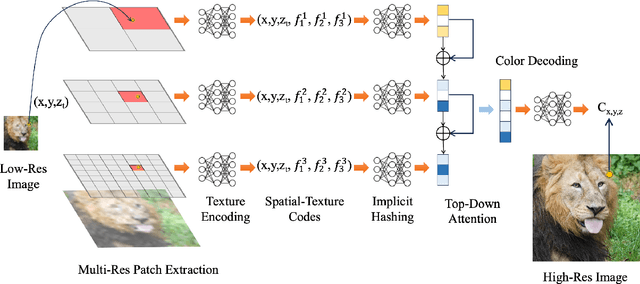
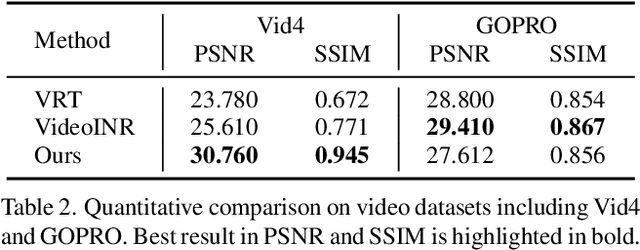
We present a novel approach for super-resolution that utilizes implicit neural representation (INR) to effectively reconstruct and enhance low-resolution videos and images. By leveraging the capacity of neural networks to implicitly encode spatial and temporal features, our method facilitates high-resolution reconstruction using only low-resolution inputs and a 3D high-resolution grid. This results in an efficient solution for both image and video super-resolution. Our proposed method, SR-INR, maintains consistent details across frames and images, achieving impressive temporal stability without relying on the computationally intensive optical flow or motion estimation typically used in other video super-resolution techniques. The simplicity of our approach contrasts with the complexity of many existing methods, making it both effective and efficient. Experimental evaluations show that SR-INR delivers results on par with or superior to state-of-the-art super-resolution methods, while maintaining a more straightforward structure and reduced computational demands. These findings highlight the potential of implicit neural representations as a powerful tool for reconstructing high-quality, temporally consistent video and image signals from low-resolution data.