 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Based Restoration for Multi-Modal 3D Object Detection in Adverse Weather
Dec 18, 2025Multi-modal 3D object detection is important for reliable perception in robotics and autonomous driving. However, its effectiveness remains limited under adverse weather conditions due to weather-induced distortions and misalignment between different data modalities. In this work, we propose DiffFusion, a novel framework designed to enhance robustness in challenging weather through diffusion-based restoration and adaptive cross-modal fusion. Our key insight is that diffusion models possess strong capabilities for denoising and generating data that can adapt to various weather conditions. Building on this, DiffFusion introduces Diffusion-IR restoring images degraded by weather effects and Point Cloud Restoration (PCR) compensating for corrupted LiDAR data using image object cues. To tackle misalignments between two modalities, we develop Bidirectional Adaptive Fusion and Alignment Module (BAFAM). It enables dynamic multi-modal fusion and bidirectional bird's-eye view (BEV) alignment to maintain consistent spatial correspondence. Extensive experiments on three public datasets show that DiffFusion achieves state-of-the-art robustness under adverse weather while preserving strong clean-data performance. Zero-shot results on the real-world DENSE dataset further validate its generalization. The implementation of our DiffFusion will be released as open-source.
GradEscape: A Gradient-Based Evader Against AI-Generated Text Detectors
Jun 09, 2025In this paper, we introduce GradEscape, the first gradient-based evader designed to attack AI-generated text (AIGT) detectors. GradEscape overcomes the undifferentiable computation problem, caused by the discrete nature of text, by introducing a novel approach to construct weighted embeddings for the detector input. It then updates the evader model parameters using feedback from victim detectors, achieving high attack success with minimal text modification. To address the issue of tokenizer mismatch between the evader and the detector, we introduce a warm-started evader method, enabling GradEscape to adapt to detectors across any language model architecture. Moreover, we employ novel tokenizer inference and model extraction techniques, facilitating effective evasion even in query-only access. We evaluate GradEscape on four datasets and three widely-used language models, benchmarking it against four state-of-the-art AIGT evaders. Experimental results demonstrate that GradEscape outperforms existing evaders in various scenarios, including with an 11B paraphrase model, while utilizing only 139M parameters. We have successfully applied GradEscape to two real-world commercial AIGT detectors. Our analysis reveals that the primary vulnerability stems from disparity in text expression styles within the training data. We also propose a potential defense strategy to mitigate the threat of AIGT evaders. We open-source our GradEscape for developing more robust AIGT detectors.
Dialogue Injection Attack: Jailbreaking LLMs through Context Manipulation
Mar 11, 2025



Large language models (LLMs) have demonstrated significant utility in a wide range of applications; however, their deployment is plagued by security vulnerabilities, notably jailbreak attacks. These attacks manipulate LLMs to generate harmful or unethical content by crafting adversarial prompts. While much of the current research on jailbreak attacks has focused on single-turn interactions, it has largely overlooked the impact of historical dialogues on model behavior. In this paper, we introduce a novel jailbreak paradigm, Dialogue Injection Attack (DIA), which leverages the dialogue history to enhance the success rates of such attacks. DIA operates in a black-box setting, requiring only access to the chat API or knowledge of the LLM's chat template. We propose two methods for constructing adversarial historical dialogues: one adapts gray-box prefilling attacks, and the other exploits deferred responses. Our experiments show that DIA achieves state-of-the-art attack success rates on recent LLMs, including Llama-3.1 and GPT-4o. Additionally, we demonstrate that DIA can bypass 5 different defense mechanisms, highlighting its robustness and effectiveness.
Learning Trustworthy Model from Noisy Labels based on Rough Set for Surface Defect Detection
Jan 25, 2023



In the surface defect detection, there are some suspicious regions that cannot be uniquely classified as abnormal or normal. The annotating of suspicious regions is easily affected by factors such as workers' emotional fluctuations and judgment standard, resulting in noisy labels, which in turn leads to missing and false detections, and ultimately leads to inconsistent judgments of product quality. Unlike the usual noisy labels, the ones used for surface defect detection appear to be inconsistent rather than mislabeled. The noise occurs in almost every label and is difficult to correct or evaluate. In this paper, we proposed a framework that learns trustworthy models from noisy labels for surface defect defection. At first, to avoid the negative impact of noisy labels on the model, we represent the suspicious regions with consistent and precise elements at the pixel-level and redesign the loss function. Secondly, without changing network structure and adding any extra labels, pluggable spatially correlated Bayesian module is proposed. Finally, the defect discrimination confidence is proposed to measure the uncertainty, with which anomalies can be identified as defects. Our results indicate not only the effectiveness of the proposed method in learning from noisy labels, but also robustness and real-time performance.
SCULPTOR: Skeleton-Consistent Face Creation Using a Learned Parametric Generator
Sep 14, 2022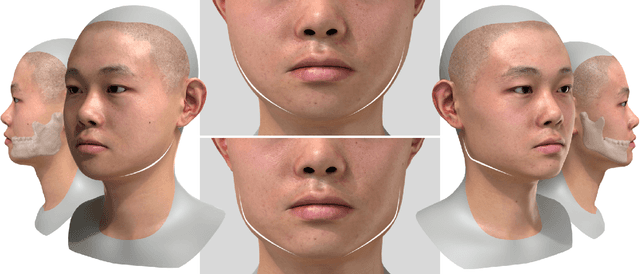
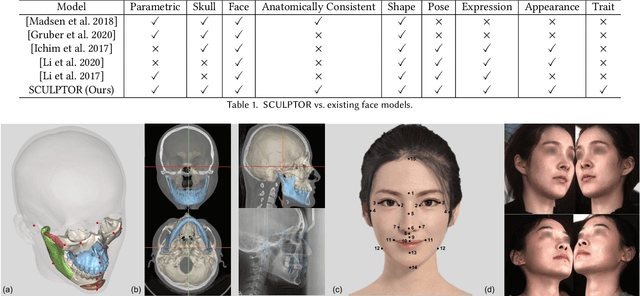
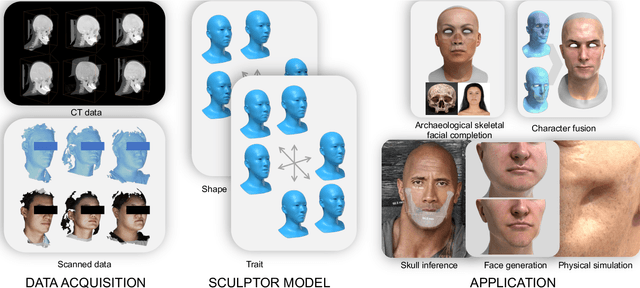
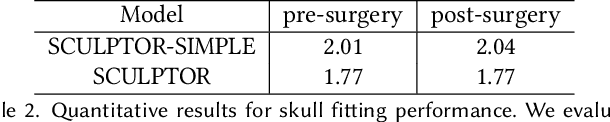
Recent years have seen growing interest in 3D human faces modelling due to its wide applications in digital human, character generation and animation. Existing approaches overwhelmingly emphasized on modeling the exterior shapes, textures and skin properties of faces, ignoring the inherent correlation between inner skeletal structures and appearance. In this paper, we present SCULPTOR, 3D face creations with Skeleton Consistency Using a Learned Parametric facial generaTOR, aiming to facilitate easy creation of both anatomically correct and visually convincing face models via a hybrid parametric-physical representation. At the core of SCULPTOR is LUCY, the first large-scale shape-skeleton face dataset in collaboration with plastic surgeons. Named after the fossils of one of the oldest known human ancestors, our LUCY dataset contains high-quality Computed Tomography (CT) scans of the complete human head before and after orthognathic surgeries, critical for evaluating surgery results. LUCY consists of 144 scans of 72 subjects (31 male and 41 female) where each subject has two CT scans taken pre- and post-orthognathic operations. Based on our LUCY dataset, we learn a novel skeleton consistent parametric facial generator, SCULPTOR, which can create the unique and nuanced facial features that help define a character and at the same time maintain physiological soundness. Our SCULPTOR jointly models the skull, face geometry and face appearance under a unified data-driven framework, by separating the depiction of a 3D face into shape blend shape, pose blend shape and facial expression blend shape. SCULPTOR preserves both anatomic correctness and visual realism in facial generation tasks compared with existing methods. Finally, we showcase the robustness and effectiveness of SCULPTOR in various fancy applications unseen before.
NIMBLE: A Non-rigid Hand Model with Bones and Muscles
Feb 09, 2022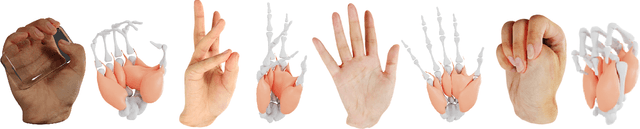
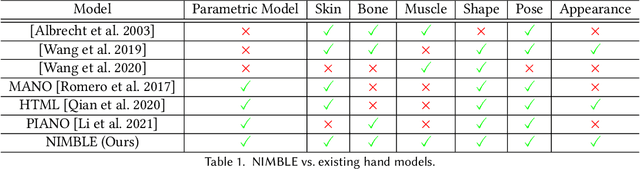

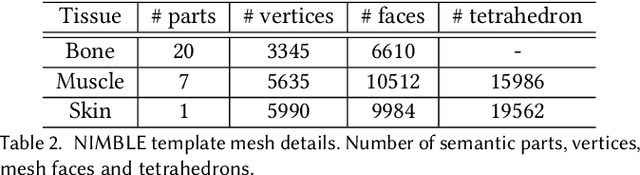
Emerging Metaverse applications demand reliable, accurate, and photorealistic reproductions of human hands to perform sophisticated operations as if in the physical world. While real human hand represents one of the most intricate coordination between bones, muscle, tendon, and skin, state-of-the-art techniques unanimously focus on modeling only the skeleton of the hand. In this paper, we present NIMBLE, a novel parametric hand model that includes the missing key components, bringing 3D hand model to a new level of realism. We first annotate muscles, bones and skins on the recent Magnetic Resonance Imaging hand (MRI-Hand) dataset and then register a volumetric template hand onto individual poses and subjects within the dataset. NIMBLE consists of 20 bones as triangular meshes, 7 muscle groups as tetrahedral meshes, and a skin mesh. Via iterative shape registration and parameter learning, it further produces shape blend shapes, pose blend shapes, and a joint regressor. We demonstrate applying NIMBLE to modeling, rendering, and visual inference tasks. By enforcing the inner bones and muscles to match anatomic and kinematic rules, NIMBLE can animate 3D hands to new poses at unprecedented realism. To model the appearance of skin, we further construct a photometric HandStage to acquire high-quality textures and normal maps to model wrinkles and palm print. Finally, NIMBLE also benefits learning-based hand pose and shape estimation by either synthesizing rich data or acting directly as a differentiable layer in the inference network.
An Arbitrary Scale Super-Resolution Approach for 3-Dimensional Magnetic Resonance Image using Implicit Neural Representation
Oct 29, 2021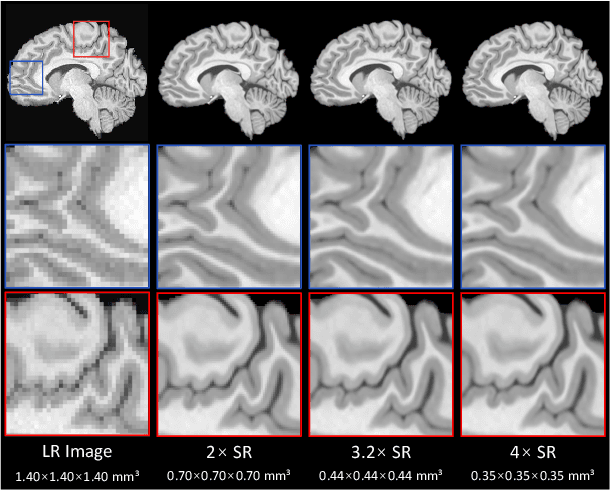
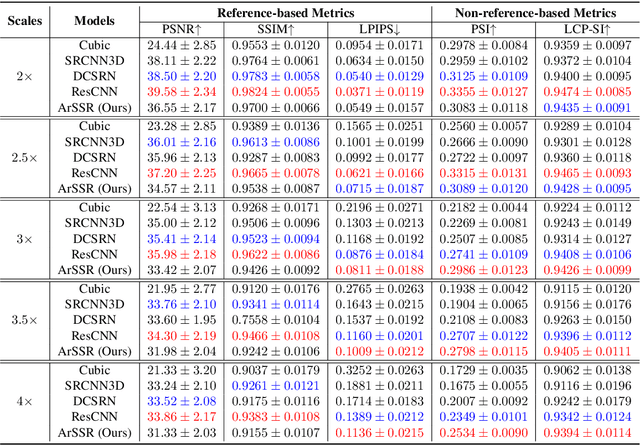
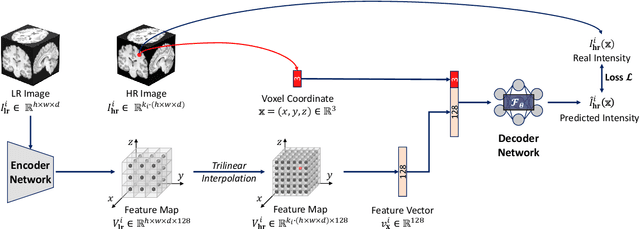
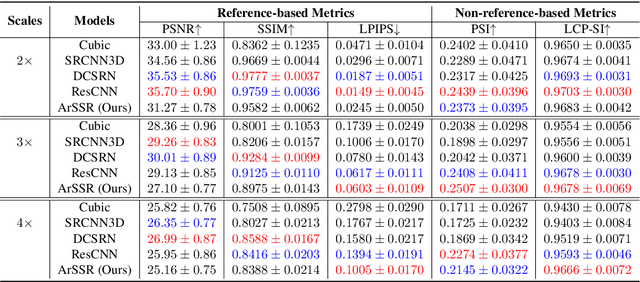
High Resolution (HR) medical images provide rich anatomical structure details to facilitate early and accurate diagnosis. In MRI, restricted by hardware capacity, scan time, and patient cooperation ability, isotropic 3D HR image acquisition typically requests long scan time and, results in small spatial coverage and low SNR. Recent studies showed that, with deep convolutional neural networks, isotropic HR MR images could be recovered from low-resolution (LR) input via single image super-resolution (SISR) algorithms. However, most existing SISR methods tend to approach a scale-specific projection between LR and HR images, thus these methods can only deal with a fixed up-sampling rate. For achieving different up-sampling rates, multiple SR networks have to be built up respectively, which is very time-consuming and resource-intensive. In this paper, we propose ArSSR, an Arbitrary Scale Super-Resolution approach for recovering 3D HR MR images. In the ArSSR model, the reconstruction of HR images with different up-scaling rates is defined as learning a continuous implicit voxel function from the observed LR images. Then the SR task is converted to represent the implicit voxel function via deep neural networks from a set of paired HR-LR training examples. The ArSSR model consists of an encoder network and a decoder network. Specifically, the convolutional encoder network is to extract feature maps from the LR input images and the fully-connected decoder network is to approximate the implicit voxel function. Due to the continuity of the learned function, a single ArSSR model can achieve arbitrary up-sampling rate reconstruction of HR images from any input LR image after training. Experimental results on three datasets show that the ArSSR model can achieve state-of-the-art SR performance for 3D HR MR image reconstruction while using a single trained model to achieve arbitrary up-sampling scales.
IREM: High-Resolution Magnetic Resonance (MR) Image Reconstruction via Implicit Neural Representation
Jun 29, 2021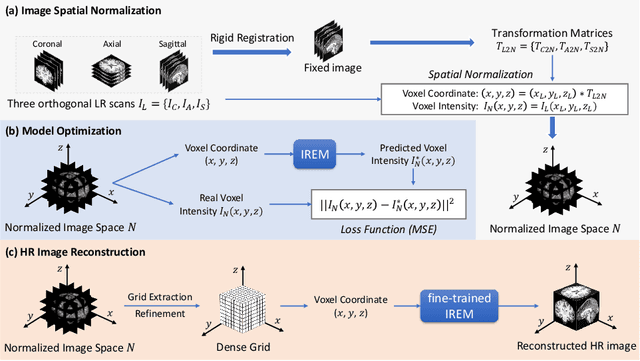
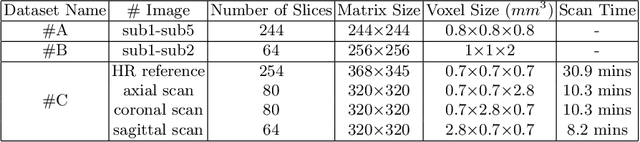
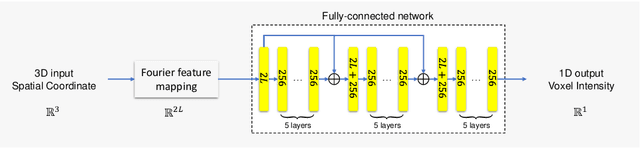
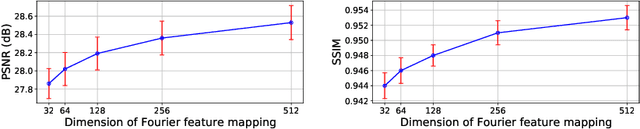
For collecting high-quality high-resolution (HR) MR image, we propose a novel image reconstruction network named IREM, which is trained on multiple low-resolution (LR) MR images and achieve an arbitrary up-sampling rate for HR image reconstruction. In this work, we suppose the desired HR image as an implicit continuous function of the 3D image spatial coordinate and the thick-slice LR images as several sparse discrete samplings of this function. Then the super-resolution (SR) task is to learn the continuous volumetric function from a limited observations using an fully-connected neural network combined with Fourier feature positional encoding. By simply minimizing the error between the network prediction and the acquired LR image intensity across each imaging plane, IREM is trained to represent a continuous model of the observed tissue anatomy. Experimental results indicate that IREM succeeds in representing high frequency image feature, and in real scene data collection, IREM reduces scan time and achieves high-quality high-resolution MR imaging in terms of SNR and local image detail.
PIANO: A Parametric Hand Bone Model from Magnetic Resonance Imaging
Jun 21, 2021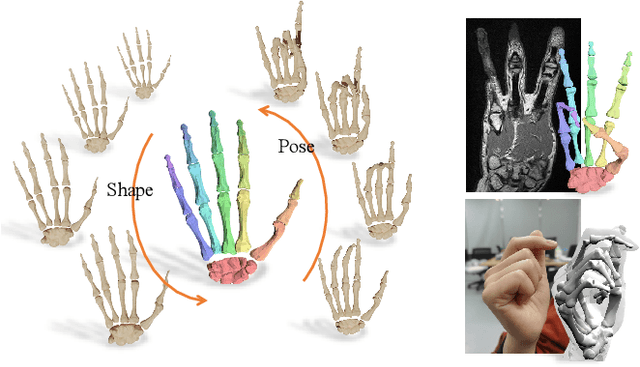
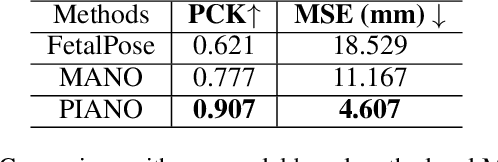

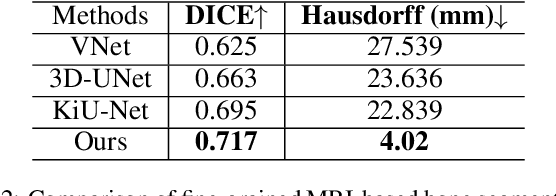
Hand modeling is critical for immersive VR/AR, action understanding, or human healthcare. Existing parametric models account only for hand shape, pose, or texture, without modeling the anatomical attributes like bone, which is essential for realistic hand biomechanics analysis. In this paper, we present PIANO, the first parametric bone model of human hands from MRI data. Our PIANO model is biologically correct, simple to animate, and differentiable, achieving more anatomically precise modeling of the inner hand kinematic structure in a data-driven manner than the traditional hand models based on the outer surface only. Furthermore, our PIANO model can be applied in neural network layers to enable training with a fine-grained semantic loss, which opens up the new task of data-driven fine-grained hand bone anatomic and semantic understanding from MRI or even RGB images. We make our model publicly available.
AutoSweep: Recovering 3D Editable Objectsfrom a Single Photograph
May 28, 2020


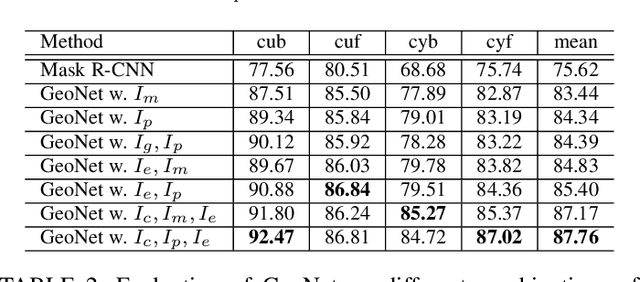
This paper presents a fully automatic framework for extracting editable 3D objects directly from a single photograph. Unlike previous methods which recover either depth maps, point clouds, or mesh surfaces, we aim to recover 3D objects with semantic parts and can be directly edited. We base our work on the assumption that most human-made objects are constituted by parts and these parts can be well represented by generalized primitives. Our work makes an attempt towards recovering two types of primitive-shaped objects, namely, generalized cuboids and generalized cylinders. To this end, we build a novel instance-aware segmentation network for accurate part separation. Our GeoNet outputs a set of smooth part-level masks labeled as profiles and bodies. Then in a key stage, we simultaneously identify profile-body relations and recover 3D parts by sweeping the recognized profile along their body contour and jointly optimize the geometry to align with the recovered masks. Qualitative and quantitative experiments show that our algorithm can recover high quality 3D models and outperforms existing methods in both instance segmentation and 3D reconstruction. The dataset and code of AutoSweep are available at https://chenxin.tech/AutoSweep.html.
* 10 pages, 12 figures