 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORGEval: Graph-Theoretic Evaluation of LLMs in Optimization Modeling
Oct 31, 2025Formulating optimization problems for industrial applications demands significant manual effort and domain expertise. While Large Language Models (LLMs) show promise in automating this process, evaluating their performance remains difficult due to the absence of robust metrics. Existing solver-based approaches often face inconsistency, infeasibility issues, and high computational costs. To address these issues, we propose ORGEval, a graph-theoretic evaluation framework for assessing LLMs' capabilities in formulating linear and mixed-integer linear programs. ORGEval represents optimization models as graphs, reducing equivalence detection to graph isomorphism testing. We identify and prove a sufficient condition, when the tested graphs are symmetric decomposable (SD), under which the Weisfeiler-Lehman (WL) test is guaranteed to correctly detect isomorphism. Building on this, ORGEval integrates a tailored variant of the WL-test with an SD detection algorithm to evaluate model equivalence. By focusing on structural equivalence rather than instance-level configurations, ORGEval is robust to numerical variations. Experimental results show that our method can successfully detect model equivalence and produce 100\% consistent results across random parameter configurations, while significantly outperforming solver-based methods in runtime, especially on difficult problems. Leveraging ORGEval, we construct the Bench4Opt dataset and benchmark state-of-the-art LLMs on optimization modeling. Our results reveal that although optimization modeling remains challenging for all LLMs, DeepSeek-V3 and Claude-Opus-4 achieve the highest accuracies under direct prompting, outperforming even leading reasoning models.
Learning Trustworthy Model from Noisy Labels based on Rough Set for Surface Defect Detection
Jan 25, 2023



In the surface defect detection, there are some suspicious regions that cannot be uniquely classified as abnormal or normal. The annotating of suspicious regions is easily affected by factors such as workers' emotional fluctuations and judgment standard, resulting in noisy labels, which in turn leads to missing and false detections, and ultimately leads to inconsistent judgments of product quality. Unlike the usual noisy labels, the ones used for surface defect detection appear to be inconsistent rather than mislabeled. The noise occurs in almost every label and is difficult to correct or evaluate. In this paper, we proposed a framework that learns trustworthy models from noisy labels for surface defect defection. At first, to avoid the negative impact of noisy labels on the model, we represent the suspicious regions with consistent and precise elements at the pixel-level and redesign the loss function. Secondly, without changing network structure and adding any extra labels, pluggable spatially correlated Bayesian module is proposed. Finally, the defect discrimination confidence is proposed to measure the uncertainty, with which anomalies can be identified as defects. Our results indicate not only the effectiveness of the proposed method in learning from noisy labels, but also robustness and real-time performance.
Federated Reinforcement Learning
Jan 25, 2019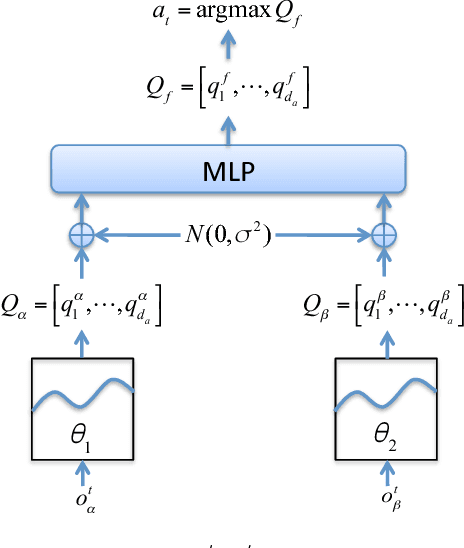
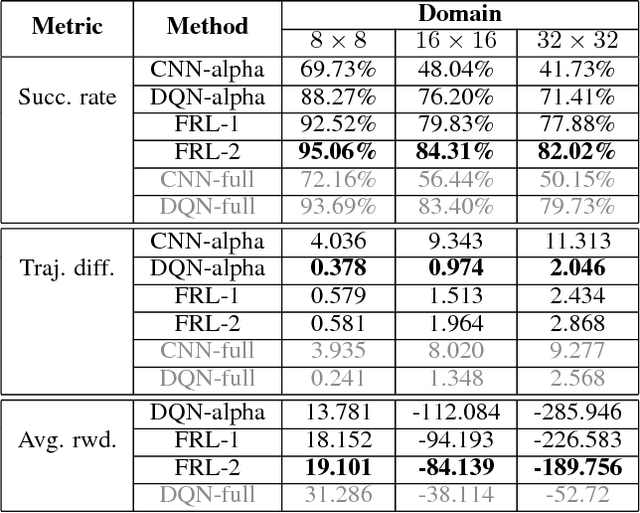
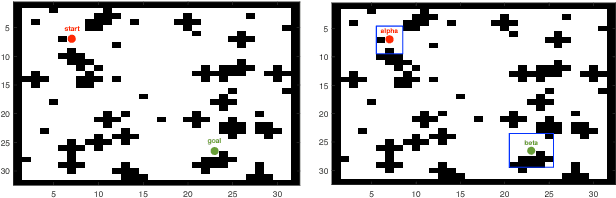
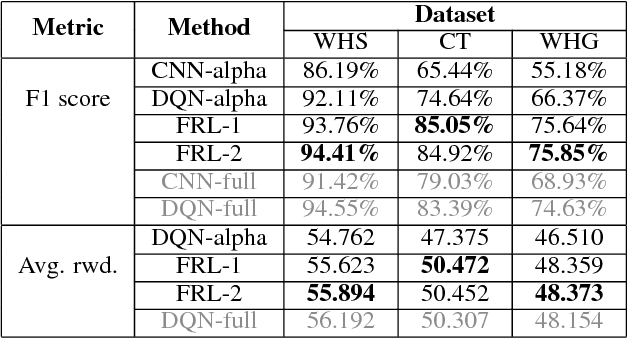
In reinforcement learning, building policies of high-quality is challenging when the feature space of states is small and the training data is limited. Directly transferring data or knowledge from an agent to another agent will not work due to the privacy requirement of data and models. In this paper, we propose a novel reinforcement learning approach to considering the privacy requirement and building Q-network for each agent with the help of other agents, namely federated reinforcement learning (FRL). To protect the privacy of data and models, we exploit Gausian differentials on the information shared with each other when updating their local models. In the experiment, we evaluate our FRL framework in two diverse domains, Grid-world and Text2Action domains, by comparing to various baselines.