 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Reinforcement Learning
Paper and Code
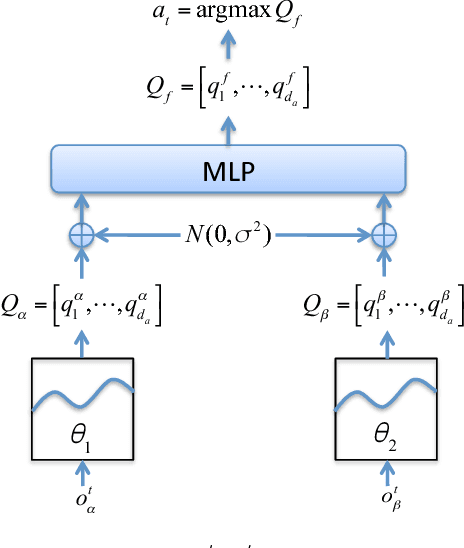
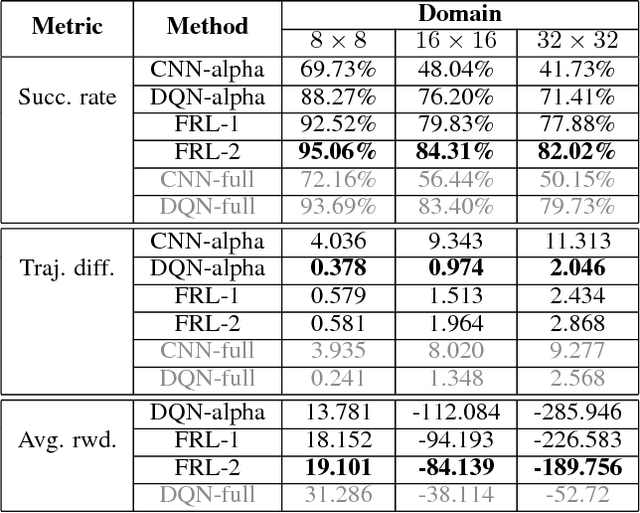
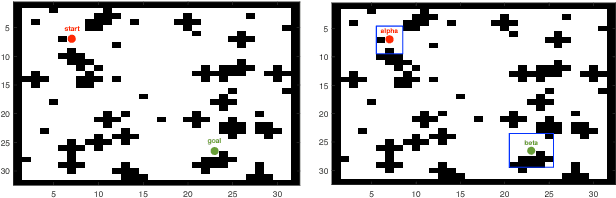
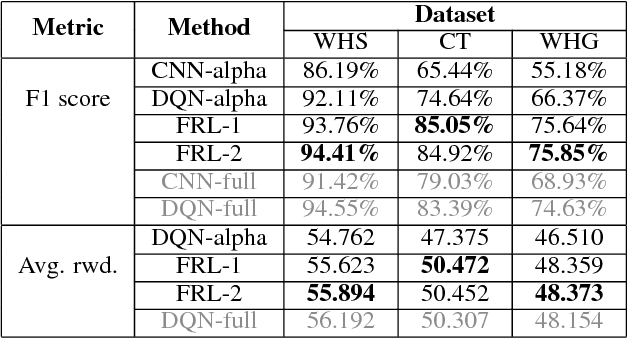
In reinforcement learning, building policies of high-quality is challenging when the feature space of states is small and the training data is limited. Directly transferring data or knowledge from an agent to another agent will not work due to the privacy requirement of data and models. In this paper, we propose a novel reinforcement learning approach to considering the privacy requirement and building Q-network for each agent with the help of other agents, namely federated reinforcement learning (FRL). To protect the privacy of data and models, we exploit Gausian differentials on the information shared with each other when updating their local models. In the experiment, we evaluate our FRL framework in two diverse domains, Grid-world and Text2Action domains, by comparing to various baselines.