 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCT-to-X-ray Distillation Under Tiny Paired Cohorts: An Evidence-Bounded Reproducible Pilot Study
Mar 31, 2026Chest X-ray and computed tomography (CT) provide complementary views of thoracic disease, yet most computer-aided diagnosis models are trained and deployed within a single imaging modality. The concrete question studied here is narrower and deployment-oriented: on a patient-level paired chest cohort, can CT act as training-only supervision for a binary disease versus non-disease X-ray classifier without requiring CT at inference time? We study this setting as a cross-modality teacher--student distillation problem and use JDCNet as an executable pilot scaffold rather than as a validated superior architecture. On the original patient-level paired split from a public paired chest imaging cohort, a stripped-down plain cross-modal logit-KD control attains the highest mean result on the four-image validation subset (0.875 accuracy and 0.714 macro-F1), whereas the full module-augmented JDCNet variant remains at 0.750 accuracy and 0.429 macro-F1. To test whether that ranking is a split artifact, we additionally run eight patient-level Monte Carlo resamples with same-case comparisons, stronger mechanism controls based on attention transfer and feature hints, and imbalance-sensitive analyses. Under this resampled protocol, late fusion attains the highest mean accuracy (0.885), same-modality distillation attains the highest mean macro-F1 (0.554) and balanced accuracy (0.660), the plain cross-modal control drops to 0.500 mean balanced accuracy, and neither attention transfer nor feature hints recover a robust cross-modality advantage. The contribution of this study is therefore not a validated CT-to-X-ray architecture, but a reproducible and evidence-bounded pilot protocol that makes the exact task definition, failure modes, ranking instability, and the minimum requirements for future credible CT-to-X-ray transfer claims explicit.
Resolving Blind Inverse Problems under Dynamic Range Compression via Structured Forward Operator Modeling
Mar 02, 2026Recovering radiometric fidelity from unknown dynamic range compression (UDRC), such as low-light enhancement and HDR reconstruction, is a challenging blind inverse problem, due to the unknown forward model and irreversible information loss introduced by compression. To address this challenge, we first identify monotonicity as the fundamental physical invariant shared across UDRC tasks. Leveraging this insight, we introduce the \textbf{cascaded monotonic Bernstein} (CaMB) operator to parameterize the unknown forward model. CaMB enforces monotonicity as a hard architectural inductive bias, constraining optimization to physically consistent mappings and enabling robust and stable operator estimation. We further integrate CaMB with a plug-and-play diffusion framework, proposing \textbf{CaMB-Diff}. Within this framework, the diffusion model serves as a powerful geometric prior for structural and semantic recovery, while CaMB explicitly models and corrects radiometric distortions through a physically grounded forward operator. Extensive experiments on a variety of zero-shot UDRC tasks, including low-light enhancement, low-field MRI enhancement, and HDR reconstruction, demonstrate that CaMB-Diff significantly outperforms state-of-the-art zero-shot baselines in terms of both signal fidelity and physical consistency. Moreover, we empirically validate the effectiveness of the proposed CaMB parameterization in accurately modeling the unknown forward operator.
Zero-shot Low-Field MRI Enhancement via Diffusion-Based Adaptive Contrast Transport
Mar 02, 2026Low-field (LF) magnetic resonance imaging (MRI) democratizes access to diagnostic imaging but is fundamentally limited by low signal-to-noise ratio and significant tissue contrast distortion due to field-dependent relaxation dynamics. Reconstructing high-field (HF) quality images from LF data is a blind inverse problem, severely challenged by the scarcity of paired training data and the unknown, non-linear contrast transformation operator. Existing zero-shot methods, which assume simplified linear degradation, often fail to recover authentic tissue contrast. In this paper, we propose DACT(Diffusion-Based Adaptive Contrast Transport), a novel zero-shot framework that restores HF-quality images without paired supervision. DACT synergizes a pre-trained HF diffusion prior to ensure anatomical fidelity with a physically-informed adaptive forward model. Specifically, we introduce a differentiable Sinkhorn optimal transport module that explicitly models and corrects the intensity distribution shift between LF and HF domains during the reverse diffusion process. This allows the framework to dynamically learn the intractable contrast mapping while preserving topological consistency. Extensive experiments on simulated and real clinical LF datasets demonstrate that DACT achieves state-of-the-art performance, yielding reconstructions with superior structural detail and correct tissue contrast.
Plug-and-Play Diffusion Meets ADMM: Dual-Variable Coupling for Robust Medical Image Reconstruction
Feb 26, 2026Plug-and-Play diffusion prior (PnPDP) frameworks have emerged as a powerful paradigm for solving imaging inverse problems by treating pretrained generative models as modular priors. However, we identify a critical flaw in prevailing PnP solvers (e.g., based on HQS or Proximal Gradient): they function as memoryless operators, updating estimates solely based on instantaneous gradients. This lack of historical tracking inevitably leads to non-vanishing steady-state bias, where the reconstruction fails to strictly satisfy physical measurements under heavy corruption. To resolve this, we propose Dual-Coupled PnP Diffusion, which restores the classical dual variable to provide integral feedback, theoretically guaranteeing asymptotic convergence to the exact data manifold. However, this rigorous geometric coupling introduces a secondary challenge: the accumulated dual residuals exhibit spectrally colored, structured artifacts that violate the Additive White Gaussian Noise (AWGN) assumption of diffusion priors, causing severe hallucinations. To bridge this gap, we introduce Spectral Homogenization (SH), a frequency-domain adaptation mechanism that modulates these structured residuals into statistically compliant pseudo-AWGN inputs. This effectively aligns the solver's rigorous optimization trajectory with the denoiser's valid statistical manifold. Extensive experiments on CT and MRI reconstruction demonstrate that our approach resolves the bias-hallucination trade-off, achieving state-of-the-art fidelity with significantly accelerated convergence.
Improving 2D Diffusion Models for 3D Medical Imaging with Inter-Slice Consistent Stochasticity
Feb 04, 20263D medical imaging is in high demand and essential for clinical diagnosis and scientific research. Currently, diffusion models (DMs) have become an effective tool for medical imaging reconstruction thanks to their ability to learn rich, high-quality data priors. However, learning the 3D data distribution with DMs in medical imaging is challenging, not only due to the difficulties in data collection but also because of the significant computational burden during model training. A common compromise is to train the DMs on 2D data priors and reconstruct stacked 2D slices to address 3D medical inverse problems. However, the intrinsic randomness of diffusion sampling causes severe inter-slice discontinuities of reconstructed 3D volumes. Existing methods often enforce continuity regularizations along the z-axis, which introduces sensitive hyper-parameters and may lead to over-smoothing results. In this work, we revisit the origin of stochasticity in diffusion sampling and introduce Inter-Slice Consistent Stochasticity (ISCS), a simple yet effective strategy that encourages interslice consistency during diffusion sampling. Our key idea is to control the consistency of stochastic noise components during diffusion sampling, thereby aligning their sampling trajectories without adding any new loss terms or optimization steps. Importantly, the proposed ISCS is plug-and-play and can be dropped into any 2D trained diffusion based 3D reconstruction pipeline without additional computational cost. Experiments on several medical imaging problems show that our method can effectively improve the performance of medical 3D imaging problems based on 2D diffusion models. Our findings suggest that controlling inter-slice stochasticity is a principled and practically attractive route toward high-fidelity 3D medical imaging with 2D diffusion priors. The code is available at: https://github.com/duchenhe/ISCS
Unsupervised Motion-Compensated Decomposition for Cardiac MRI Reconstruction via Neural Representation
Nov 17, 2025Cardiac magnetic resonance (CMR) imaging is widely used to characterize cardiac morphology and function. To accelerate CMR imaging, various methods have been proposed to recover high-quality spatiotemporal CMR images from highly undersampled k-t space data. However, current CMR reconstruction techniques either fail to achieve satisfactory image quality or are restricted by the scarcity of ground truth data, leading to limited applicability in clinical scenarios. In this work, we proposed MoCo-INR, a new unsupervised method that integrates implicit neural representations (INR) with the conventional motion-compensated (MoCo) framework. Using explicit motion modeling and the continuous prior of INRs, MoCo-INR can produce accurate cardiac motion decomposition and high-quality CMR reconstruction. Furthermore, we introduce a new INR network architecture tailored to the CMR problem, which significantly stabilizes model optimization. Experiments on retrospective (simulated) datasets demonstrate the superiority of MoCo-INR over state-of-the-art methods, achieving fast convergence and fine-detailed reconstructions at ultra-high acceleration factors (e.g., 20x in VISTA sampling). Additionally, evaluations on prospective (real-acquired) free-breathing CMR scans highlight the clinical practicality of MoCo-INR for real-time imaging. Several ablation studies further confirm the effectiveness of the critical components of MoCo-INR.
Low-Rank Augmented Implicit Neural Representation for Unsupervised High-Dimensional Quantitative MRI Reconstruction
Jun 10, 2025Quantitative magnetic resonance imaging (qMRI) provides tissue-specific parameters vital for clinical diagnosis. Although simultaneous multi-parametric qMRI (MP-qMRI) technologies enhance imaging efficiency, robustly reconstructing qMRI from highly undersampled, high-dimensional measurements remains a significant challenge. This difficulty arises primarily because current reconstruction methods that rely solely on a single prior or physics-informed model to solve the highly ill-posed inverse problem, which often leads to suboptimal results. To overcome this limitation, we propose LoREIN, a novel unsupervised and dual-prior-integrated framework for accelerated 3D MP-qMRI reconstruction. Technically, LoREIN incorporates both low-rank prior and continuity prior via low-rank representation (LRR) and implicit neural representation (INR), respectively, to enhance reconstruction fidelity. The powerful continuous representation of INR enables the estimation of optimal spatial bases within the low-rank subspace, facilitating high-fidelity reconstruction of weighted images. Simultaneously, the predicted multi-contrast weighted images provide essential structural and quantitative guidance, further enhancing the reconstruction accuracy of quantitative parameter maps. Furthermore, our work introduces a zero-shot learning paradigm with broad potential in complex spatiotemporal and high-dimensional image reconstruction tasks, further advancing the field of medical imaging.
SUFFICIENT: A scan-specific unsupervised deep learning framework for high-resolution 3D isotropic fetal brain MRI reconstruction
May 26, 2025High-quality 3D fetal brain MRI reconstruction from motion-corrupted 2D slices is crucial for clinical diagnosis. Reliable slice-to-volume registration (SVR)-based motion correction and super-resolution reconstruction (SRR) methods are essential. Deep learning (DL) has demonstrated potential in enhancing SVR and SRR when compared to conventional methods. However, it requires large-scale external training datasets, which are difficult to obtain for clinical fetal MRI. To address this issue, we propose an unsupervised iterative SVR-SRR framework for isotropic HR volume reconstruction. Specifically, SVR is formulated as a function mapping a 2D slice and a 3D target volume to a rigid transformation matrix, which aligns the slice to the underlying location in the target volume. The function is parameterized by a convolutional neural network, which is trained by minimizing the difference between the volume slicing at the predicted position and the input slice. In SRR, a decoding network embedded within a deep image prior framework is incorporated with a comprehensive image degradation model to produce the high-resolution (HR) volume. The deep image prior framework offers a local consistency prior to guide the reconstruction of HR volumes. By performing a forward degradation model, the HR volume is optimized by minimizing loss between predicted slices and the observed slices. Comprehensive experiments conducted on large-magnitude motion-corrupted simulation data and clinical data demonstrate the superior performance of the proposed framework over state-of-the-art fetal brain reconstruction frameworks.
JSover: Joint Spectrum Estimation and Multi-Material Decomposition from Single-Energy CT Projections
May 12, 2025Multi-material decomposition (MMD) enables quantitative reconstruction of tissue compositions in the human body, supporting a wide range of clinical applications. However, traditional MMD typically requires spectral CT scanners and pre-measured X-ray energy spectra, significantly limiting clinical applicability. To this end, various methods have been developed to perform MMD using conventional (i.e., single-energy, SE) CT systems, commonly referred to as SEMMD. Despite promising progress, most SEMMD methods follow a two-step image decomposition pipeline, which first reconstructs monochromatic CT images using algorithms such as FBP, and then performs decomposition on these images. The initial reconstruction step, however, neglects the energy-dependent attenuation of human tissues, introducing severe nonlinear beam hardening artifacts and noise into the subsequent decomposition. This paper proposes JSover, a fundamentally reformulated one-step SEMMD framework that jointly reconstructs multi-material compositions and estimates the energy spectrum directly from SECT projections. By explicitly incorporating physics-informed spectral priors into the SEMMD process, JSover accurately simulates a virtual spectral CT system from SE acquisitions, thereby improving the reliability and accuracy of decomposition. Furthermore, we introduce implicit neural representation (INR) as an unsupervised deep learning solver for representing the underlying material maps. The inductive bias of INR toward continuous image patterns constrains the solution space and further enhances estimation quality. Extensive experiments on both simulated and real CT datasets show that JSover outperforms state-of-the-art SEMMD methods in accuracy and computational efficiency.
Unsupervised Self-Prior Embedding Neural Representation for Iterative Sparse-View CT Reconstruction
Feb 08, 2025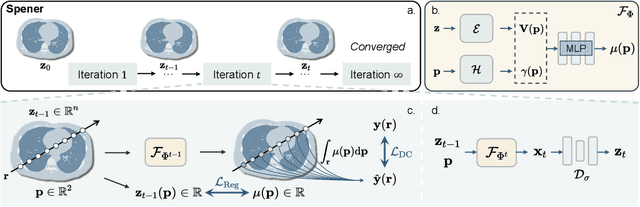
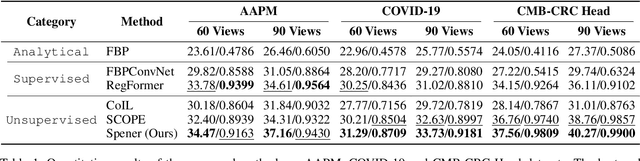
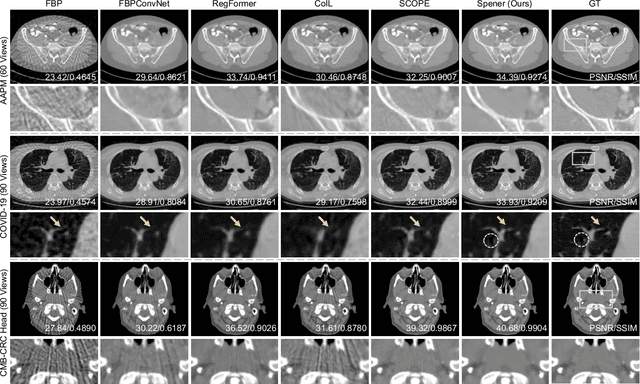
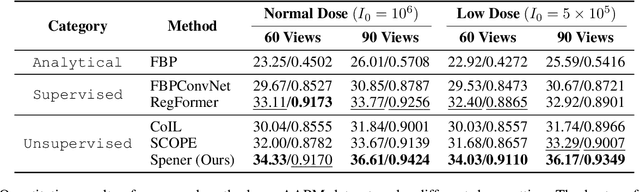
Emerging unsupervised implicit neural representation (INR) methods, such as NeRP, NeAT, and SCOPE, have shown great potential to address sparse-view computed tomography (SVCT) inverse problems. Although these INR-based methods perform well in relatively dense SVCT reconstructions, they struggle to achieve comparable performance to supervised methods in sparser SVCT scenarios. They are prone to being affected by noise, limiting their applicability in real clinical settings. Additionally, current methods have not fully explored the use of image domain priors for solving SVCsT inverse problems. In this work, we demonstrate that imperfect reconstruction results can provide effective image domain priors for INRs to enhance performance. To leverage this, we introduce Self-prior embedding neural representation (Spener), a novel unsupervised method for SVCT reconstruction that integrates iterative reconstruction algorithms. During each iteration, Spener extracts local image prior features from the previous iteration and embeds them to constrain the solution space. Experimental results on multiple CT datasets show that our unsupervised Spener method achieves performance comparable to supervised state-of-the-art (SOTA) methods on in-domain data while outperforming them on out-of-domain datasets. Moreover, Spener significantly improves the performance of INR-based methods in handling SVCT with noisy sinograms. Our code is available at https://github.com/MeijiTian/Spener.