 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Guided Dual-Arm Humanoid Robotic Disassembly of End-of-Life 18650 Lithium-ion Battery Packs
Jun 06, 2026The growing volume of retired lithium-ion battery packs from electric vehicles and portable electronics calls for automated disassembly that is safe, flexible, and selective down to the individual cell. Existing robotic systems, however, mostly assume known pack poses, external fixtures, or specialised tooling, leaving fixture-free cell-level disassembly under pose uncertainty largely unsolved. This paper presents a vision-guided dual-arm pipeline that disassembles a 21-cell 18650 pack from an arbitrary initial pose using only general-purpose parallel-jaw grippers, RGB-D sensing, and a pre-trained grasp detector. Pose uncertainty is absorbed by a learn-and-filter perception stack with discrete look-and-move wrist-camera corrections, while a mid-task support transfer between the two arms extends the effective workspace without any external clamp. The pipeline achieves an 8/10 end-to-end success rate, a cell-localisation root-mean-square error of $2.4$\,mm, and a mean cycle time of 6.0\,minutes per pack, providing a practical, fixture-free building block for industrial battery recycling.
Agentic Neuro-Symbolic Planning and Commissioning for Human-in-the-Loop Industrial Robotics with Digital Twins
Jun 06, 2026Flexible robotic automation requires systems that interpret operator intent, verify physical feasibility, and recover from execution failures across both the planning and execution stages. This paper proposes an agentic neuro-symbolic framework for human-in-the-loop industrial robotics, in which LLMs are used for tasks that require language understanding or contextual reasoning, while all verification, sequencing, and execution remain deterministic. The framework adapts the Planner-Generator-Evaluator (PGE) harness pattern from software engineering into a Specifier-Designer-Inspector (SDI) architecture for industrial robotics, combined with LangGraph-based dynamic routing for failure recovery. A two-tier recovery mechanism addresses structure-level replanning through context-aware orchestration and execution-level geometric failures through deterministic recovery skills. A Unity3D digital twin supports human inspection, modification, and re-verification prior to physical execution. Evaluated on natural-language commands across multiple difficulty levels against ten baselines, the proposed method achieves the highest task success. Ablation results confirm that structured command expansion, symbolic verification, selective LLM routing, and recovery skills are each individually necessary.
MindAlign: Bridging EEG, Vision, and Language for Zero-Shot Visual Decoding
May 23, 2026Visual decoding from brain signals is a key challenge at the intersection of computer vision and neuroscience, requiring methods that bridge neural representations and computational models of vision. We introduce a tri-modal contrastive framework for EEG-based visual decoding that aligns EEG, visual, and textual representations within a unified latent space. Our approach follows a two-stage design. First, we pre-train an EEG encoder via masked reconstruction on unlabeled trials, learning spatio-temporal regularities that transfer robustly to downstream tasks. Second, we jointly align EEG, image, and LLM-generated textual descriptions through contrastive learning, where text supervision acts as a semantic regularizer that injects linguistic structure into the shared space without overwhelming the primary EEG-image signal. The encoder integrates subject-specific adaptation, graph-attention over channels, and temporal-spatial convolutional embeddings. On the Things-EEG2 200-way zero-shot benchmark, our framework achieves 54.1% Top-1 and 83.4% Top-5 accuracy, substantially exceeding the strongest prior baseline (32.4% / 64.0%), with paired Wilcoxon tests confirming significance (p < 0.01) over all in-subject baselines. We validate generalization on Things-MEG. Analysis reveals that compact embedding geometries (CN-CLIP) outperform much larger backbones, and that decoding aligns with established neurophysiology of visual processing. This work is a critical step towards robust, semantically-grounded visual decoding from non-invasive temporal neural signals. The source code is publicly available in https://github.com/anon-eeg/eeg_image_decoding.
What Are We Actually Decoding? Source Attribution for Non-Invasive Brain-to-Language Retrieval
May 23, 2026In non-invasive neural language decoding, results can be inflated by sources that are not stimulus-evoked neural evidence: decoder priors, embedding-based metrics, and non-neural structural nuisances such as signal duration. The methodological challenge is therefore attribution: a reported gain is more informative when it can be traced to a specific source. We recast stimulus-locked MEG-to-audio retrieval as an auditing framework that separates apparent performance into three sources - structural shortcuts, window-level stimulus-locked evidence, and cross-window contextual aggregation - and provides a diagnostic for each. Signal-blind Gaussian noise reaches 66.3% Rank@1 (R@1) under variable-length decoding but collapses to near chance once fixed-duration windows and stimulus-identity splits are enforced, isolating structural leakage. Under these controls, fixed-window retrieval recovers measurable MEG-audio discriminability, while an oracle sentence-bucket diagnostic shows that 95.7% of Top-1 errors select the wrong sentence, localising the residual bottleneck to sentence-level competition. We audit this contextual source with Group Context Bias (GCB), an inference-time additive logit bias that pools sentence-consistent evidence across windows while leaving the base retrieval scores and candidate pool fixed. Used as a score-space intervention, GCB makes the contextual source measurable: R@1 shifts from 44% to 52% on Gwilliams and from 22% to 29% on MOUS under the same fixed setting. GCB is auditable under this design: its effect collapses under random-grouping perturbations and vanishes when local evidence is attenuated in MEG or is near chance in EEG, supporting its use as a controlled source-attribution intervention. These results suggest that brain-to-language performance should be source-attributed, not merely reported.
Bidirectional Cross-Modal Prompting for Event-Frame Asymmetric Stereo
Apr 16, 2026Conventional frame-based cameras capture rich contextual information but suffer from limited temporal resolution and motion blur in dynamic scenes. Event cameras offer an alternative visual representation with higher dynamic range free from such limitations. The complementary characteristics of the two modalities make event-frame asymmetric stereo promising for reliable 3D perception under fast motion and challenging illumination. However, the modality gap often leads to marginalization of domain-specific cues essential for cross-modal stereo matching. In this paper, we introduce Bi-CMPStereo, a novel bidirectional cross-modal prompting framework that fully exploits semantic and structural features from both domains for robust matching. Our approach learns finely aligned stereo representations within a target canonical space and integrates complementary representations by projecting each modality into both event and frame domains. Extensive experiments demonstrate that our approach significantly outperforms state-of-the-art methods in accuracy and generalization.
Shape-morphing programming of soft materials on complex geometries via neural operator
Jan 16, 2026Shape-morphing soft materials can enable diverse target morphologies through voxel-level material distribution design, offering significant potential for various applications. Despite progress in basic shape-morphing design with simple geometries, achieving advanced applications such as conformal implant deployment or aerodynamic morphing requires accurate and diverse morphing designs on complex geometries, which remains challenging. Here, we present a Spectral and Spatial Neural Operator (S2NO), which enables high-fidelity morphing prediction on complex geometries. S2NO effectively captures global and local morphing behaviours on irregular computational domains by integrating Laplacian eigenfunction encoding and spatial convolutions. Combining S2NO with evolutionary algorithms enables voxel-level optimisation of material distributions for shape morphing programming on various complex geometries, including irregular-boundary shapes, porous structures, and thin-walled structures. Furthermore, the neural operator's discretisation-invariant property enables super-resolution material distribution design, further expanding the diversity and complexity of morphing design. These advancements significantly improve the efficiency and capability of programming complex shape morphing.
CD-DPE: Dual-Prompt Expert Network based on Convolutional Dictionary Feature Decoupling for Multi-Contrast MRI Super-Resolution
Nov 18, 2025Multi-contrast magnetic resonance imaging (MRI) super-resolution intends to reconstruct high-resolution (HR) images from low-resolution (LR) scans by leveraging structural information present in HR reference images acquired with different contrasts. This technique enhances anatomical detail and soft tissue differentiation, which is vital for early diagnosis and clinical decision-making. However, inherent contrasts disparities between modalities pose fundamental challenges in effectively utilizing reference image textures to guide target image reconstruction, often resulting in suboptimal feature integration. To address this issue, we propose a dual-prompt expert network based on a convolutional dictionary feature decoupling (CD-DPE) strategy for multi-contrast MRI super-resolution. Specifically, we introduce an iterative convolutional dictionary feature decoupling module (CD-FDM) to separate features into cross-contrast and intra-contrast components, thereby reducing redundancy and interference. To fully integrate these features, a novel dual-prompt feature fusion expert module (DP-FFEM) is proposed. This module uses a frequency prompt to guide the selection of relevant reference features for incorporation into the target image, while an adaptive routing prompt determines the optimal method for fusing reference and target features to enhance reconstruction quality. Extensive experiments on public multi-contrast MRI datasets demonstrate that CD-DPE outperforms state-of-the-art methods in reconstructing fine details. Additionally, experiments on unseen datasets demonstrated that CD-DPE exhibits strong generalization capabilities.
Unsupervised Multi-Attention Meta Transformer for Rotating Machinery Fault Diagnosis
Sep 11, 2025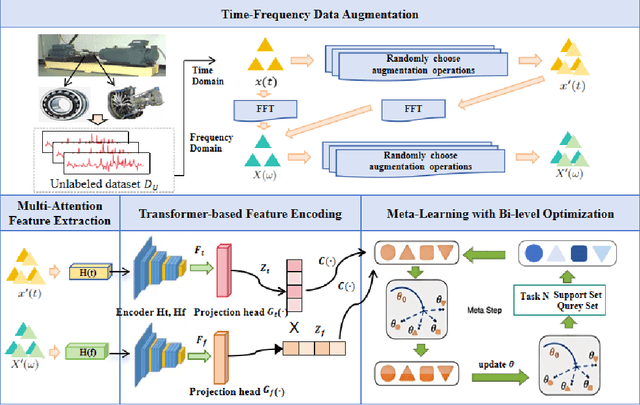

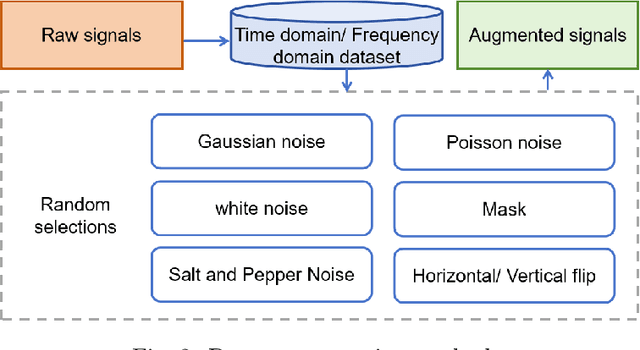
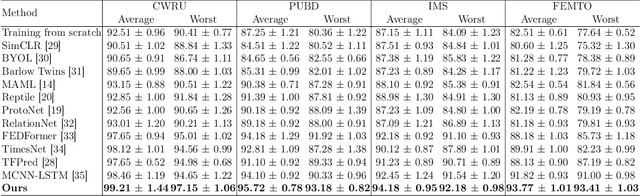
The intelligent fault diagnosis of rotating mechanical equipment usually requires a large amount of labeled sample data. However, in practical industrial applications, acquiring enough data is both challenging and expensive in terms of time and cost. Moreover, different types of rotating mechanical equipment with different unique mechanical properties, require separate training of diagnostic models for each case. To address the challenges of limited fault samples and the lack of generalizability in prediction models for practical engineering applications, we propose a Multi-Attention Meta Transformer method for few-shot unsupervised rotating machinery fault diagnosis (MMT-FD). This framework extracts potential fault representations from unlabeled data and demonstrates strong generalization capabilities, making it suitable for diagnosing faults across various types of mechanical equipment. The MMT-FD framework integrates a time-frequency domain encoder and a meta-learning generalization model. The time-frequency domain encoder predicts status representations generated through random augmentations in the time-frequency domain. These enhanced data are then fed into a meta-learning network for classification and generalization training, followed by fine-tuning using a limited amount of labeled data. The model is iteratively optimized using a small number of contrastive learning iterations, resulting in high efficiency. To validate the framework, we conducted experiments on a bearing fault dataset and rotor test bench data. The results demonstrate that the MMT-FD model achieves 99\% fault diagnosis accuracy with only 1\% of labeled sample data, exhibiting robust generalization capabilities.
SUFFICIENT: A scan-specific unsupervised deep learning framework for high-resolution 3D isotropic fetal brain MRI reconstruction
May 26, 2025High-quality 3D fetal brain MRI reconstruction from motion-corrupted 2D slices is crucial for clinical diagnosis. Reliable slice-to-volume registration (SVR)-based motion correction and super-resolution reconstruction (SRR) methods are essential. Deep learning (DL) has demonstrated potential in enhancing SVR and SRR when compared to conventional methods. However, it requires large-scale external training datasets, which are difficult to obtain for clinical fetal MRI. To address this issue, we propose an unsupervised iterative SVR-SRR framework for isotropic HR volume reconstruction. Specifically, SVR is formulated as a function mapping a 2D slice and a 3D target volume to a rigid transformation matrix, which aligns the slice to the underlying location in the target volume. The function is parameterized by a convolutional neural network, which is trained by minimizing the difference between the volume slicing at the predicted position and the input slice. In SRR, a decoding network embedded within a deep image prior framework is incorporated with a comprehensive image degradation model to produce the high-resolution (HR) volume. The deep image prior framework offers a local consistency prior to guide the reconstruction of HR volumes. By performing a forward degradation model, the HR volume is optimized by minimizing loss between predicted slices and the observed slices. Comprehensive experiments conducted on large-magnitude motion-corrupted simulation data and clinical data demonstrate the superior performance of the proposed framework over state-of-the-art fetal brain reconstruction frameworks.
GESH-Net: Graph-Enhanced Spherical Harmonic Convolutional Networks for Cortical Surface Registration
Oct 18, 2024Currently, cortical surface registration techniques based on classical methods have been well developed. However, a key issue with classical methods is that for each pair of images to be registered, it is necessary to search for the optimal transformation in the deformation space according to a specific optimization algorithm until the similarity measure function converges, which cannot meet the requirements of real-time and high-precision in medical image registration. Researching cortical surface registration based on deep learning models has become a new direction. But so far, there are still only a few studies on cortical surface image registration based on deep learning. Moreover, although deep learning methods theoretically have stronger representation capabilities, surpassing the most advanced classical methods in registration accuracy and distortion control remains a challenge. Therefore, to address this challenge, this paper constructs a deep learning model to study the technology of cortical surface image registration. The specific work is as follows: (1) An unsupervised cortical surface registration network based on a multi-scale cascaded structure is designed, and a convolution method based on spherical harmonic transformation is introduced to register cortical surface data. This solves the problem of scale-inflexibility of spherical feature transformation and optimizes the multi-scale registration process. (2)By integrating the attention mechanism, a graph-enhenced module is introduced into the registration network, using the graph attention module to help the network learn global features of cortical surface data, enhancing the learning ability of the network. The results show that the graph attention module effectively enhances the network's ability to extract global features, and its registration results have significant advantages over other methods.