 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring Operator Emotions from a Motion-Controlled Robotic Arm
Dec 09, 2025A remote robot operator's affective state can significantly impact the resulting robot's motions leading to unexpected consequences, even when the user follows protocol and performs permitted tasks. The recognition of a user operator's affective states in remote robot control scenarios is, however, underexplored. Current emotion recognition methods rely on reading the user's vital signs or body language, but the devices and user participation these measures require would add limitations to remote robot control. We demonstrate that the functional movements of a remote-controlled robotic avatar, which was not designed for emotional expression, can be used to infer the emotional state of the human operator via a machine-learning system. Specifically, our system achieved 83.3$\%$ accuracy in recognizing the user's emotional state expressed by robot movements, as a result of their hand motions. We discuss the implications of this system on prominent current and future remote robot operation and affective robotic contexts.
CD-DPE: Dual-Prompt Expert Network based on Convolutional Dictionary Feature Decoupling for Multi-Contrast MRI Super-Resolution
Nov 18, 2025Multi-contrast magnetic resonance imaging (MRI) super-resolution intends to reconstruct high-resolution (HR) images from low-resolution (LR) scans by leveraging structural information present in HR reference images acquired with different contrasts. This technique enhances anatomical detail and soft tissue differentiation, which is vital for early diagnosis and clinical decision-making. However, inherent contrasts disparities between modalities pose fundamental challenges in effectively utilizing reference image textures to guide target image reconstruction, often resulting in suboptimal feature integration. To address this issue, we propose a dual-prompt expert network based on a convolutional dictionary feature decoupling (CD-DPE) strategy for multi-contrast MRI super-resolution. Specifically, we introduce an iterative convolutional dictionary feature decoupling module (CD-FDM) to separate features into cross-contrast and intra-contrast components, thereby reducing redundancy and interference. To fully integrate these features, a novel dual-prompt feature fusion expert module (DP-FFEM) is proposed. This module uses a frequency prompt to guide the selection of relevant reference features for incorporation into the target image, while an adaptive routing prompt determines the optimal method for fusing reference and target features to enhance reconstruction quality. Extensive experiments on public multi-contrast MRI datasets demonstrate that CD-DPE outperforms state-of-the-art methods in reconstructing fine details. Additionally, experiments on unseen datasets demonstrated that CD-DPE exhibits strong generalization capabilities.
A Neuromorphic Incipient Slip Detection System using Papillae Morphology
Sep 11, 2025Detecting incipient slip enables early intervention to prevent object slippage and enhance robotic manipulation safety. However, deploying such systems on edge platforms remains challenging, particularly due to energy constraints. This work presents a neuromorphic tactile sensing system based on the NeuroTac sensor with an extruding papillae-based skin and a spiking convolutional neural network (SCNN) for slip-state classification. The SCNN model achieves 94.33% classification accuracy across three classes (no slip, incipient slip, and gross slip) in slip conditions induced by sensor motion. Under the dynamic gravity-induced slip validation conditions, after temporal smoothing of the SCNN's final-layer spike counts, the system detects incipient slip at least 360 ms prior to gross slip across all trials, consistently identifying incipient slip before gross slip occurs. These results demonstrate that this neuromorphic system has stable and responsive incipient slip detection capability.
Haptic-Based User Authentication for Tele-robotic System
Jun 17, 2025Tele-operated robots rely on real-time user behavior mapping for remote tasks, but ensuring secure authentication remains a challenge. Traditional methods, such as passwords and static biometrics, are vulnerable to spoofing and replay attacks, particularly in high-stakes, continuous interactions. This paper presents a novel anti-spoofing and anti-replay authentication approach that leverages distinctive user behavioral features extracted from haptic feedback during human-robot interactions. To evaluate our authentication approach, we collected a time-series force feedback dataset from 15 participants performing seven distinct tasks. We then developed a transformer-based deep learning model to extract temporal features from the haptic signals. By analyzing user-specific force dynamics, our method achieves over 90 percent accuracy in both user identification and task classification, demonstrating its potential for enhancing access control and identity assurance in tele-robotic systems.
AdaFuse: Adaptive Medical Image Fusion Based on Spatial-Frequential Cross Attention
Oct 24, 2023



Multi-modal medical image fusion is essential for the precise clinical diagnosis and surgical navigation since it can merge the complementary information in multi-modalities into a single image. The quality of the fused image depends on the extracted single modality features as well as the fusion rules for multi-modal information. Existing deep learning-based fusion methods can fully exploit the semantic features of each modality, they cannot distinguish the effective low and high frequency information of each modality and fuse them adaptively. To address this issue, we propose AdaFuse, in which multimodal image information is fused adaptively through frequency-guided attention mechanism based on Fourier transform. Specifically, we propose the cross-attention fusion (CAF) block, which adaptively fuses features of two modalities in the spatial and frequency domains by exchanging key and query values, and then calculates the cross-attention scores between the spatial and frequency features to further guide the spatial-frequential information fusion. The CAF block enhances the high-frequency features of the different modalities so that the details in the fused images can be retained. Moreover, we design a novel loss function composed of structure loss and content loss to preserve both low and high frequency information. Extensive comparison experiments on several datasets demonstrate that the proposed method outperforms state-of-the-art methods in terms of both visual quality and quantitative metrics. The ablation experiments also validate the effectiveness of the proposed loss and fusion strategy.
CNN-Based Invertible Wavelet Scattering for the Investigation of Diffusion Properties of the In Vivo Human Heart in Diffusion Tensor Imaging
Dec 17, 2019
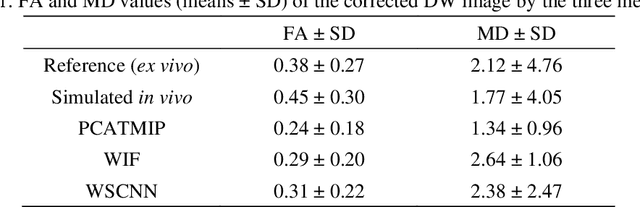
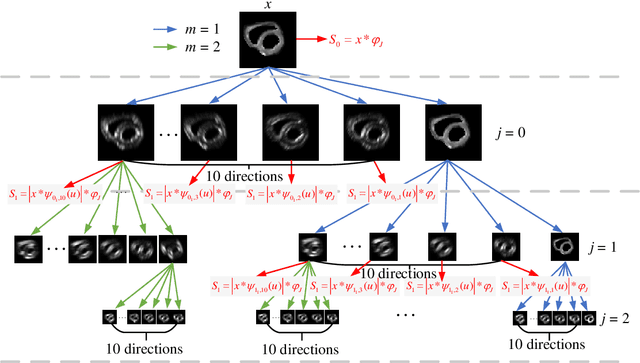

In vivo diffusion tensor imaging (DTI) is a promising technique to investigate noninvasively the fiber structures of the in vivo human heart. However, signal loss due to motions remains a persistent problem in in vivo cardiac DTI. We propose a novel motion-compensation method for investigating in vivo myocardium structures in DTI with free-breathing acquisitions. The method is based on an invertible Wavelet Scattering achieved by means of Convolutional Neural Network (WSCNN). It consists of first extracting translation-invariant wavelet scattering features from DW images acquired at different trigger delays and then mapping the fused scattering features into motion-compensated spatial DW images by performing an inverse wavelet scattering transform achieved using CNN. The results on both simulated and acquired in vivo cardiac DW images showed that the proposed WSCNN method effectively compensates for motion-induced signal loss and produces in vivo cardiac DW images with better quality and more coherent fiber structures with respect to existing methods, which makes it an interesting method for measuring correctly the diffusion properties of the in vivo human heart in DTI under free breathing.
A Model of Double Descent for High-dimensional Binary Linear Classification
Nov 13, 2019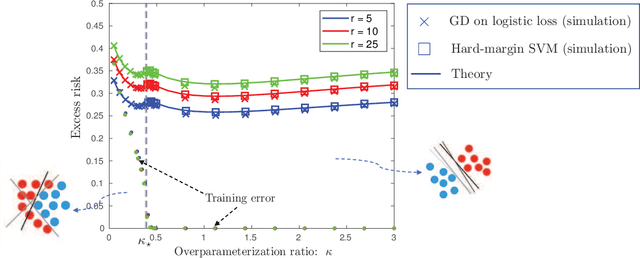
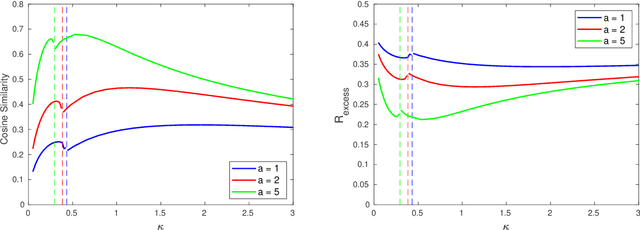

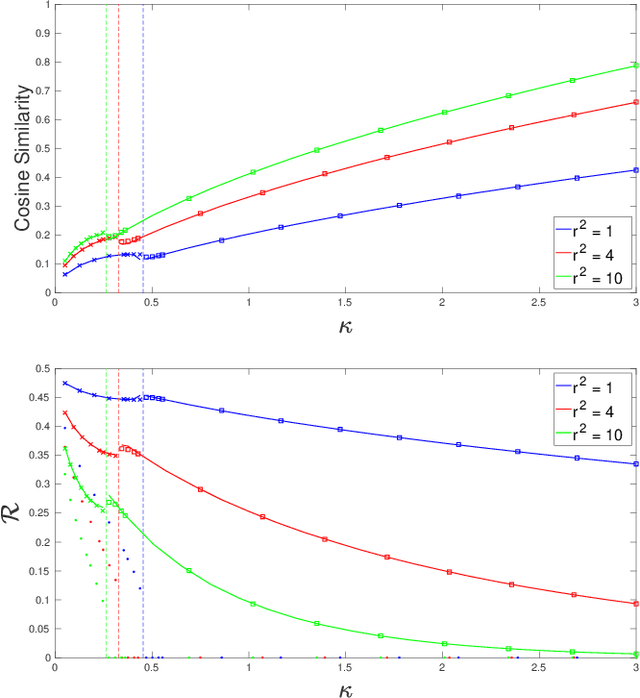
We consider a model for logistic regression where only a subset of features of size $p$ is used for training a linear classifier over $n$ training samples. The classifier is obtained by running gradient-descent (GD) on the logistic-loss. For this model, we investigate the dependence of the generalization error on the overparameterization ratio $\kappa=p/n$. First, building on known deterministic results on convergence properties of the GD, we uncover a phase-transition phenomenon for the case of Gaussian regressors: the generalization error of GD is the same as that of the maximum-likelihood (ML) solution when $\kappa<\kappa_\star$, and that of the max-margin (SVM) solution when $\kappa>\kappa_\star$. Next, using the convex Gaussian min-max theorem (CGMT), we sharply characterize the performance of both the ML and SVM solutions. Combining these results, we obtain curves that explicitly characterize the generalization error of GD for varying values of $\kappa$. The numerical results validate the theoretical predictions and unveil double-descent phenomena that complement similar recent observations in linear regression settings.
Glioma Grade Predictions using Scattering Wavelet Transform-Based Radiomics
May 23, 2019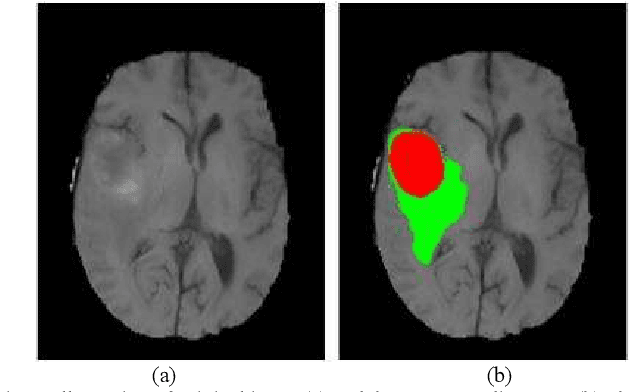
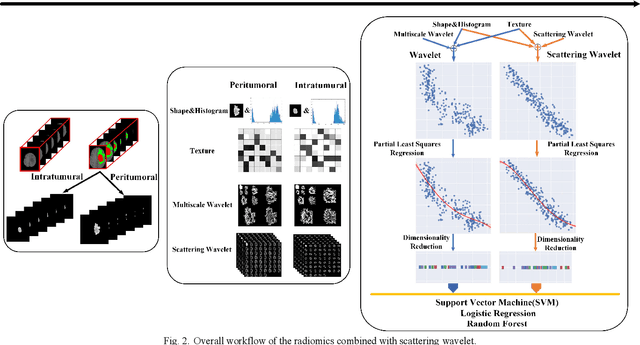
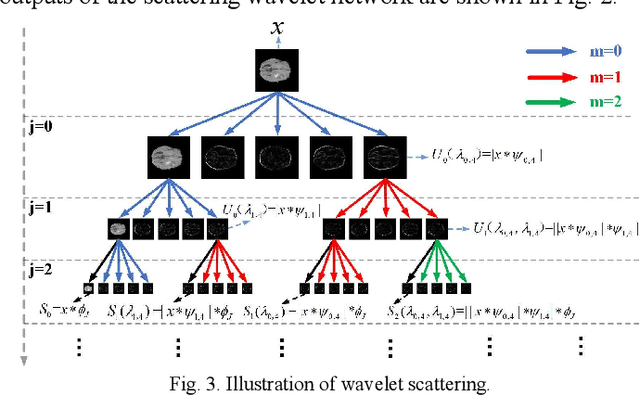
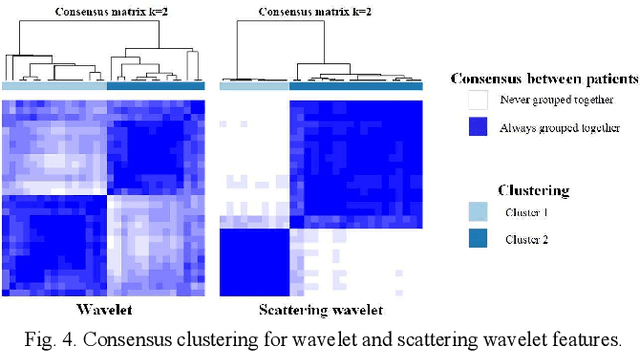
Glioma grading before the surgery is very critical for the prognosis prediction and treatment plan making. In this paper, we present a novel scattering wavelet-based radiomics method to predict noninvasively and accurately the glioma grades. The multimodal magnetic resonance images of 285 patients were used, with the intratumoral and peritumoral regions well labeled. The wavelet scattering-based features and traditional radiomics features were firstly extracted from both intratumoral and peritumoral regions respectively. The support vector machine (SVM), logistic regression (LR) and random forest (RF) were then trained with 5-fold cross validation to predict the glioma grades. The prediction obtained with different features was finally evaluated in terms of quantitative metrics. The area under the receiver operating characteristic curve (AUC) of glioma grade prediction based on scattering wavelet features was up to 0.99 when considering both intratumoral and peritumoral features in multimodal images, which increases by about 17% compared to traditional radiomics. Such results shown that the local invariant features extracted from the scattering wavelet transform allows improving the prediction accuracy for glioma grading. In addition, the features extracted from peritumoral regions further increases the accuracy of glioma grading.